
下载了一份新浪微博的数据,但是原始数据是用csv的,在mac上没办法直接打开,读取的时候,也会错误,会出现
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x84 in position 36: invalid start byte然后自己google,发现read_csv('file', encoding = "ISO-8859-1") 这样的时候读取不会有错
但是读取进来发现是这样的:
中文全部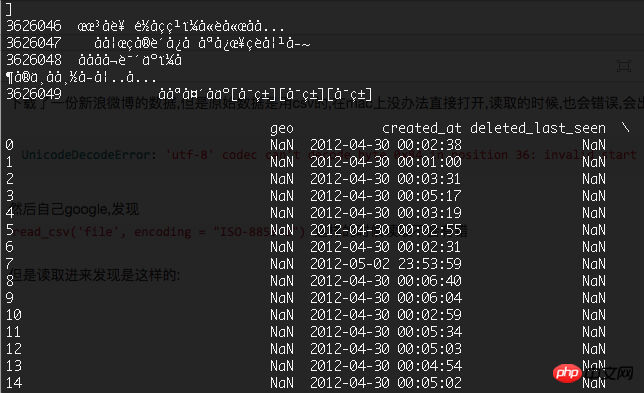
然后测试了read_csv('file', encoding = "gbk")read_csv('file', encoding = "utf8")read_csv('file', encoding = "gb18030")
总之就是各种不行~基本的情况如下:
UnicodeDecodeError: 'gb18030' codec can't decode byte 0xaf in position 12: incomplete multibyte sequence有大神遇到类似的情况吗?
有大神说要数据 因为比较大,热心的人可以看看 不过我觉得挺有用的
下面是微博的数据
链接:http://pan.baidu.com/s/1jHCOwCI 密码:x58f
补充一下代码吧~
上面随意一个文件下载下来(是csv格式的)然后用pandas打开就会出错~
import pandas
df = pandas.read_csv("week1.csv")

大家讲道理2017-04-18 10:30:36
跟你一样的情况,试了很多编码仍然没有用,但是看数据用UTF8编码的话,有的数据能转换成功,所以我暂时能想到的办法就是用open去按行读取,如果出现编码转换错误就丢掉,这样下来数据量其实也不少

高洛峰2017-04-18 10:30:36
你也可以试试用cp1252。最好的方法是先通过chardet包(https://pypi.python.org/pypi/...)看文件具体上用什么encoding。

天蓬老师2017-04-18 10:30:36
试过了没有问题呀,我猜想应该是你环境编码问题吧,可以尝试一下以下代码
#coding=utf-8
import pandas as pd
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
df = pd.read_csv('week1.csv', encoding='utf-8', nrows=10)
print df