
Heim >Technologie-Peripheriegeräte >KI >Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-07 12:05:271240Durchsuche
1. Vorwort
In den letzten Jahren hat sich YOLOs aufgrund seines effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum dominierenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus.
In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. Zu diesem Zweck schlagen wir zunächst eine konsistente doppelte Zuweisung für das NMS-freie Training von YOLOs vor, die gleichzeitig wettbewerbsfähige Leistung und geringe Inferenzlatenz bringt. Darüber hinaus wird auch die auf Gesamteffizienz und Genauigkeit basierende Modellentwurfsstrategie von YOLO vorgestellt.
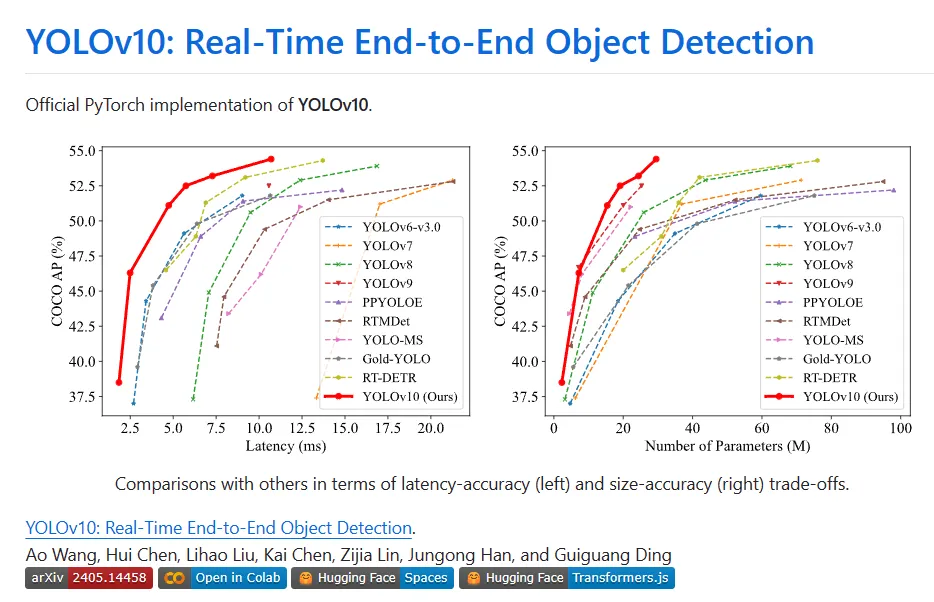
Verschiedene Komponenten von YOLO wurden im Hinblick auf die Verbesserung von Effizienz und Genauigkeit, die erhebliche Reduzierung des Rechenaufwands und die Verbesserung der Funktionen vollständig optimiert. Das Ergebnis der Arbeit ist eine neue Generation der YOLO-Serie zur End-to-End-Zielerkennung in Echtzeit, genannt YOLOv10. Umfangreiche Experimente zeigen, dass YOLOv10 in verschiedenen Modellmaßstäben modernste Leistung und Effizienz erreicht. Beispielsweise ist YOLOv10-Sis1.8 unter einem ähnlichen AP auf COCO 1,8-mal schneller als RT-DETR-R18, und die Anzahl der gleichzeitig gemeinsam genutzten Parameter und FLOPs beträgt 2,8-mal. Im Vergleich zu YOLOv9-C weist YOLOv10-B bei gleicher Leistung eine Reduzierung der Latenz um 46 % und eine Reduzierung der Parameter um 25 % auf.
II. Hintergrund
Die Echtzeit-Objekterkennung war schon immer ein Forschungsschwerpunkt im Bereich Computer Vision. Ihr Zweck ist die genaue Vorhersage der Kategorie und Position von Objekten in Bildern mit geringer Latenz . Es wird häufig in verschiedenen praktischen Anwendungen eingesetzt, darunter autonomes Fahren, Roboternavigation und Objektverfolgung. In den letzten Jahren haben sich Forscher auf die Entwicklung von CNN-basierten Objektdetektoren konzentriert, um eine Echtzeiterkennung zu erreichen. Echtzeit-Objektdetektoren können in zwei Kategorien unterteilt werden: einstufige Detektoren und zweistufige Detektoren. Einstufige Detektoren treffen dichte Vorhersagen direkt auf dem Eingabebild, während zweistufige Detektoren zunächst Kandidatenfelder generieren und dann eine Klassifizierung und Standortregression für diese Kandidatenfelder durchführen.
