
我使用anaconda 的 jupyter来跑代码,
在我使用requests模块来来读取网页,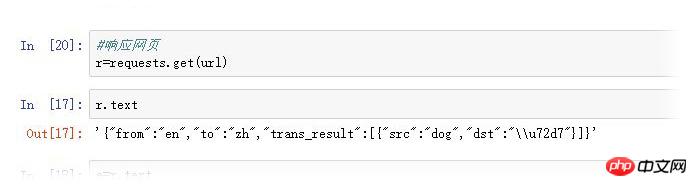
看到输出内容在大括号内,判断是字典,就用来dict的函数来读取值,却失败了。
type()发现它的属性发现是str
我用json后,却发现属性又变成dict。
当程序把这类字典形式的内容当字符串来读取时候,
该如何让他们重新变成字典属性?
習慣沉默2017-06-12 09:23:24
请楼主以后发问多利用 <> 编辑按钮加入代码,方便别人试代码。
试试以下代码:
x = eval(r.text)
y = r.json()
print (type(x), type(y))
print (x==y)结果应该是两个都是字典,而且内容一致。换句话说:
x = eval(r.text)
y = r.json() x 是把r.text的字符串直接当成表述句expressions执行了,产生一字典
y 是r.json()方法传回的json物件,产生一字典
所以你的问题是:
「当程序把这类字典形式的内容当字符串来读取时候,该如何让他们重新变成字典属性?」
可以比较精确的改问为:
「字符串中为一个字典形式的表述句,该如何将字符串变成字典?」
那么答案就是内置函数eval()
当然,requests模块本来就有.json()方法,你本来就可以用的


