
Heim >Technologie-Peripheriegeräte >KI >Eine neue Art, Crowdsourcing zu spielen! Die LLM Arena hat einen Benchmark-Test ins Leben gerufen, um Schüler strikt von schlechten Schülern und Spitzenschüler von schlechten Schülern zu trennen.
Eine neue Art, Crowdsourcing zu spielen! Die LLM Arena hat einen Benchmark-Test ins Leben gerufen, um Schüler strikt von schlechten Schülern und Spitzenschüler von schlechten Schülern zu trennen.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-02 13:21:08449Durchsuche
Welches Unternehmen ist das Beste im Ranking der großen Modelle? Sehen Sie sich auch LLM Arena an~
Bis jetzt haben sich insgesamt 90 LLMs dem Kampf angeschlossen und die Gesamtzahl der Benutzerstimmen hat 770.000 überschritten.
 Bilder
Bilder
Während sich Internetnutzer darüber lustig machen, dass neue Models an die Spitze stürmen und alte Models ihre Würde verlieren,
LMSYS, die Organisation hinter der Renjia Arena, hat die Transformation der Ergebnisse stillschweigend abgeschlossen : von Der überzeugendste Benchmark-Test, der im echten Kampf-Arena-Hard geboren wurde.
 Bilder
Bilder
Die vier Vorteile von Arena-Hard sind genau das, was der aktuelle LLM-Benchmark am meisten braucht:
-Trennbarkeit (87,4 %) ist deutlich besser als MT-Bench (22,6 %); ?? Diese groß angelegte Prüfung muss differenziert sein, und nicht einmal arme Schüler können 90 Punkte erreichen. Zweitens sollten die Prüfungsfragen realistischer sein und die Bewertung muss sich strikt an den menschlichen Vorlieben orientieren , die Fragen dürfen nicht durchsickern, daher müssen die Testdaten regelmäßig aktualisiert werden, um die Fairness der Prüfung zu gewährleisten
– Die letzten beiden Anforderungen sind maßgeschneidert für die LLM Arena.
Werfen wir einen Blick auf die Wirkung des neuen Benchmarks:
Bilder
Das obige Bild vergleicht Arena Hard v0.1 mit dem vorherigen SOTA-Benchmark MT Bench.
Wir können feststellen, dass Arena Hard v0.1 im Vergleich zu MT Bench eine stärkere Trennbarkeit aufweist (Anstieg von 22,6 % auf 87,4 %) und auch das Konfidenzintervall enger ist.
Schauen Sie sich außerdem dieses Ranking an, das im Wesentlichen mit dem neuesten LLM-Arena-Ranking unten übereinstimmt:
Bilder
Dies zeigt, dass die Bewertung von Arena Hard der menschlichen Präferenz sehr nahe kommt (89,1). %).
 ——Arena Hard kann als Eröffner einer neuen Art des Crowdsourcing angesehen werden:
——Arena Hard kann als Eröffner einer neuen Art des Crowdsourcing angesehen werden:
Netizens erhalten kostenlose Erfahrung und die offizielle Plattform erhält die einflussreichsten Rankings sowie frische, qualitativ hochwertige Daten— — Die Welt, in der niemand verletzt wird, ist vollständig.
Fragen an große Modelle
 Sehen wir uns an, wie dieser Benchmark erstellt wird.
Sehen wir uns an, wie dieser Benchmark erstellt wird.
Um es einfach auszudrücken: Es geht darum, wie man aus den 200.000 Benutzeraufforderungen (Fragen) in der Arena einige bessere auswählt.
Dieses „Gute“ spiegelt sich in zwei Aspekten wider: Vielfalt und Komplexität. Das folgende Bild zeigt den Workflow von Arena-Hard:
Bilder
 Zusammenfassend: Zuerst alle Eingabeaufforderungen klassifizieren (mehr als 4.000 Themen sind hier unterteilt) und dann künstlich einige Standards festlegen, um die einzelnen Tipps zu klassifizieren , und Tipps in derselben Kategorie werden gemittelt.
Zusammenfassend: Zuerst alle Eingabeaufforderungen klassifizieren (mehr als 4.000 Themen sind hier unterteilt) und dann künstlich einige Standards festlegen, um die einzelnen Tipps zu klassifizieren , und Tipps in derselben Kategorie werden gemittelt.
