
Heim >Technologie-Peripheriegeräte >KI >Um die Nutzung optischer Datensätze zu verbessern, schlug das Tianda-Team ein KI-Modell vor, um den spektralen Vorhersageeffekt zu verbessern
Um die Nutzung optischer Datensätze zu verbessern, schlug das Tianda-Team ein KI-Modell vor, um den spektralen Vorhersageeffekt zu verbessern

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-06 12:09:28746Durchsuche

Herausgeber |. Dead Leaf Butterfly
Kürzlich berichteten das Team von außerordentlichem Professor Wu Liang und Akademiker Yao Jianquan vom Institut für Laser und Optoelektronik der Tianjin-Universität und das Team von Professor Xiong Deyi vom Labor für natürliche Sprachverarbeitung Lernmodell, das zusätzliche Mehrfrequenzeingaben für Lösungen verwendet, um die Leistung der Spektralvorhersage zu verbessern. Dieses Schema kann die Genauigkeit der Spektralvorhersage durch die Verwendung von Mehrfrequenz-Eingangsdaten verbessern. Darüber hinaus kann diese Lösung auch Rauschstörungen im Spektrumvorhersageprozess reduzieren und so den Vorhersageeffekt verbessern.
Diese Lösung kann die Nutzung vorhandener optischer Datensätze verbessern und den Vorhersageeffekt der spektralen Reaktion entsprechend der Metaoberflächenstruktur verbessern, ohne die Trainingskosten zu erhöhen.
Die relevanten Forschungsergebnisse trugen den Titel „Verbesserte Spektrumvorhersage mithilfe von Deep-Learning-Modellen mit ergänzenden Mehrfrequenzeingaben“ und wurden am 16. Mai 2024 in „APL Machine Learning“ veröffentlicht.

Link zum Papier: https://doi.org/10.1063/5.0203931
Forschungshintergrund
In den letzten Jahren hat die rasante Entwicklung der Deep-Learning-Technologie beispiellose Veränderungen und Innovationen in verschiedenen Bereichen mit sich gebracht. Es hat sich zu einem effektiven Werkzeug für die Verarbeitung komplexer und großer Datenmengen in mehreren Disziplinen entwickelt.
Auf neuronalen Netzen basierende Methoden können relevante Merkmale und potenzielle Muster von Zieldaten effektiv erkennen, es bestehen jedoch immer noch gewisse Herausforderungen, wenn Deep-Learning-Modelle diese verwandten Daten aus verschiedenen Bereichen und unterschiedlichen Formaten direkt lernen. Um dieses Problem zu lösen, können Techniken zur Merkmalsextraktion eingesetzt werden. Techniken zur Merkmalsextraktion können Rohdaten in eine für eine bestimmte Aufgabe geeignete Darstellung umwandeln. Es können verschiedene Methoden zur Merkmalsextraktion verwendet werden, z. B. FFT basierend auf Frequenzbereichsanalyse, WT basierend auf Wavelet-Transformation usw. Durch die Anwendung dieser Technologien können verschiedene Bereiche kombiniert werden.
In den letzten Jahren sind Forschungsbereiche, die Deep-Learning-Technologie kombinieren, im Allgemeinen mit Problemen wie der geringen Größe und geringen Qualität vorhandener Datensätze konfrontiert, was sich auf den Lerneffekt des Modells auswirkt Zielaufgabe.
Im gesamten Forschungsprozess „KI für die Wissenschaft“ ist der teuerste Teil hauptsächlich die Erstellung von Datensätzen. Daher ist es entscheidend, wie vorhandene Datensätze effektiver genutzt werden können.
Das Team der Universität Tianjin hat durch Untersuchungen bewiesen, dass das Hinzufügen zusätzlicher Mehrfrequenz-Eingabeinformationen zum vorhandenen Datensatz während des Zielspektrum-Vorhersageprozesses die Vorhersagegenauigkeit des Netzwerks erheblich verbessern kann. Dieser Ansatz liefert neue Ideen für die Nutzung von Datensätzen für interdisziplinäre Forschung und Anwendungen im Deep Learning und anderen Bereichen wie Photonik, Verbundwerkstoffdesign und Biomedizin.
Forschungshöhepunkte
Der innovative Punkt der Forschung besteht darin, die Idee der Aufteilung der Spektralinformationen im gesamten Frequenzbereich vorzuschlagen, die sich in der Kombination der tatsächlichen Designanforderungen und der Aufteilung der Spektralinformationen der gesamten Frequenz in Lernen manifestiert Aufgaben entsprechend dem Arbeitsfrequenzteil und dem Nichtarbeitsfrequenzpunkt.
Um die Universalität dieser Lösung zu demonstrieren, wurde das Zielbetriebsfrequenzband in einen Teil mit Niederfrequenzinformationen (0–1 THz) und einen Teil mit Hochfrequenzinformationen (1–2 THz) verfeinert, um die verbesserte Wirkung des Modells zu demonstrieren Lernen.
Verglichen mit der direkten Vorhersage der Arbeitsfrequenzbereichsdaten sank der Gesamtvorhersagefehler der Übertragungsspektrumdaten nach Ergänzung der Niederfrequenzinformationen um etwa 80 % Der Fehler lag nur bei etwa 40 % der direkten Vorhersagen vor. Die entworfene Metaoberflächenstruktur und die Modellarchitektur sind in Abbildung 1 dargestellt:
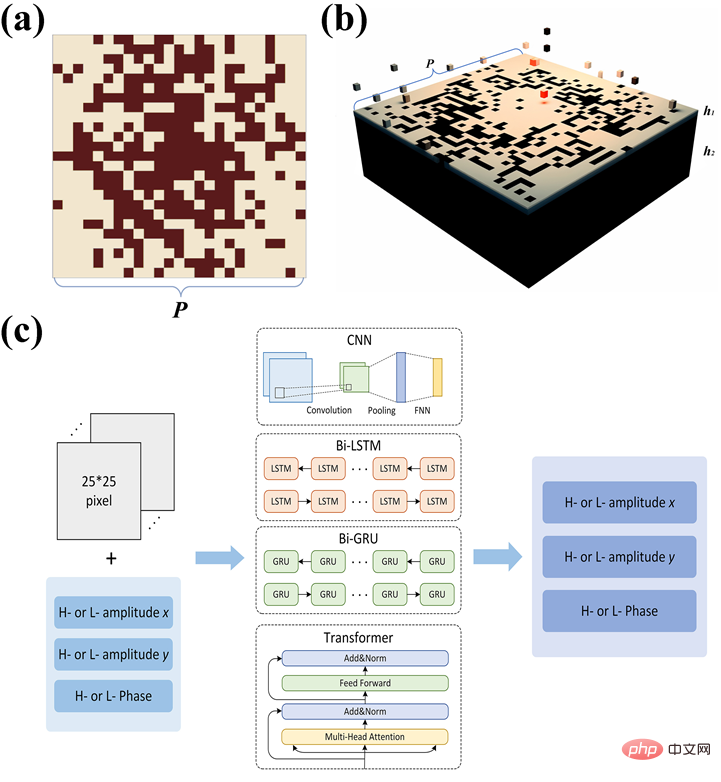
Um den Vorhersageeffekt von Amplituden- und Phasenparametern bei verschiedenen Betriebsfrequenzen nach der Optimierung intuitiver darzustellen, werden einige Metaoberflächenstrukturen zufällig für die Simulationsdemonstration in der CST Studio Suite-Software ausgewählt, wie in Abbildung 2 dargestellt:

