
http://www.zjzfcg.gov.cn/cggg?pageNum=1&pageCount=30&searchKey=%E8%99%9A%E6%8B%9F%E5%8C%96&bidType=0&bidWay=0®ion=0
请看这个网站,翻页是通过ajax的,并没有刷新界面。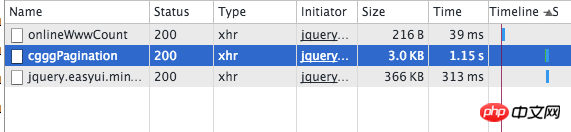
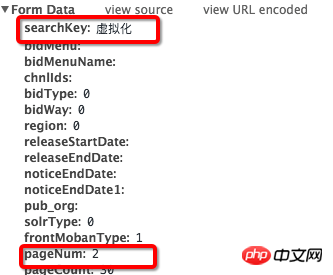
我做了爬虫想爬去上面的content,按照网上的教程,发送一个xmlhttprequest:
放一个data和一个header:
#-*- coding: UTF-8 -*-
import sys
import time
from HTMLParser import HTMLParser
import requests
import random
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf8')
def get_info(url):
info_list=[]
headers={"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 QQBrowser/3.9.3943.400"
'X-Requested-With': 'XMLHttpRequest'}
data={
"searchKey":"虚拟化",
"bidType":"0",
"bidWay":"0",
"region":"0",
"solrType":"0",
"frontMobanType":"1",
"pageNum":"2",#应该就是通过传输这个pageNum给服务器实现翻页
"pageCount":"30"
}
try:
content = requests.post(url,data=data,headers=headers).content#就是这里
#t = session.post(url,data,headers)
print content#无法print出内容,说是HTTP Status 405 - Request method 'POST' not supported
except Exception,e:
print e
return
get_info('http://www.zjzfcg.gov.cn/cggg?pageNum=1&pageCount=30&searchKey=%E5%AD%98%E5%82%A8&bidType=0&bidWay=0®ion=0')
请各位分析一波,是哪里有误?

ringa_lee2017-04-18 09:08:53
很明显,post地址错了,真正的地址是你截图选中的那条。
(回复里面插不了图,所以在这补充)
浏览器没显示完整URL信息,你需要自己看下完整地址
