
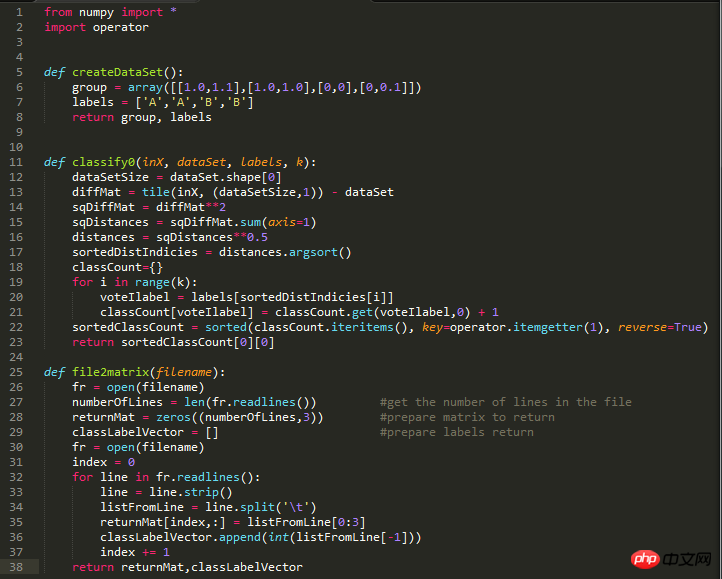
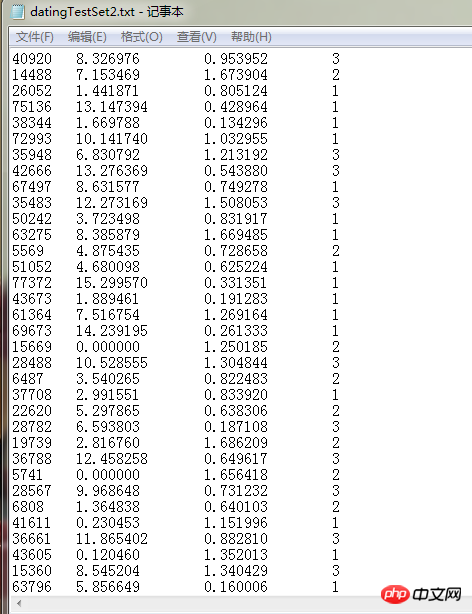
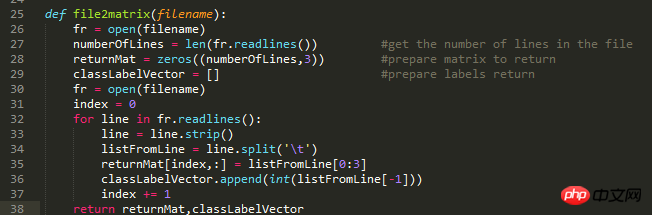
图1是学习到机器学习实战2.2.1节时,knn.py中需要的所有代码。图二是要处理的数据集合,可以看到有4列,行数很多。我的疑问是图三中33行与34行代码,既然用strip函数处理了每行的数据,那每行的空格和分行符都被去掉了,我认为经过33行代码处理后,第一行就变成了409208.3269760.9539523这个样子,这个样子的话split没办法进行划分啊?split是为了将每行中每一列的数据进行分组,保存到列表里,但是为什么不直接用split()去分?即用空格去分。给的数据每行没有制表符/t,为什么要用/t去分?
希望大家能指点一下,谢谢了。

大家讲道理2017-04-18 09:45:32
strip(...) method of builtins.str instance
S.strip([chars]) -> str
Return a copy of the string S with leading and trailing
whitespace removed.
# 首尾去空(包括\t\n\s, 只要在字串首或者尾部)
If chars is given and not None, remove characters in chars instead.
split(...) method of builtins.str instance
S.split(sep=None, maxsplit=-1) -> list of strings
# 按指定分隔符(定界符)拆分
Return a list of the words in S, using sep as the
delimiter string. If maxsplit is given, at most maxsplit
splits are done. If sep is not specified or is None, any
whitespace string is a separator and empty strings are
removed from the result.效果演示:
In[23]: a_str = " 啦啦\t咳咳\n少年\t我粉你 \t"
In[24]: a_str.strip()
Out[24]: '啦啦\t咳咳\n少年\t我粉你'
In[25]: a_str.split("\t")
Out[25]: [' 啦啦', '咳咳\n少年', '我粉你 ', '']
In[26]: a_str.strip().split("\t")
Out[26]: ['啦啦', '咳咳\n少年', '我粉你']

ringa_lee2017-04-18 09:45:32
楼上把strip的解释都写出来了
leading和trailing是指头和尾,中间的保留
此外我觉得整本书的读数据太笨拙了,用pandas一行搞定pd.read_csv('dataSet.txt', sep='t', header=None)
