
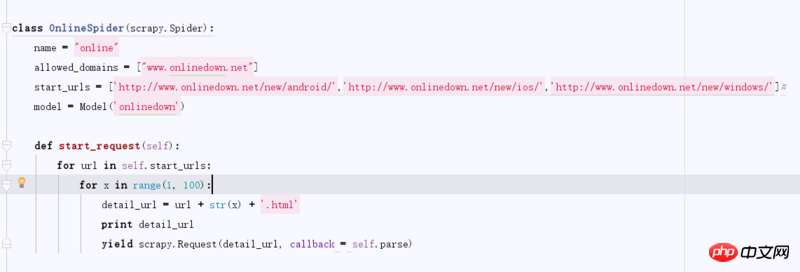
class OnlineSpider(scrapy.Spider):
name = "online"
allowed_domains = ["www.onlinedown.net"]
start_urls = ['http://www.onlinedown.net/new/android/','http://www.onlinedown.net/new/ios/','http://www.onlinedown.net/new/windows/']#
model = Model('onlinedown')
def start_request(self):
for url in self.start_urls:
for x in range(1, 100):
detail_url = url + str(x) + '.html'
print detail_url
yield scrapy.Request(detail_url, callback = self.parse)
每页是35条,结果是105条。这是为什么呢。