Unter ihnen erfreuen sich YOLOs aufgrund ihrer cleveren Balance zwischen Leistung und Effizienz immer größerer Beliebtheit. Die Erkennungspipeline von YOLO besteht aus zwei Teilen: Modellvorwärtsverarbeitung und NMS-Nachverarbeitung. Allerdings weisen beide Methoden immer noch Mängel auf, was zu einer suboptimalen Genauigkeit und Latenzgrenzen führt. Insbesondere wendet YOLO während des Trainings normalerweise eine Eins-zu-Viele-Label-Zuweisungsstrategie an, bei der ein grundlegendes Implementierungsobjekt mehreren Beispielbüchern entspricht. Obwohl dieser Ansatz eine überlegene Leistung liefert, muss das NMS während der Inferenz die beste positive Vorhersage auswählen. Dies verlangsamt die Inferenz und macht die Leistung empfindlich gegenüber den Hyperparametern von NMS, wodurch YOLO daran gehindert wird, eine optimale End-to-End-Bereitstellung zu erreichen. Eine Möglichkeit, dieses Problem zu lösen, besteht darin, die kürzlich eingeführte End-to-End-DETR-Architektur zu übernehmen. RT-DETR bietet beispielsweise eine effiziente hybride Encoder- und Abfrageauswahl mit minimaler Unsicherheit und drängt DETR in Echtzeitanwendungen. Allerdings behindert die dem Einsatz von DETR inhärente Komplexität die Fähigkeit, ein optimales Gleichgewicht zwischen Genauigkeit und Geschwindigkeit zu erreichen. Eine weitere Linie untersucht die End-to-End-Erkennung von CNN-basierten Detektoren, die typischerweise eine Eins-zu-Eins-Zuweisungsstrategie verwenden, um redundante Vorhersagen zu unterdrücken.
Allerdings verursachen sie häufig zusätzlichen Inferenzaufwand oder erzielen eine suboptimale Leistung. Darüber hinaus bleibt das Design der Modellarchitektur eine grundlegende Herausforderung für YOLO, die erhebliche Auswirkungen auf Genauigkeit und Geschwindigkeit hat. Um effizientere und effektivere Modellarchitekturen zu erreichen, haben Forscher verschiedene Entwurfsstrategien untersucht. Um die Funktionen zur Merkmalsextraktion zu verbessern, werden verschiedene Hauptrecheneinheiten für das Backbone bereitgestellt, darunter DarkNet, CSPNet, EfficientRep und ELAN. Für den Hals werden PAN, BiC, GD, RepGFPN usw. untersucht, um die Multiskalen-Feature-Fusion zu verbessern. Darüber hinaus werden Modellskalierungsstrategien und Reparametrisierungstechniken untersucht. Obwohl diese Bemühungen erhebliche Fortschritte gemacht haben, gibt es immer noch Raum für eine umfassende Untersuchung der verschiedenen Komponenten in YOLO unter dem Gesichtspunkt der Effizienz und Genauigkeit. Daher führt die daraus resultierende Möglichkeit, das Modell einzuschränken, auch zu einer unterschiedlichen Leistung, sodass ausreichend Raum für Genauigkeitsverbesserungen bleibt.
3. Neue Technologie
Konsequente Doppelaufgaben für NMS-freies Training
Während des Trainings verwenden YOLOs normalerweise TAL, um pro Instanz mehrere positive Proben zuzuweisen. Die Einführung der Eins-zu-viele-Zuweisung generiert umfangreiche Überwachungssignale, die zur Optimierung und Erzielung einer überlegenen Leistung beitragen. Allerdings muss sich YOLO auf die NMS-Nachbearbeitung verlassen, was zu einer unbefriedigenden Effizienz der Bereitstellungsinferenz führt. Während frühere Arbeiten Eins-zu-Eins-Matching zur Unterdrückung redundanter Vorhersagen untersuchten, führten sie häufig zu zusätzlichem Inferenzaufwand oder führten zu einer suboptimalen Leistung. In dieser Arbeit stellt YOLO eine NMS-freie Trainingsstrategie mit Dual-Label-Zuweisung und konsistenten Matching-Metriken bereit und erreicht so eine hohe Effizienz und Wettbewerbsleistung.
