
Heim >Technologie-Peripheriegeräte >KI >Unterstützt die Synthese einminütiger hochauflösender Videos. UniAnimate schlug ein neues Framework für die Erzeugung menschlicher Tanzvideos vor.
Unterstützt die Synthese einminütiger hochauflösender Videos. UniAnimate schlug ein neues Framework für die Erzeugung menschlicher Tanzvideos vor.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-09 11:10:581124Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

Papieradresse: https://arxiv.org/abs/2406.01188 Projekthomepage: https://unianimate.github.io/

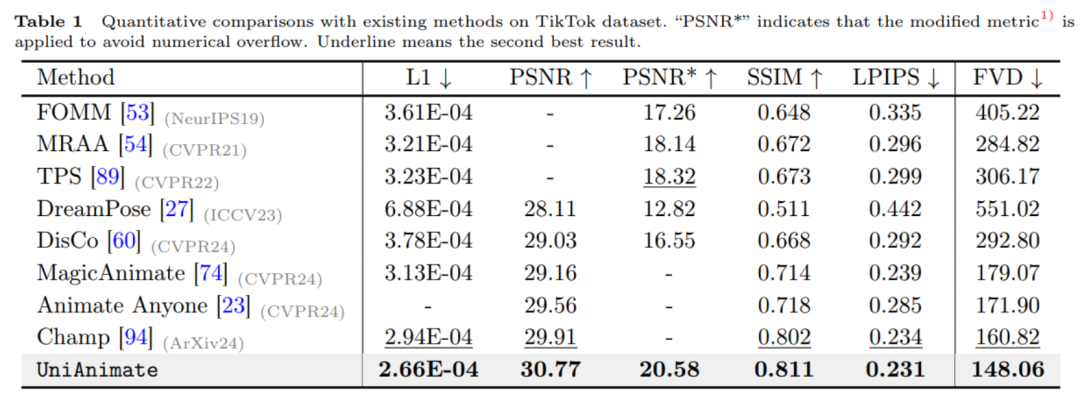
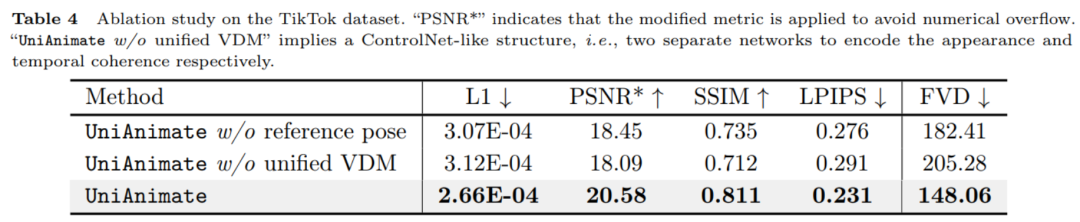
Keine Notwendigkeit für zusätzliche Referenznetzwerke: Das UniAnimate-Framework eliminiert die Abhängigkeit von zusätzlichen Referenznetzwerken durch ein einheitliches Videodiffusionsmodell, wodurch Trainingsschwierigkeiten und Modellnummern reduziert werden von Parametern. Führt die Posenkarte des Referenzbildes als zusätzliche Referenzbedingung ein, die das Netzwerk dazu fördert, die Entsprechung zwischen der Referenzpose und der Zielpose zu lernen und eine gute scheinbare Ausrichtung zu erreichen. Erstellen Sie Videos mit langen Sequenzen innerhalb eines einheitlichen Rahmens: Durch das Hinzufügen eines einheitlichen Rauscheingangs ist UniAnimate in der Lage, Langzeitvideos innerhalb eines Frames zu generieren, ohne den Zeitbeschränkungen herkömmlicher Methoden mehr zu unterliegen. Hohe Konsistenz: Das UniAnimate-Framework sorgt für einen reibungslosen Übergangseffekt des generierten Videos, indem es iterativ das erste Bild als Bedingung für die Generierung nachfolgender Bilder verwendet, wodurch das Video konsistenter und kohärenter im Erscheinungsbild wird. Diese Strategie ermöglicht es Benutzern auch, mehrere Videoclips zu generieren und das letzte Bild des Clips mit guten Ergebnissen als erstes Bild des nächsten generierten Clips auszuwählen, wodurch es für Benutzer einfacher wird, mit dem Modell zu interagieren und die Generierungsergebnisse nach Bedarf anzupassen. Wenn jedoch lange Videos mit der Schiebefensterstrategie der Überlappung früherer Zeitreihen erstellt werden, kann keine Segmentauswahl durchgeführt werden, da jedes Video in jedem Schritt des Diffusionsprozesses miteinander gekoppelt ist.












Das obige ist der detaillierte Inhalt vonUnterstützt die Synthese einminütiger hochauflösender Videos. UniAnimate schlug ein neues Framework für die Erzeugung menschlicher Tanzvideos vor.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Vorheriger Artikel:Ein geschmeidigerer Regelalgorithmus als PID und Carnegie Mellon UniversityNächster Artikel:Ein geschmeidigerer Regelalgorithmus als PID und Carnegie Mellon University
In Verbindung stehende Artikel
Mehr sehen- Anwendung vertrauenswürdiger Computertechnologie im Bereich der industriellen Sicherheit
- Das Ministerium für Industrie und Informationstechnologie kündigte an: Beschleunigung der Entwicklung der Gehirn-Computer-Schnittstellenindustrie
- Die MoDa-Community bringt das KI-Videogenerierungstool Live Portait auf den Markt, das Fotos mit einem Klick zum Sprechen bringen kann
- Das erste Weltmodell zur Erzeugung autonomer Fahrszenen mit mehreren Ansichten | DrivingDiffusion: Neue Ideen für BEV-Daten und Simulation
- Roboterindustrie: das nächste heiße Feld im KI-Zeitalter, eine der neun großen Industrien der Zukunft!