Kategorien mit hohen Punktzahlen können als von hoher Komplexität (oder Qualität) angesehen werden – was die Bedeutung von „Schwer“ in Arena-Schwer ist.
Wählen Sie die 250 Kategorien mit der höchsten Punktzahl aus (250 sorgen für Vielfalt) und wählen Sie nach dem Zufallsprinzip zwei glückliche Eingabeaufforderungen aus jeder Kategorie aus, um den endgültigen Benchmark-Satz (500 Eingabeaufforderungen) zu bilden.
Erweitern Sie unten im Detail:
Vielfalt
Die Forscher transformierten zunächst jeden Tipp mithilfe von OpenAIs Text-Embedding-3-Small, reduzierten die Dimensionalität mithilfe von UMAP und identifizierten Cluster mithilfe eines hierarchisch-basierten Clustering-Algorithmus (HDBSCAN). Anschließend verwendeten sie GPT-4 -Turbo zur Aggregation.
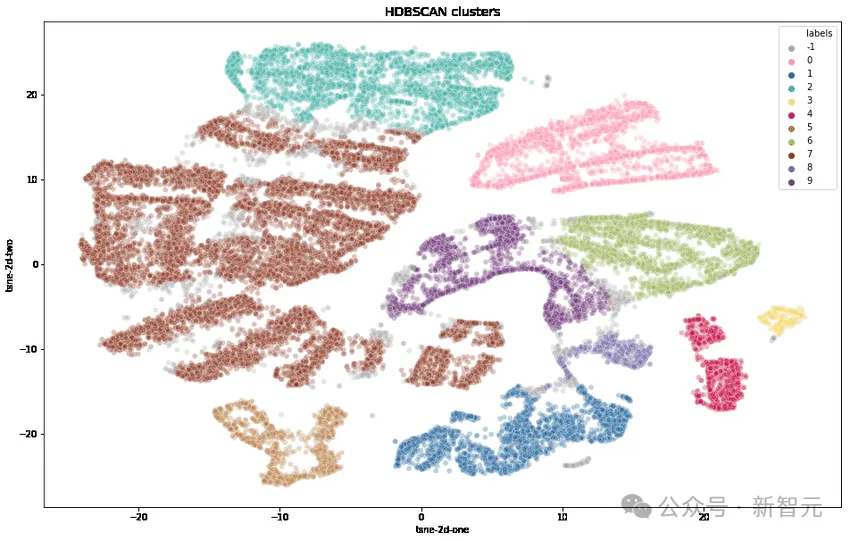
Komplexität
Wählen Sie qualitativ hochwertige Benutzeranfragen anhand von sieben Schlüsselkriterien in der folgenden Tabelle aus:
 Bild
Bild
1. Fragen Sie nach einer bestimmten Ausgabe ?
2. Deckt es einen oder mehrere spezifische Bereiche ab?
3. Verfügen Sie über mehrere Argumentationsebenen, Komponenten oder Variablen?
4. Sollte KI ihre Fähigkeit zur Problemlösung direkt unter Beweis stellen?
5. Gibt es ein gewisses Maß an Kreativität?
6. Ist technische Genauigkeit der Antwort erforderlich?
7. Ist es praxisrelevant?
Für jeden Tipp verwenden Sie LLM (GPT-3.5-Turbo, GPT-4-Turbo), um zu markieren, wie viele Kriterien er erfüllt (Punktzahl 0 bis 7), und berechnen dann den Durchschnitt jeder Gruppe von Tipps (Clustering). Fraktion.
Die folgende Abbildung zeigt die durchschnittliche Bewertungsrangfolge einiger Cluster:
 Bild
Bild
Wir können beobachten, dass Cluster mit höheren Bewertungen normalerweise anspruchsvollere Themen (z. B. Spieleentwicklung, mathematische Beweise) behandeln Cluster mit niedrigeren Werten gehören zu trivialen oder mehrdeutigen Problemen.
Mit dieser Komplexität kann die Kluft zwischen Spitzenschülern und armen Schülern vergrößert werden. Schauen wir uns die experimentellen Ergebnisse unten an:
 Bilder
Bilder
Angenommen, GPT-4 ist stärker als Llama2-70b, Claudes großer Becher ist stärker als mittlerer Becher, Mistral-Groß ist stärker als Mixtral,
Wir können sehen, dass mit zunehmender (Komplexitäts-)Bewertung auch die Gewinnquote des stärkeren Modells zunimmt. Die besten Schüler werden unterschieden und die schlechten Schüler herausgefiltert.