- Dual-Label-Zuweisungen
Im Gegensatz zu Eins-zu-Viele-Zuweisungen weist der Eins-zu-eins-Abgleich jeder Grundwahrheit nur eine Vorhersage zu, wodurch eine Nachbearbeitung durch NMS vermieden wird . Dies führt jedoch zu einer schlechten Überwachung, was zu einer suboptimalen Genauigkeit und Konvergenzgeschwindigkeit führt. Glücklicherweise kann dieser Mangel durch eine Eins-zu-viele-Zuteilung behoben werden. Um dies zu erreichen, führt YOLO die Dual-Label-Zuweisung ein, um das Beste aus beiden Strategien zu kombinieren. Genauer gesagt, wie in Abbildung (a) unten gezeigt.
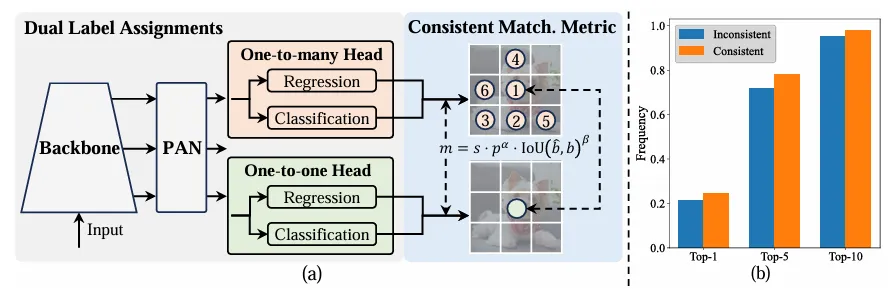
Wir stellen einen weiteren Eins-zu-Eins-Header für YOLO vor. Er behält die gleiche Struktur und verfolgt die gleichen Optimierungsziele wie der ursprüngliche Eins-zu-viele-Zweig, verwendet jedoch einen Eins-zu-eins-Abgleich, um Etikettenzuweisungen zu erhalten. Während des Trainingsprozesses werden die beiden Köpfe zusammen mit dem Modell optimiert, sodass Wirbelsäule und Nacken die umfassende Aufsicht durch Eins-zu-Viele-Aufgaben genießen können. Während der Inferenz wird der Eins-zu-Viele-Header verworfen und der Eins-zu-Eins-Header für die Vorhersage verwendet. Dadurch kann YOLO durchgängig bereitgestellt werden, ohne dass zusätzliche Inferenzkosten anfallen. Darüber hinaus wird beim Eins-zu-Eins-Matching die vorherige Wahl übernommen, wodurch die gleiche Leistung wie beim ungarischen Matching mit weniger zusätzlicher Trainingszeit erreicht wird.
- Konsistente Matching-Metrik
Während des Zuordnungsprozesses verwenden sowohl Eins-zu-eins- als auch Eins-zu-viele-Methoden eine Metrik, um den Grad der Konsistenz zwischen Vorhersagen und Instanzen quantitativ zu bewerten. Um einen vorhersagebewussten Abgleich zweier Zweige zu erreichen, wird eine einheitliche Matching-Metrik verwendet:
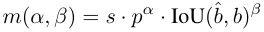
Bei der Dual-Label-Zuweisung liefern Eins-zu-viele-Zweige umfangreichere Überwachungssignale als Eins-zu-eins-Zweige. Wenn die Überwachung von Eins-zu-Eins-Headern mit der Überwachung von Eins-zu-Viele-Headern koordiniert werden kann, können Eins-zu-Eins-Header intuitiv in Richtung einer Eins-zu-Viele-Header-Optimierung optimiert werden. Daher können Eins-zu-eins-Köpfe eine verbesserte Probenqualität während der Inferenz liefern, was zu einer besseren Leistung führt. Hierzu wird zunächst die Regulierungslücke zwischen beiden analysiert. Aufgrund der Zufälligkeit im Trainingsprozess führt das Starten der Inspektion mit zwei Köpfen, die mit denselben Werten initialisiert wurden und dieselben Vorhersagen erzeugen, d. h. ein Eins-zu-eins-Kopf und ein Eins-zu-viele-Kopf, zu denselben Ergebnissen für jede Vorhersage Instanzpaar p und IoU. Beachten Sie die Regressionsziele für beide Zweige.
