
Heim >Technologie-Peripheriegeräte >KI >Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-02 15:24:401081Durchsuche
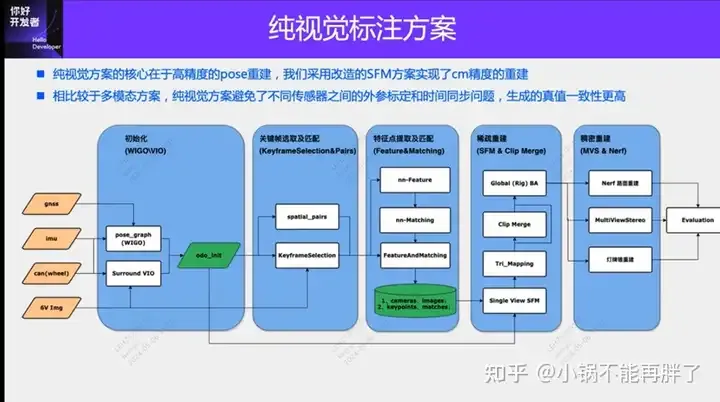
Die rein visuelle Etikettierungslösung nutzt hauptsächlich die Sicht sowie einige Daten von GPS, IMU und Radgeschwindigkeitssensoren für die dynamische Etikettierung. Für Massenproduktionsszenarien muss es sich natürlich nicht um reine Sicht handeln. Einige Massenfahrzeuge verfügen über Sensoren wie Festkörperradar (AT128). Wenn wir aus Sicht der Massenproduktion einen geschlossenen Datenkreislauf erstellen und alle diese Sensoren verwenden, können wir das Problem der Kennzeichnung dynamischer Objekte effektiv lösen. Aber in unserem Plan gibt es kein Festkörperradar. Aus diesem Grund stellen wir diese gängigste Etikettierungslösung für die Massenproduktion vor.
Der Kern der rein visuellen Annotationslösung liegt in der hochpräzisen Posenrekonstruktion. Wir verwenden das Posenrekonstruktionsschema „Structure from Motion“ (SFM), um die Genauigkeit der Rekonstruktion sicherzustellen. Allerdings ist herkömmliches SFM, insbesondere inkrementelles SFM, sehr langsam und rechenintensiv. Der Rechenaufwand beträgt O(n^4), wobei n die Anzahl der Bilder ist. Diese Art der Rekonstruktionseffizienz ist für die Datenannotation großer Modelle nicht akzeptabel. Wir haben einige Verbesserungen an der SFM-Lösung vorgenommen.
Die verbesserte Clip-Rekonstruktion ist hauptsächlich in drei Module unterteilt: 1) Erstellen Sie mithilfe von Multisensordaten, GNSS, IMU und Radgeschwindigkeitsmesser eine Pose_Graph-Optimierung und erhalten Sie die anfängliche Pose. Dieser Algorithmus wird als Wheel-Imu-GNSS-Odometrie bezeichnet. WIGO); 2) Merkmalsextraktion und Abgleich des Bildes und Triangulation direkt unter Verwendung der initialisierten Pose, um die anfänglichen 3D-Punkte zu erhalten. 3) Schließlich wird eine globale BA (Bündelanpassung) durchgeführt. Einerseits vermeidet unsere Lösung inkrementelles SFM, andererseits können parallele Vorgänge zwischen verschiedenen Clips realisiert werden, wodurch die Effizienz der Posenrekonstruktion im Vergleich zur bestehenden inkrementellen Rekonstruktion erheblich verbessert wird und 10 bis 20 erreicht werden kann mal Effizienzsteigerung.
Während des einzelnen Rekonstruktionsprozesses hat unsere Lösung auch einige Optimierungen vorgenommen. Beispielsweise verwenden wir Lernbasierte Funktionen (Superpoint und Superglue), eines ist der Feature-Punkt und das andere ist die Matching-Methode , um die traditionellen SIFT-Schlüsselpunkte zu ersetzen. Der Vorteil des Erlernens von NN-Features besteht darin, dass einerseits Regeln auf datengesteuerte Weise entworfen werden können, um einige individuelle Anforderungen zu erfüllen und die Robustheit bei einigen schwachen Texturen und dunklen Lichtverhältnissen zu verbessern Effizienz der Schlüsselpunkterkennung und -zuordnung. Wir haben einige Vergleichsexperimente durchgeführt und festgestellt, dass die Erfolgsquote von NN-Funktionen in Nachtszenen etwa viermal höher ist als die von SFIT, nämlich von 20 % bis 80 %.
Nachdem wir das Rekonstruktionsergebnis eines einzelnen Clips erhalten haben, werden wir mehrere Clips zusammenfassen. Um die Genauigkeit der Aggregation sicherzustellen, verwenden wir im Gegensatz zum vorhandenen HDmap-Mapping-Struktur-Matching-Schema die Aggregation auf Feature-Punkt-Ebene, d. h. die Aggregationsbeschränkungen zwischen Clips werden durch den Matching von Feature-Punkten implementiert. Diese Operation ähnelt der Schleifenschlusserkennung in SLAM. Zunächst werden einige Kandidaten-Matching-Frames ermittelt, dann werden Merkmalspunkte und Beschreibungen verwendet, um Bilder abzugleichen. Anschließend werden diese Schleifenschlussbeschränkungen kombiniert, um ein globales BA (Bundle) zu erstellen Anpassung) und optimieren. Derzeit übertreffen die Genauigkeit und der RTE-Index unserer Lösung einige bestehende visuelle SLAM- oder Mapping-Lösungen bei weitem.
Experiment: Verwenden Sie die Colmap-Cuda-Version, verwenden Sie 180 Bilder, eine Auflösung von 3848 * 2168, stellen Sie die internen Parameter manuell ein und verwenden Sie für den Rest die Standardeinstellungen. Die spärliche Rekonstruktion dauert etwa 15 Minuten, und die gesamte dichte Rekonstruktion dauert extrem lange Zeit (1-2h)
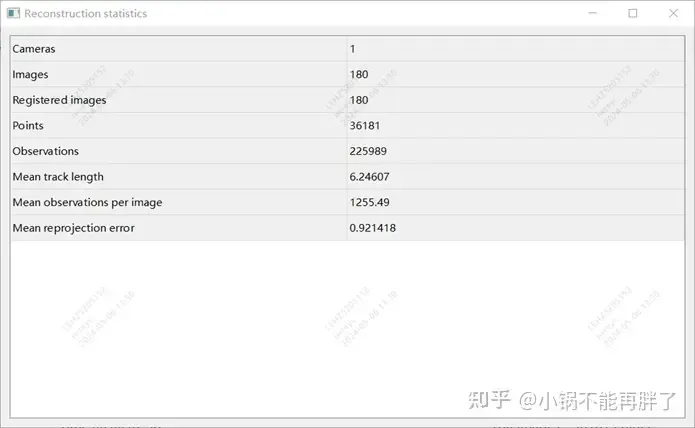
Statistik der Rekonstruktionsergebnisse
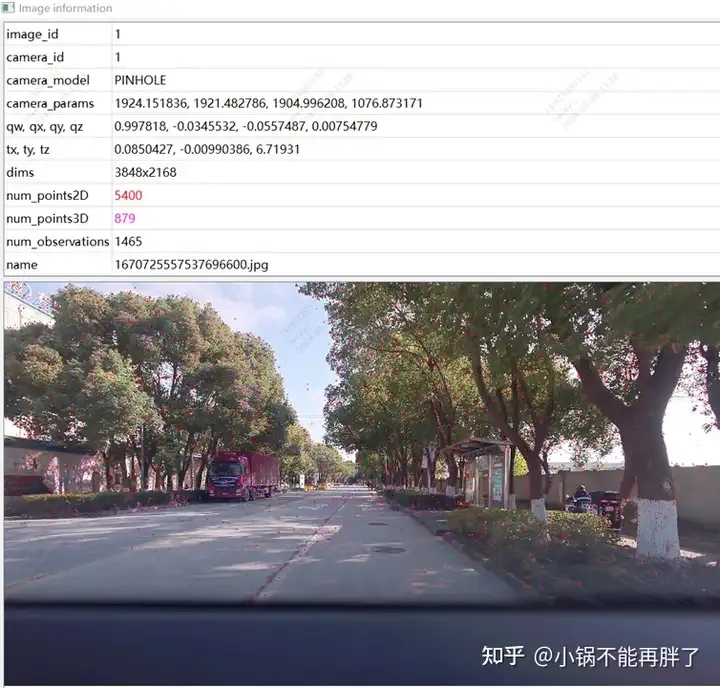
Merkmalspunktdiagramm