Abbildung 2 Schematische Darstellung des Vorhersageeffekts optimierter Hochfrequenz- und Niederfrequenzdaten. (a)-(f) Demonstrieren Sie die unterschiedliche Vorhersageleistung des optimierten Netzwerkmodells in verschiedenen Frequenzbereichen, indem Sie reale Daten (violette durchgezogene Linie) mit vorhergesagten Daten (schwarze gestrichelte Linie) vergleichen. Grüne Bereiche stellen Frequenzinformationsdaten dar, die als zusätzliche Eingabe verwendet werden, während gelbe Bereiche Bereiche darstellen, die zur Validierung optimierter Vorhersageleistung verwendet werden. wobei a und b die Vorhersageergebnisse der Hochfrequenz- und Niederfrequenzamplituden des x-Polarisationszustands darstellen. (c)-(d) Vorhersageergebnisse von Hochfrequenz- und Niederfrequenzamplituden des y-Polarisationszustands. (e)-(f) Vorhersageergebnisse von Hochfrequenz- und Niederfrequenzphasen.
Zusammenfassung und Ausblick
Diese Forschung verbessert effektiv die Nutzungseffizienz bestehender Datensätze, indem sie eine gezielte Datensatzaufteilung für Lernaufgaben verschiedener optischer Probleme durchführt und dadurch den Lerneffekt von Deep-Learning-Modellen verbessert.
Diese Optimierungslösung lindert effektiv das Problem kleiner vorhandener optischer Datensätze (insbesondere verwandte Datensätze im Terahertz-Band) und bietet außerdem mehr Forschungsfelder, die Deep-Learning-Technologie, aber teure Daten kombinieren, wie z. B. Verbundmaterialdesign und medizinische Bildanalyse , Finanzdatenvorhersage usw. bieten eine neue Perspektive für die Optimierung von Datensätzen.
Das obige ist der detaillierte Inhalt vonUm die Nutzung optischer Datensätze zu verbessern, schlug das Tianda-Team ein KI-Modell vor, um den spektralen Vorhersageeffekt zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- PHP-Theorie regulärer Ausdrücke
- Detaillierte Einführung in die MySQL-Theorie und Grundkenntnisse
- Welche Programmtheorie liegt dem virtuellen Speicherverwaltungssystem zugrunde?
- Die Peking-Universität und Alibaba gründen ein gemeinsames Labor, das sich auf die Theorie der künstlichen Intelligenz und die Forschung zu innovativen Algorithmen konzentriert
- „Aufruf zur Innovation: UCL Wang Jun diskutiert die Theorie und Anwendungsaussichten der allgemeinen künstlichen Intelligenz von ChatGPT'