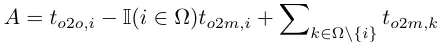
Wenn to2m, i = u*, erreicht es den Minimalwert, das heißt, i ist die beste positive Stichprobe in Ω, wie in (a) oben gezeigt. Um dies zu erreichen, werden konsistente Matching-Metriken vorgeschlagen, nämlich αo2o=r·αo2m und βo2o=r·βo2m, was mo2o=mro2m bedeutet. Daher ist die beste positive Probe für einen Eins-zu-Viele-Kopf auch die beste Probe für einen Eins-zu-Eins-Kopf. Dadurch können beide Köpfe konsequent und harmonisch optimiert werden. Der Einfachheit halber wird standardmäßig r=1 verwendet, d. h. αo2o=αo2m und βo2o=βo2m. Um die verbesserte überwachte Ausrichtung zu überprüfen, wird nach dem Training die Anzahl der Eins-zu-eins-Übereinstimmungspaare innerhalb der ersten 1/5/10 der Eins-zu-viele-Ergebnisse berechnet. Wie in (b) oben gezeigt, wird die Ausrichtung durch die konsistente Matching-Methode verbessert.
Aufgrund des begrenzten Platzes ist eine wichtige Neuerung von YOLOv10 die Einführung einer Dual-Label-Zuweisungsstrategie. Die Kernidee besteht darin, Eins-zu-Viele-Erkennungsköpfe zu verwenden, um während der Trainingsphase mehr positive Proben bereitzustellen und das Modell anzureichern . Training; in der Inferenzphase wird die Gradientenkürzung verwendet, um auf Eins-zu-Eins-Erkennungsköpfe umzuschalten. Dadurch entfällt die Notwendigkeit einer NMS-Nachbearbeitung, wodurch der Inferenzaufwand bei gleichbleibender Leistung verringert wird. Das Prinzip ist eigentlich nicht schwer, man kann sich den Code ansehen, um es zu verstehen:
