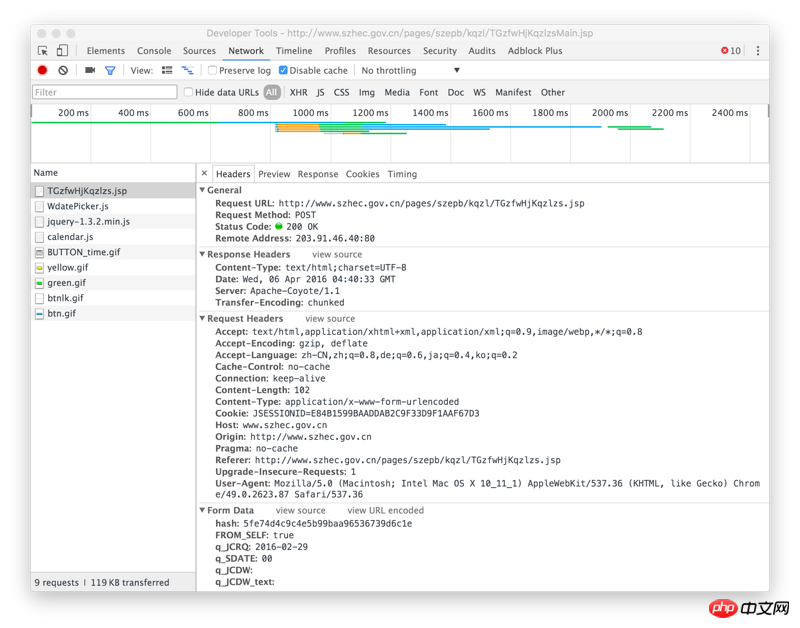
需要用到这方面的数据,单独一页一页的复制了一段时间的数据,发现很是耗时,想从深圳市环保局下载空气质量历史数据。选择日期后,页面出现一个相应的数据表格,每天有24个时间点的。需要将每一天每一个小时的数据都爬下来。页面如下:
网址:http://www.szhec.gov.cn/pages/szepb/kqzl...
麻烦大家

黄舟2017-04-17 17:35:12
使用requests.post请求
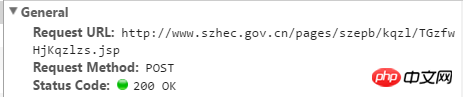
上图的URL
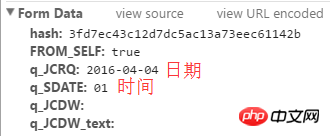
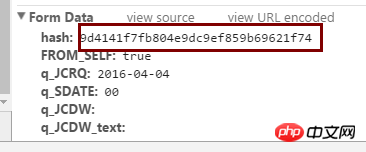

hash值在上图的位置。
该图是response
#coding=utf-8
import requests
from bs4 import BeautifulSoup
get_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp?FLAG=FIRSTFW"#获取hash值
post_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp" #获取空气质量时报
html=requests.get(get_url)
#使用beautiful解析网页,获取hash值
html_soup=BeautifulSoup(html.text,"html.parser")
hash=html_soup.select("input[name=hash]")
hash=hash[0].get('value')
#构造data
data={
'hash':hash,
'FROM_SELF':'true',
'q_JCRQ':'2016-04-01',
'q_SDATE':'00',
'q_JCDW':'',
'q_JCDW_text':'',}
#至此已经正确获取了控制质量时报的信息
tqHtml=requests.post(post_url,data=data)
print tqHtml.text


PHPz2017-04-17 17:35:12
接上:
我大概用了这段代码试了下,程序既不报错也没有结果。请问错在哪?
import requests
import xlwt
from bs4 import BeautifulSoup
import datetime
import tqdm
def datelist(start, end):
start_date = datetime.datetime(*start)
end_date = datetime.datetime(*end)
result = []
curr_date = start_date
while curr_date != end_date:
result.append("%04d-%02d-%02d-%02d" % (curr_date.year, curr_date.month, curr_date.day,curr_date.hour))
return result
def get_html():
global h
s = requests.session()
url = 'http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp'
headers = {
'User-Agent':'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_0_1 like Mac OS X; ja-jp) AppleWebKit/532.9 (KHTML, like Gecko) Version/4.0.5 Mobile/8A306 Safari/6531.22.7',
'Referer':'http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp',
'Host':'www.szhec.gov.cn',
'Cookie':'JSESSIONID=1F7389E70413F613C3A166D8F5A963C4',
'Connection':'keep-alive',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
r = s.post(url, data=dt, headers=headers)
h = r.content.decode('utf-8')
def get_excel():
book = xlwt.Workbook(encoding = 'utf-8',style_compression=0)
sheet = book.add_sheet('data',cell_overwrite_ok = True)
global dt
j = 0
for each in datelist((2016, 3, 1,0), (2016, 3, 31,23)):
dt = {'cdateEnd':each,'pageNo1':'1','pageNo2':''}
get_html()
soup = BeautifulSoup(h, "html.parser")
#j = 0
for tabb in soup.find_all('tr'):
i=0;
for tdd in tabb.find_all('td'):
#print (tdd.get_text()+",",)
sheet.write(j,i,tdd.get_text())
i = i+1
j=j+1
book.save(r'.\re'+each+'.xls')get_excel()