

和其他数据库系统相比,MySQL有点与众不同,它的架构可以在多种不同的场景中应用 并发挥好的作用,但同时也会带来有点选择上的困难。MySQL并不完美,却足够灵活,能够适应高要求的环境,列如web类的应用。同时,MySQL既可以嵌入到应用程式中,也可以支持数据仓库、内容索引和部署软件、高可用的冗余系统,在线事务处理系统(OLTP)等各种应用类型。
怎么专业的。。。。。。的文字我大脑跟不上 。。
为了充分的发挥MySQL的性能并顺利的使用,就必须理解其设计。MySQL的灵活性体现在很多的方面。例如,你可以通过配置使它在不同的硬件上都运行地很好,也可以支持多种不同的数据类型。但是,MySQL最重要、最与众不同的特性是它的存储引擎架构,这种架构的设计将查询处理及其他的系统任务和数据储存/提取相分离。这种处理和储存分离的设计可以在使用时根据性能、特性,及其他的需求来选择数据存储的方式。
以下是MySQL的逻辑框架图

最上层的服务并不是MySQL所独有的,大多数基于网络的客户端/服务器的工具或者服务器都有类似的架构。比如连接处理、授权认证、安全等等。
第二层架构是MySQL比较有意思的部分。大多数MySQL的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及内置函数(列如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
第三层包含了存储引擎。存储引擎负责MySQL中的数据的存储和提取。和GNU/Linux下的各种文件系统一样,每个存储引擎都有它的优势和劣势。服务器通过API与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层查询过程透明。存储引擎API包括几十个底层函数,用于执行诸如“开始一个事务”或者“根据住家提取一行记录”等操作。但是存储引擎不会解析SQL,不同存储引擎之间也不会互相通信,而只是简单地响应上层服务器的请求。
优化与执行
MySQL会解析查询,并创建内部数据结构(解析树),然后对其进行各种优化,包括重写查询、决定表的读取顺序,以及选择合适的索引等。用户可以通过特殊的关键字提示优化器,影响它的决策过程,也可以请求优化器解析优化过程的各个因素,使用户可以知道服务器是如何进行优化决策的,并提供了一个参考的基准,便于用户重构查询和schma、修改相关配置。
优化器并不关心表使用的是什么存储引擎,但是存储引擎对于优化查询是有影响的。优化器会请求存储引擎提供容量或者具体操作的开销信息,以及表数据统计信息等。
对于select语句,在解析查询之前,服务器会先检查查询缓存,如果能够在其中找到对应的查询,服务器就不必要执行查询解析、优化和执行整个过程,而是直接返回查询缓存中的结果集。
MySQL性能优化的最佳21条建议 :(当中还有很多地方自己不是很理解 ( ̄▽ ̄)و)
这21条建议出自 : http://blog.csdn.net/waferleo/article/details/7179009 想看详细的资料请去这里
1、为查询缓存优化你的查询
大多数的MySQL服务器都开启了查询缓存。这是提高性能最有效方法之一,而且这是被MySQL的数据库引擎处理的。当很多相同的查询被执行了多次的时候,这些查询的结果会放到一个缓存中,这样,后续相同的查询就不需要操作表而是直接的访问缓存的结果了。
对于程序员来说,这个事情是很容易被忽略的。因为,我们某些查询语句会让MySQL不使用缓存。
//查询储存不开启
$r = mysql_query("SELECT username FROM user WHERE signup_data >= CURDATE()");
//开启查询缓存
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today' ");
上面两条SQL语句的差别在于是CURDATE() ,MySQL的查询缓存对于这个函数不起作用,所以,像NOW()和 RAND()或是其他的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定期的易变的。所以,你需要的就是用一个变量来代替MySQL的函数,从而开启缓存。
2、EXPLAIN你的SELECT查询
使用explain关键字可以让你知道MySQL是如何处理你的目、MySQL语句的。这可以帮助你的查询或是表结构的性能瓶颈。
explain的查询结果还会告诉你你的索引主键被如何利用的,你的数据表示如何被搜索和排序的。。。等等。挑一个你的select语句(推荐挑选那个最复杂的,有多表联接的),把关键字explain加到前面。你可以使用phpmyadmin来做这个事。然后,你会看到一张表格。下面的这个示例中,我们忘记加上了group_id索引并且有表联接
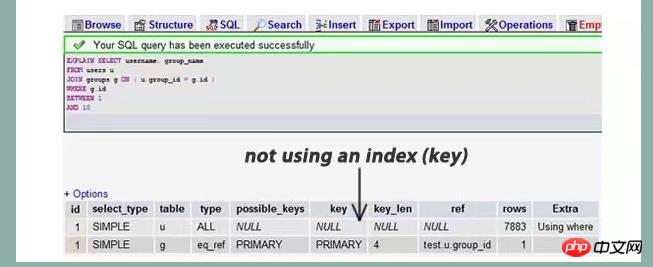
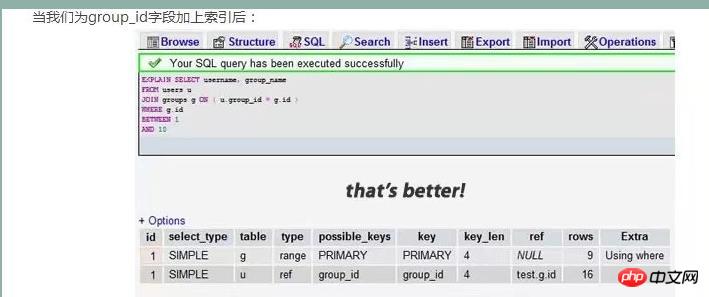
我们可以看到,前一个结果显示搜索了7883行,而后一个只是搜索了两个表的9和16行。查看rows可以让我们找到潜在的性能问题。
3、当只要一行数据时使用limit1
当你查询表的有些时候,你要知结果会有一条结果,因为你可能需要去fetch游标,或者你也许会去检查返回的记录数。在这样的情况下,加上limit可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查。
4、为搜索字段建索引
索引并不定就是给主键或者是唯一的字段。如果在你的表中,有某个字段你总要经常用来做搜索,那么,请为其建立索引。
5、在join表的时候使用相当类型的例,并将其索引
如果你的应用程序有很多的join查询,你应该确认两个表中join的字段是被建立索引的,这样,MySQL内部会启动为你优化join的SQL语句的机制。
而且,这些被用来join的字段,应该是相同的类型的。例如:如果你要把decimal字段和一个int字段join在一起,MySQL就无法使用他们的索引。对于那些string类型,还需要有相同的字符集才行。(两个字符集可能不一样)