#https://github.com/THU-MIG/yolov10/blob/main/ultralytics/nn/modules/head.pyclass v10Detect(Detect):max_det = -1def __init__(self, nc=80, ch=()):super().__init__(nc, ch)c3 = max(ch[0], min(self.nc, 100))# channelsself.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(Conv(x, x, 3, g=x), Conv(x, c3, 1)), \ nn.Sequential(Conv(c3, c3, 3, g=c3), Conv(c3, c3, 1)), \nn.Conv2d(c3, self.nc, 1)) for i, x in enumerate(ch))self.one2one_cv2 = copy.deepcopy(self.cv2)self.one2one_cv3 = copy.deepcopy(self.cv3)def forward(self, x):one2one = self.forward_feat([xi.detach() for xi in x], self.one2one_cv2, self.one2one_cv3)if not self.export:one2many = super().forward(x)if not self.training:one2one = self.inference(one2one)if not self.export:return {'one2many': one2many, 'one2one': one2one}else:assert(self.max_det != -1)boxes, scores, labels = ops.v10postprocess(one2one.permute(0, 2, 1), self.max_det, self.nc)return torch.cat([boxes, scores.unsqueeze(-1), labels.unsqueeze(-1)], dim=-1)else:return {'one2many': one2many, 'one2one': one2one}def bias_init(self):super().bias_init()'''Initialize Detect() biases, WARNING: requires stride availability.'''m = self# self.model[-1]# Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum())# nominal class frequencyfor a, b, s in zip(m.one2one_cv2, m.one2one_cv3, m.stride):# froma[-1].bias.data[:] = 1.0# boxb[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2)# cls (.01 objects, 80 classes, 640 img)Holistic Efficiency-Accuracy Driven Model Design
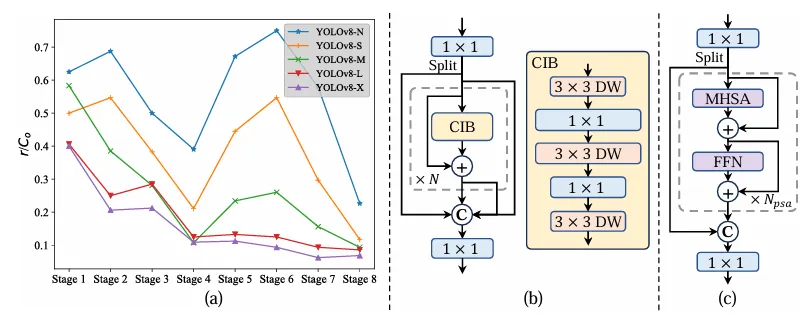
架构改进:
- Backbone & Neck:使用了先进的结构如 CSPNet 作为骨干网络,和 PAN 作为颈部网络,优化了特征提取和多尺度特征融合。
- 大卷积核与分区自注意力:这些技术用于增强模型从大范围上下文中学习的能力,提高检测准确性而不显著增加计算成本。
