
访问一个网站,点击一个链接后,通过fiddler监测到如下post内容:
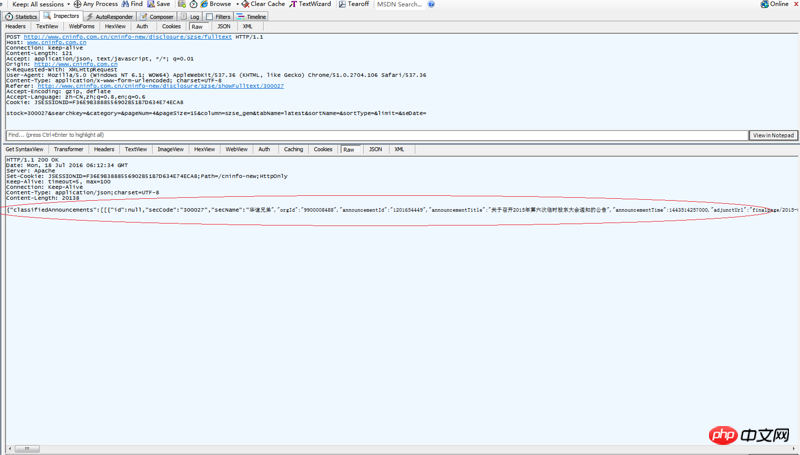
在raw中的红色圈圈标注的内容,就是我想获取的内容。这个内容在网页源代码里面是没有的,我想通过代码获取到这段内容,请问代码怎么写呢?
url = "http://www.cninfo.com.cn/information/companyinfo_n.html?fulltext?szcn300027"
data = {"stock":stockcode,
"category": "category_ndbg_szsh",
"pageNum": "1",
"pageSize":"30",
"tabName":"fulltext",
"seDate": "2011-07-11 ~ 2016-07-11"
}
backdata = requests.post(url,data=data)
raw = backdata.raw
print(raw)
我试了下上面这段代码,输出的是一个httpresponse的object,通过python的debug功能看到raw的内容如下:
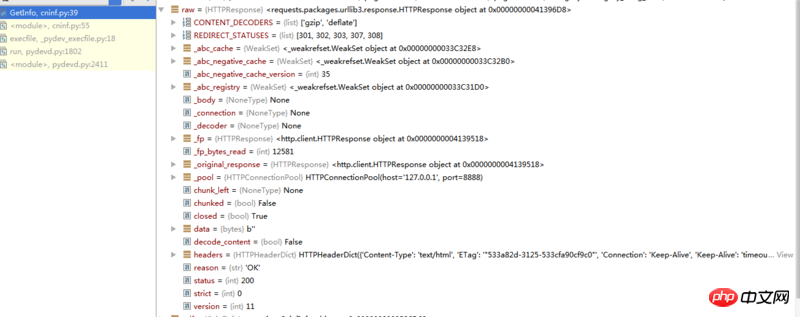
还是找不到我想要的内容(就是第一张图中红圈标注的内容),很好奇通过fiddler看得到的内容,究竟要如何用代码给抓取下来,求大神指导。