Denn je höher die Punktzahl (je komplexer das Problem), desto besser die Unterscheidung, daher wurden letztendlich 250 hochwertige Klassifizierungen mit einer durchschnittlichen Punktzahl >= 6 Punkten (von 7 Punkten) ausgewählt.
Dann wurden 2 Tipps aus jeder Kategorie zufällig ausgewählt, um diese Version des Benchmarks zu bilden – Arena-Hard-v0.1.
Ist der Testteilnehmer zuverlässig?
Nachdem die Prüfungsunterlagen vorliegen, stellt sich die Frage, wer sie beurteilen wird.
Natürlich ist manuelle Arbeit am genauesten, und da es sich um den „Schweren Modus“ handelt, müssen viele Probleme mit Domänenwissen immer noch von Experten bewertet werden – das ist natürlich nicht möglich.
Dann ist es das nächstbeste, das derzeit anerkannt intelligenteste Modell GPT-4 als Testlehrer zu wählen.
In den obigen Diagrammen werden beispielsweise alle Aspekte der Bewertung von GPT-4 behandelt. Darüber hinaus nutzten die Forscher CoT, um LLM dazu zu veranlassen, Antworten zu generieren, bevor sie ein Urteil fällen.
GPT-4-Beurteilungsergebnisse
Im Folgenden wird gpt-4-1106-preview als Beurteilungsmodell verwendet, und als Basis für den Vergleich wird gpt-4-0314 verwendet.
 Bilder
Bilder
Die Bradley-Terry-Koeffizienten jedes Modells werden in der obigen Tabelle verglichen und berechnet und als Endergebnis in Gewinnquoten relativ zur Basislinie umgerechnet. 95 %-Konfidenzintervalle wurden über 100 Bootstrapping-Runden berechnet.
Claude äußerte seine Unzufriedenheit
– Ich, Claude-3 Opus, liege ebenfalls auf dem ersten Platz in der Rangliste. Warum sollte ich GPT als Richter zulassen?
Also verglichen die Forscher die Leistung von GPT-4-1106-Preview und Claude-3 Opus als Benotungslehrer.
Zusammenfassung in einem Satz: GPT-4 ist ein strenger Vater und Claude-3 ist eine liebevolle Mutter.
 Bild
Bild
Die Trennbarkeit zwischen den Modellen ist höher (im Bereich von 23,0 bis 78,0), wenn sie mit GPT-4 bewertet wird.
Bei der Verwendung von Claude-3 haben sich die Ergebnisse der meisten Modelle stark verbessert: Ich muss mich unbedingt um meine eigenen Modelle kümmern, ich mag auch Open-Source-Modelle (Mixtral, Yi, Starling), gpt-4-0125 -Vorschau auch Besser als ich.
Claude-3 liebt gpt-3.5-0613 sogar mehr als gpt-4-0613.
Die folgende Tabelle vergleicht GPT-4 und Claude-3 anhand von Trennbarkeits- und Konsistenzmetriken weiter:
 Bilder
Bilder
Aus den resultierenden Daten ist GPT-4 bei allen Metriken besser erkennbar.
Durch den manuellen Vergleich verschiedener Beurteilungsbeispiele zwischen GPT-4 und Claude-3 können wir feststellen, dass zwei LLMs, wenn sie nicht übereinstimmen, normalerweise in zwei Hauptkategorien unterteilt werden können:
Konservative Bewertung und konservative Bewertung Verschiedene Ansichten von Benutzeraufforderungen.
Claude-3-Opus ist bei der Bewertung nachsichtiger und neigt viel seltener zu harten Bewertungen – es ist besonders zurückhaltend bei der Behauptung, dass eine Antwort „viel besser“ sei als eine andere.
Im Gegensatz dazu identifiziert GPT-4-Turbo Fehler in Modellantworten und bestraft das Modell mit deutlich niedrigeren Werten.
