
pandas学习001-pandas.read_excel函数
pandas.read_excel(io, sheet_name=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None, usecols=None, parse_dates=False, date_parser=None, na_values=None, thousands=None, convert_float=True, converters=None, dtype=None, true_values=None, false_values=None, engine=None, squeeze=False, **kwds)
【作用】
将Excel文件读取到pandas DataFrame中。
支持从本地文件系统或URL读取的xls,xlsx,xlsm,xlsb和odf文件扩展名。支持读取一张纸或一张纸的列表的选项。
【返回】
数据框或数据框的字典
来自传入的Excel文件的DataFrame。有关何时返回DataFrames字典的更多信息,请参见sheet_name参数中的注释。
【参数】
1.io :excel 路径;本地文件可以是:file://localhost/path/to/table.xlsx。
2.sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。
3.header :指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None;
4.skiprows:读取数据时:省略指定行数的数据
5.skipfooter:读取数据时:省略从尾部数的行数据
6.index_col :指定列为索引列,也可以使用 u’string’
7.names:指定列的名字,传入一个list数据
8.dtype=None,
dtype 类型名称或列的dict- >类型,默认为无
数据或列的数据类型。例如{‘a’:np.float64,’b’:np.int32}使用对象将数据保存为Excel中存储的内容,而不解释dtype。如果指定了转换器,则会将它们应用于dtype转换的INSTEAD
9.parse_cols:指定需要解析的字段
10.parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;
如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)
11.na_values:指定原始数据中哪些特殊值代表了缺失值
12.thousands:指定原始数据集中的千分位符
13.convert_float:默认将所有的数值型字段转换为浮点型字段
14.converters:通过字典的形式,指定某些列需要转换的形式
【实践】
如下图,一个excel文件中有两个表,我想读取数据,跳过首行与不要最后一行并且以‘序号’为索引,
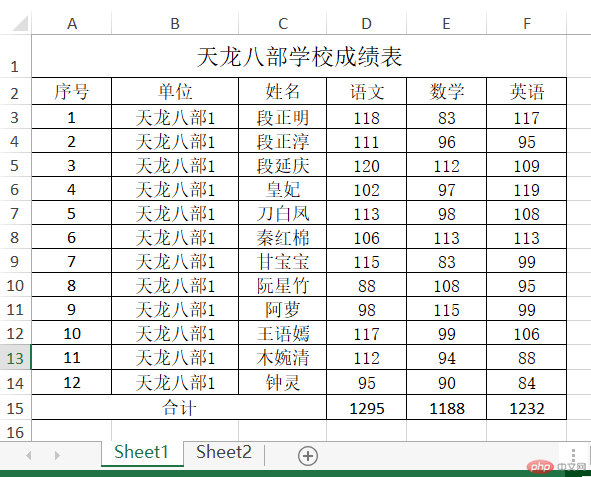
import pandas as pdpath="E://yhd_python/pandas.read_excel/student.xlsx"df=pd.read_excel(path,sheet_name=None,skiprows=1,skipfooter=1,index_col="序号")df
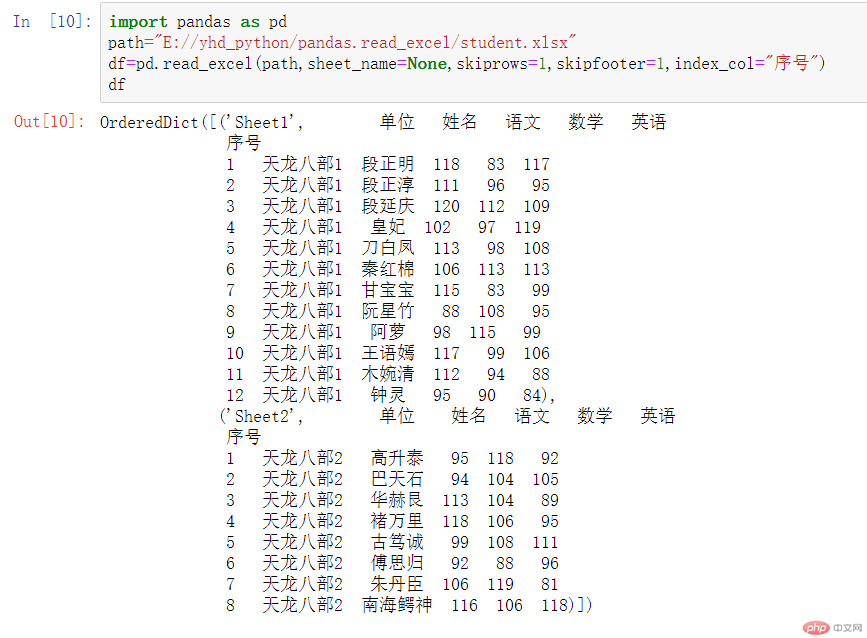
可以看到取得了一个字典,可以用df[“Sheet1”]或df[‘Sheet2’]读取到相应的表的数据