Spärlicher Rekonstruktionseffekt

Gesamteffekt des geraden Abschnitts

Bodenkegeleffekt

Geschwindigkeitsbegrenzungsschild in der Höhe Effekt

Kreuzungs-Zebrastreifen-Effekt
Außerdem habe ich eine Reihe von Bildern ausprobiert und es kam nicht zu einer Konvergenz: statisches Ego-Filtern, Formen ein Clip alle 50-100 m entsprechend der Bewegung des Fahrzeugs; dynamische Punktfilterung der hochdynamischen Szene, Pose der Tunnelszene
Verwenden Sie Umfangs- und Panorama-Mehrfachkameras: Feature-Point-Matching-Kartenoptimierung, interne und externe Parameteroptimierungselemente und Nutzung vorhandener Odom.
https://github.com/colmap/colmap/blob/main/pycolmap/custom_bundle_adjustment.py
pyceres.solve(solver_options, bundle_adjuster.problem, summary)
3DGS beschleunigt die dichte Rekonstruktion, sonst dauert es zu lange akzeptieren
Das obige ist der detaillierte Inhalt vonDie erste rein visuelle statische Rekonstruktion des autonomen Fahrens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Fünf Möglichkeiten, wie Computer Vision zur Lösung geschäftlicher Herausforderungen beitragen kann
- Dieser Artikel vermittelt Ihnen ein leicht verständliches Verständnis des autonomen Fahrens
- Ein Artikel zum Verständnis der Lidar- und visuellen Fusionswahrnehmung des autonomen Fahrens
- Einführung in Java-basierte Bildverarbeitungspraktiken und -methoden