
继承multiprocessing.Process实现了一个worker类,在父进程中,自己实现了一个最多启动N的限制(出问题的环境是30个)。
实际运行中发现,大约有万分之二(当前每天运行46000+次,大约出现11次)的概率,子进程创建后run方法未执行。
代码和日志如下,注意打印日志的语句
父进程启动子进程(父进程里还有一个控制并发进程数量的逻辑,如果需要的话我贴出来):
...
def run_task(self, task):
logging.info('execute monitor %s' % task['id'])
worker = execute_worker.ExecuteWorkerProcess(task)
logging.debug('execute process start %s' % task['id'])
worker.start()
logging.info('worker pid is %s (%s)' % (worker.pid, task['id']))
logging.debug('execute process started %s' % task['id'])
self.worker_pool.append(worker)
...子进程run方法
class ExecuteWorkerProcess(multiprocessing.Process):
...
def __init__(self, task):
super(ExecuteWorkerProcess, self).__init__()
self.stopping = False
self.task = task
self.worker = ExecuteWorker(task)
if 'task' in task:
self.routine = False
else:
self.routine = True
self.zk = None
logging.debug('process created %s' % self.task['id'])
...
def run(self):
logging.debug('process start %s' % self.task['id'])
try:
logging.debug('process run before %s' % self.task['id'])
self._run()
logging.debug('process run after %s' % self.task['id'])
except:
logging.exception('')
title = u'监控执行进程报错'
text = u'监控项id:%s\n错误信息:\n%s' % (self.task['id'], traceback.format_exc())
warning.email_warning(title, text, to_dev=True)
logging.debug('process start done %s' % self.task['id'])
...出现问题的进程日志如下: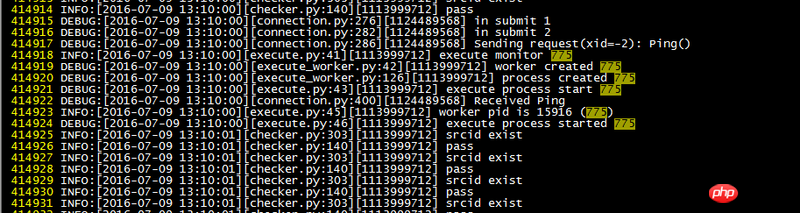
正常任务日志如下:
可以看到正常和异常的日志主进程中都打印除了子进程的pid,但是异常继承子进程run行数的第一行没有执行。
是否有人遇到过?这个是不是multiprocessing.Process的坑,有没有规避办法...

ringa_lee2017-04-18 09:06:50
原因已找到,由于主进程中使用了thread+mutiprocessing(fork),导致logging出现死锁,现象就是遇到子进程里第一句logging就hang住。问题只会发生在Linux下。
看了stckoverflow这个答案找到的复现方法,另一个回答,解决方案
复现demo:
#coding=utf-8
import os
import time
import logging
import threading
import multiprocessing
import logging.handlers
def init_log(log_path, level=logging.INFO, when="midnight", backup=7,
format="%(levelname)s:[%(asctime)s][%(filename)s:%(lineno)d][%(process)s][%(thread)d] %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"):
formatter = logging.Formatter(format, datefmt)
logger = logging.getLogger()
logger.setLevel(level)
dir = os.path.dirname(log_path)
if not os.path.isdir(dir):
os.makedirs(dir)
handler = logging.handlers.TimedRotatingFileHandler(log_path + ".log",
when=when,
backupCount=backup)
handler.setLevel(level)
handler.setFormatter(formatter)
logger.addHandler(handler)
stop = False
class Worker(multiprocessing.Process):
u"""
多进程方式执行任务,使用CPU密集型
"""
def __init__(self):
super(Worker, self).__init__()
self.reset_ts = time.time() + 3
self.stopping = False
def run(self):
logging.info('Process pid is %s' % os.getpid())
def check_timeout(self, now):
u"""
若当前时间已超过复位时间,则结束进程
:param now:
:return:
"""
global stop
if now > self.reset_ts and not self.stopping:
self.stopping = True
logging.info('error pid is %s' % os.getpid())
stop = True
def main():
global stop
worker_pool = []
while 1:
if worker_pool:
now = time.time()
for worker in worker_pool:
worker.check_timeout(now)
if stop:
logging.error('Process not run, exit!')
exit(-1)
alive_workers = [worker for worker in worker_pool if worker.is_alive()]
over_workers = list(set(alive_workers) ^ set(worker_pool))
for over_worker in over_workers:
over_worker.join()
worker_pool = alive_workers
if len(worker_pool) < 1000:
logging.info('create worker')
worker = Worker()
worker.start()
logging.info('worker pid is %s' % worker.pid)
worker_pool.append(worker)
time.sleep(0.001)
class ExecuteThread(threading.Thread):
def run(self):
main()
class ExecuteThread2(threading.Thread):
def run(self):
global stop
while 1:
logging.info('main thread')
time.sleep(0.001)
if stop:
exit(-1)
if __name__ == '__main__':
init_log('/yourpath/timeout')
#main()
thread = ExecuteThread()
thread2 = ExecuteThread2()
thread.start()
thread2.start()
thread.join()
thread2.join()
复现完了记得清掉hang住的进程....