
在70W的数据中,执行 'name': /Mamacitas / 需要17.358767秒才完成
数据内容例:
{
"Attitude_low": NumberInt(0),
"Comments": "i",
"file": [
"mamacitas-7-scene3.avi",
"mamacitas-7-scene4.avi",
"mamacitas-7-scene5.avi",
"mamacitas-7-scene2.avi",
"mamacitas-7-scene1.avi",
"14968frontbig.jpg",
"[000397].gif",
"mamacitas-7-bonus-scene1.avi",
"14968backbig.jpg"
],
"Announce": "http://exodus.desync.com/announce",
"View": NumberInt(0),
"Hash": "9E3842903C56E8BBC0C7AF7A0A8636590491923C",
"name": "Mamacitas 7[SILVERDUST]",
"Encoding": "!",
"EntryTime": 1403169286.9712,
"Attitude_top": NumberInt(0),
"CreatedBy": "ruTorrent (PHP Class - Adrien Gibrat)",
"CreationDate": NumberInt(1365851919)
}
关于索引部分: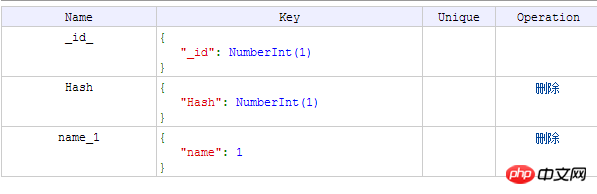
请问我该如何提高匹配速度?

怪我咯2017-04-24 09:11:39
hash 类型的索引在用模糊查询时是用不上的,的确要依赖搜索引擎类的东西专门建分词后的索引
一个是可以采用elastic search之类的东西,专门搭一个
也可以考虑采用一个分词的库把你的字段分好词,然后再用mongodb的专门弄个分词的collection,可以用mongodb的默认索引机制


