伊谢尔伦2017-04-18 09:33:41
经过实测,结论是 bs4 改变了属性的顺序。
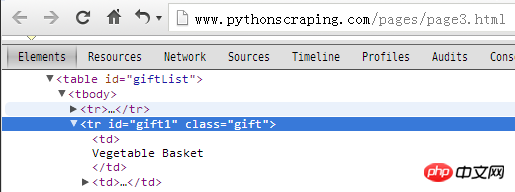
审查元素
查看网页源码
import re
ptn_tr = re.compile(r'<tr[^>]+>')
import requests as req
rsp=req.get('http://www.pythonscraping.com/pages/page3.html')
html = rsp.text
print('requests:\t', ptn_tr.findall(html)[0])
from urllib.request import urlopen
rsp = urlopen("http://www.pythonscraping.com/pages/page3.html")
html = rsp.read().decode()
print('urlopen:\t', ptn_tr.findall(html)[0])
from bs4 import BeautifulSoup
html = str(BeautifulSoup(html,"lxml"))
print('bs4Soup:\t', ptn_tr.findall(html)[0])
结果:
requests: <tr id="gift1" class="gift">
urlopen: <tr id="gift1" class="gift">
bs4Soup: <tr class="gift" id="gift1">

高洛峰2017-04-18 09:33:41
建议题主把网站甚至自己的代码贴出来,方便大家帮你调试。不一样很正常,如果你爬虫爬下来的内容保存为静态页面,和你用浏览器看到的不一样,那么肯定是对对方反爬虫机制给识别了,所以服务器会返回不同的信息。识别爬虫的方法很多,题主如果还有疑惑欢迎再问