6、千万不要order by rand()
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这样的用法,但很多新手喜欢这样用,但你确实不了解这样的做有多可怕的问题。
如果你真的想把返回的数据行打乱了,你有N种方法到达这样的目的。这样使用只让你的数据性能呈指数级的下降。这里的问题是:MySQL会不得不去执行rand()函数(很消耗时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了limit1也无济于事(因为要排序啊弟弟 )
7、避免使用 select *
从数据库读出越来越多的数据,那么查询的速度会变慢。并且,如果你的数据服务器和web服务器是两台独立的服务器的话,这还会增加网路的负载。
所以,你应该养成一个需要什么就取什么的好习惯。
8、 永远为每张表设置一个ID
我们应该为数据库里的每一张表都设置一个ID作为主键,而且最好的数个int类型的(推荐使用unsigned),并设置上自动增加的auto_increment标志。
就算是你user表有一个主键叫“email”的字段,你也别让它成为主键。使用varchar类型来当主键会使性能下降的。另外,在你的程序中,你应该使用表的ID来结构你的数据结构。
而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这样的情况下,主键的性能和设置变得非常重要,比如,集群,分区等、、、
这里,只有一个情况是列外的,那就是“关联表”的“外键”,也就是说通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比如:一个“学生表”有学生的ID、“课程表”有课程ID,那么,“成绩表”就是关联表了,其关联了学生表和课程表,在成绩表中,学生ID和课程ID叫“外键”其共同组成主键。
9、使用enum而不是varchar
enum类型是非常快和紧凑的。在实际上,其保留的是tinyint,但是其外表上显示为字符串。这样一来,用这个字段来做一些选项列表就变得相当完美。
如果你有一个字段,比如,“性别”, “国家” ,“民族”,“状态”或者“部门”,你知道这些字段的取值是有限的而且是固定的,那么,你应该使用enum而不是varchar
MySQL也有一个“建议”(见第十条)告诉你怎么重新的组织你的表结构。当你有个varchar字段时,这个建议告诉你把其改成enum类型。使用procedure analyse()你可以得到相关的建议。
10、从procedure analyse() 取得建议
provedure analyse()会让MySQL帮你去分析你的字段和实际的数据,并会给你一些有用的建议。只是表中有实际的数据,这些建议才会变的有用,因为要做一些大的决定是需要数据作为基础的。
例如,你创建了一个int的字段作为你的主键,然而并么没有太多的数据,那么,pricedure analse()会建议你把这个字段的类型改成mediumint。或是你使用了一个varchar字段,因为数据不多,你可能得到一个让你把它改成enum的建议,这些建议,都是可能因为数据不多,所以决策做得就不够准。
在phpmyadmin里,你可以查看表时,点击“propse table structure”来查看这些建议
11、尽可能的使用not null
不要以为null不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会变得复杂。当然,这里并不是说你就不能使用null了,现实情况是很复杂的,依然会有情况下,你需要使用null值。
12、Prepared Statements
Prepared Statements很像存储过程,是一种运行在后台的SQL语句集合,我们可以从使用prepared statements获得很多好处,无论是性能问题还是安全问题。
13、无缓冲的查询
正常的情况下,当你在当你在你的脚本中执行一个SQL语句的时候,你的程序会停在那里直到没这个SQL语句返回,然后你的程序再往下继续执行。你可以使用无缓冲查询来改变这个行为。
14、把IP地址存成unsigned int
很多程序员都会创建一个VARCHAR(15) 字段来存放字符串形式的IP而不是整形的IP。如果你用整形来存放,只需要4个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当你需要使用这样的WHERE条件:IP between ip1 and ip2。
15、固定的长度的表会更快
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
16、垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。
17、拆分大的delete或insert语句
18、越小的列会更快
对于大多数的数据库引擎来说,硬盘操作可能最大的瓶颈。所以,把你的数据变得紧凑会对这样的情况非常有帮助,因为这减少了对硬盘的访问。
19、选择正确的存储引擎
MySQL中有两个存储引擎myisam和innodb,每个引擎有利也有弊。甚至你只需要update一个字段,整个表都会锁起来,而别的进程,就算是读的进程都无法操作读操作完成。另外。MySQL对于select count(*) 这类的计算超快无比。
20、使用一个对象的关系映射器
使用orm,你能够获取可靠的性能增涨,一个orm可以做的事情,也能被手动的编写出来。但是,需要一个高级专家。
21、小心“永久链接”
“永久链接” 的目的是用来重新创建MySQL链接的次数。当一个链接被创建了,它会永远在链接的状态,就算是数据库操作已经结束了。而且,自从我们的Apache开始重用它的子进程后,也就是说,下一次的http请求会重用Apache的子进程,并重用相同的MySQL链接