- 整体效率:引入空间-通道解耦下采样和基于秩引导的模块设计,减少计算冗余,提高整体模型效率。
四、实验
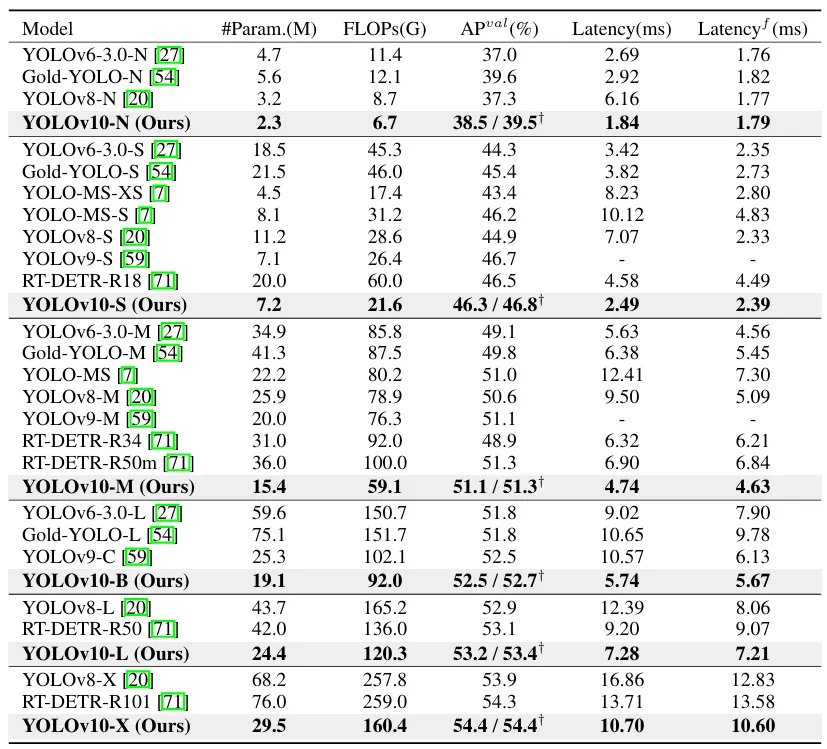
与最先进的比较。潜伏性是通过官方预训练的模型来测量的。潜在的基因测试在具有前处理的模型的前处理中保持了潜在性。†是指YOLOv10的结果,其本身对许多训练NMS来说都是如此。以下是所有结果,无需添加先进的训练技术,如知识提取或PGI或公平比较:

五、部署测试
首先,按照官方主页将环境配置好,注意这里 python 版本至少需要 3.9 及以上,torch 版本可以根据自己本地机器安装合适的版本,默认下载的是 2.0.1:
conda create -n yolov10 pythnotallow=3.9conda activate yolov10pip install -r requirements.txtpip install -e .
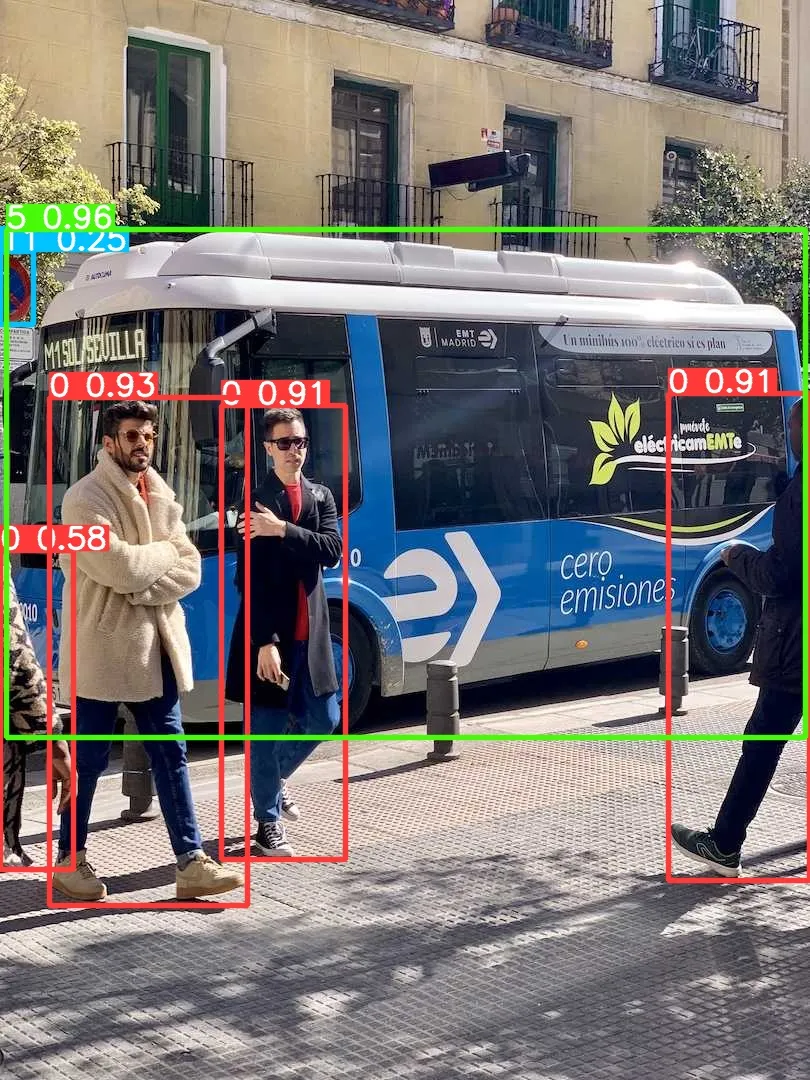
安装完成之后,我们简单执行下推理命令测试下效果:
yolo predict model=yolov10s.pt source=ultralytics/assets/bus.jpg
让我们尝试部署一下,譬如先导出个 onnx 模型出来看看:
yolo export model=yolov10s.pt format=onnx opset=13 simplify
好了,接下来通过执行 pip install netron 安装个可视化工具来看看导出的节点信息:
# run python fisrtimport netronnetron.start('/path/to/yolov10s.onnx')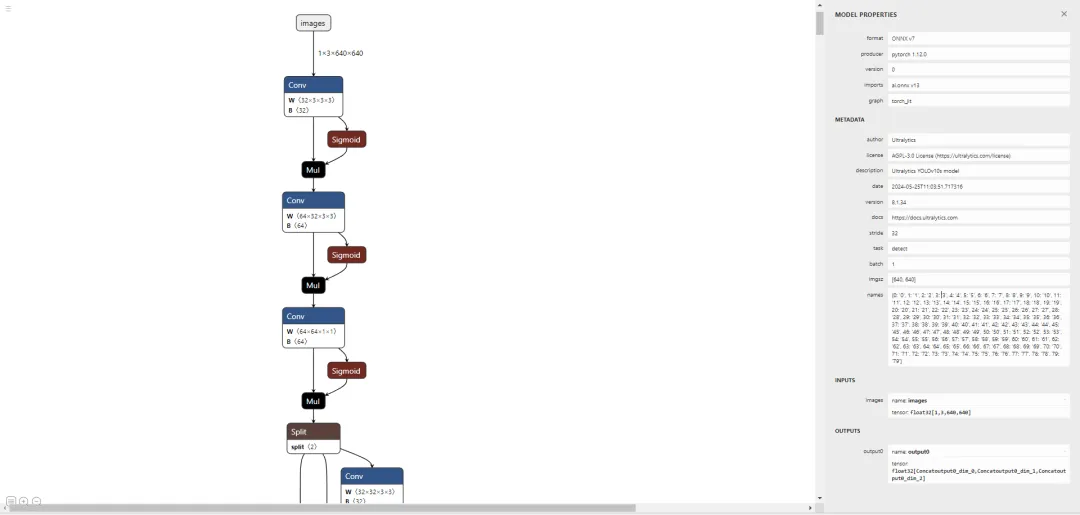
先直接通过 Ultralytics 框架预测一个测试下能否正常推理:
yolo predict model=yolov10s.onnx source=ultralytics/assets/bus.jpg

大家可以对比下上面的运行结果,可以看出 performance 是有些许的下降。问题不大,让我们基于 onnxruntime 写一个简单的推理脚本,代码地址如下,有兴趣的可以自行查看:
# 推理脚本https://github.com/CVHub520/X-AnyLabeling/blob/main/tools/export_yolov10_onnx.py# onnx 模型权重https://github.com/CVHub520/X-AnyLabeling/releases/tag/v2.3.6

Das obige ist der detaillierte Inhalt vonYolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie stellt man ein PHP-Projekt unter Linux bereit?
- Nginx stellt Front-End- und Back-End-Trennungsdienste und Konfigurationsanweisungen bereit
- Funktionen des TCP/IP-Vierschichtmodells
- Welche sind die am häufigsten verwendeten logischen Modelle in Datenbanken?
- So stellen Sie ein Nginx-Projekt in einem externen Netzwerk bereit