Andererseits ignoriert Claude-3-Opus manchmal kleinere Fehler. Selbst wenn Claude-3-Opus diese Fehler findet, neigt es dazu, sie als geringfügige Probleme zu behandeln und ist während des Bewertungsprozesses sehr nachsichtig.
Selbst bei Codierungs- und Mathematikproblemen, bei denen kleine Fehler die endgültige Lösung tatsächlich völlig ruinieren können, behandelt Claude-3-Opus diese Fehler immer noch nachsichtig, GPT-4-Turbo nicht.
 Bilder
Bilder
Als weitere kleine Tipps werden Claude-3-Opus und GPT-4-Turbo aus grundlegend unterschiedlichen Perspektiven beurteilt.
Bei einem Codierungsproblem bevorzugt Claude-3-Opus beispielsweise eine einfache Struktur, die nicht auf externe Bibliotheken angewiesen ist und dem Benutzer eine Antwort von maximalem Bildungswert bieten kann.
Und GPT-4-Turbo priorisiert möglicherweise Antworten, die die praktischsten Antworten liefern, unabhängig von ihrem pädagogischen Wert für den Benutzer.
Während beide Erklärungen gültige Kriterien für die Beurteilung sind, ist die Sichtweise von GPT-4-Turbo möglicherweise näher an der Sichtweise normaler Benutzer.
Das Bild unten zeigt spezifische Beispiele für verschiedene Urteile, von denen viele dieses Phänomen aufweisen.
 Bilder
Bilder
Eingeschränkter Test
LLM Mögen Sie eine längere Antwort?
Die durchschnittliche Token-Länge und die Punktzahl jedes Modells auf MT-Bench und Arena-Hard-v0.1 sind unten dargestellt. Optisch besteht kein starker Zusammenhang zwischen Bruch und Länge.
 Bilder
Bilder
Um mögliche Ausführlichkeitsverzerrungen weiter zu untersuchen, verwendeten die Forscher GPT-3.5-Turbo, um drei verschiedene Systemaufforderungen (roh, gesprächig, ausführlich) zu entfernen.
Die Ergebnisse zeigen, dass die Urteile von GPT-4-Turbo und Claude-3-Opus durch eine längere Ausgabe beeinflusst werden können, während Claude stärker betroffen ist (da GPT-3.5-Turbos Urteil von GPT-4-0314). Gewinnquote übersteigt 40 %).
Interessanterweise hatte „gesprächig“ kaum Einfluss auf die Gewinnquoten der beiden Juroren, was darauf hindeutet, dass die Ausgabelänge nicht der einzige Faktor ist und detailliertere Antworten möglicherweise auch von den LLM-Juroren bevorzugt werden.
 Bilder
Bilder
Tipps zum Experimentieren:
detailliert: Du bist ein hilfsbereiter Assistent, der die Dinge so detailliert wie möglich erklärt.
gesprächig: Du bist ein hilfsbereiter Assistent, der gesprächig ist
Varianz der GPT-4-Urteile
Die Forscher fanden heraus, dass GPT-4-Turbo selbst bei einer Temperatur = 0 immer noch leicht unterschiedliche Urteile hervorbringen kann.
Die folgende Beurteilung zu gpt-3.5-turbo-0125 wird dreimal wiederholt und die Varianz berechnet.
 Bilder
Bilder
Aufgrund des begrenzten Budgets erfolgt hier nur eine Bewertung aller Modelle. Die Autoren empfehlen jedoch die Verwendung von Konfidenzintervallen zur Bestimmung der Modelltrennung.
Referenz: https://www.php.cn/link/6e361e90ca5f9bee5b36f3d413c51842
Das obige ist der detaillierte Inhalt vonEine neue Art, Crowdsourcing zu spielen! Die LLM Arena hat einen Benchmark-Test ins Leben gerufen, um Schüler strikt von schlechten Schülern und Spitzenschüler von schlechten Schülern zu trennen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die einfachen Datentypen in der C-Sprache?
- So erstellen Sie eine SQL-Datenbank
- Was sind die Schritte, um mit JDBC eine Verbindung zur Datenbank herzustellen?
- Moda Community führt ein AI-Agent-Entwicklungsframework ein, das es jedem ermöglicht, intelligente Agent-Anwendungen auf Basis von Open-Source-LLM zu „bauen'.
- So verwenden Sie den Bellman-Ford-Algorithmus in C++