
现在的情况:
1.数据源很大 : 设备产生的mqtt报文,通过mosquitto发布,现阶段设备量在20W(其实不到,19W接近20W的样子),上报间隔为20s,其中如果设备状态突然变化,也会发一次报文.
2.策略 : 因为报文是自定义报文,需要拆包解包,因此在flume agent处开发了特殊的source,里面集成mqtt_client,通过订阅+/#收集所有上报的日志,将报文解析成json,投放到channel,后面还接了3种sink,(1) 扔到kafka,kafaka后面是storm. (2)扔hdfs.(3)扔arvo.
3.现在的问题 :
现在flume是单agent作为source订阅全部topic的,偶尔会出现flume挂掉的情况,测试那边说是mosquitto数据发送量过大的问题.
现在mosquitto经过优化(epoll+改句柄等),单台机器就能支撑所有设备接入了,但是设备接入量可能会继续上升(现在关闭了新设备接入的业务),因此以后可能会做mosquitto集群,简单来说就是mosquitto集群会产生更大的数据量,flume
source agent负担会更重.
4.请问上面两个问题解决的思路
如何做一个flume集群,需要有这样的特点 : 这个集群中所有的数据入口(即flume source agent , 即那个mosquitto的客户端)同时只能有一个获取到数据(即并联单点问题),例如3个数据入口,不可能记录三次,而且有负载均衡的策略(机器质量不一),failover策略(服务器需要维护)

黄舟2017-04-18 10:25:58
没用过flume这种高端的东西呢。
感觉你的负载均衡,可以使用客户端的方式来做,跟redis集群模式差不多。
由客户端决定将消息提交至某个数据入口。
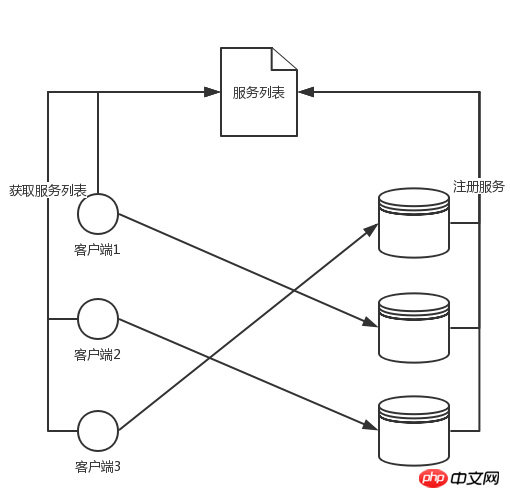
大致就如上图,将flume的服务注册在服务中心(zookeeper,consul),客户端获取服务列表,根据某个特定属性计算hash值决定目标服务,将数据提交至该服务器。flume的服务注册在服务中心(zookeeper,consul),客户端获取服务列表,根据某个特定属性计算hash值决定目标服务,将数据提交至该服务器。
如果flume出现问题down如果flume出现问题down机,此时服务中心会发现并删除对应的服务,而且客户端的服务列表中也应对应的删除。
