
我写了一个70行左右的python小程序,用来计算文档的相似性。
材料是88篇论文文档,用到了gensim包。
程序的流程是预处理文档(删去不必要的符号,分词等),计算文档的tfidf值,建立88篇论文的tfidf模型以及模型索引。到这里程序运行都是正常的,但是在使用索引的时候,报错: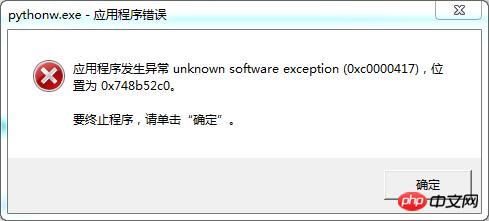
请问这是什么原因引起的呢?谢谢~
以下是部分运行没有问题的源代码:
#分词:
texts = [[word for word in document.split()]for document in documents]
#利用所有文档,创建词典
dictionary = corpora.Dictionary(texts)
#创建语料
corpus = [dictionary.doc2bow(text) for text in texts]
#利用这些语料,创建tfidf模型
tfidf_model = models.TfidfModel(corpus)
#计算每个文档的tfidf
tfidfs = tfidf_model[corpus]
#创建tfidf的索引
index = similarities.SparseMatrixSimilarity(tfidfs,num_features=88075)运行这个代码时出现了问题:
#创建目标文档的语料
content = 'A student of music needs as long and as arduous a training to become a performer as a medical student needs to become a doctor'
content = content.lower().split()
test = dictionary.doc2bow(content)
#计算目标文档的tfidf
test_tfidf = tfidf_model[test]
sims = index[test_tfidf]#**就是这一句出现了问题!**
ringa_lee2017-05-18 10:49:38
你的python版本?当前 gensim的版本?是否和官网测试过的稳定版一致?还有,建议使用类Unix系统,gensim基于 NumPy 和 Scipy,这两者在win上都不好安装吧,安装好了也不见得不会出问题
曾经蜡笔没有小新2017-05-18 10:49:38
这种错误也有可能是Windows操作系统的锅,你把代码复制到Google一下会发现很多解决方案,比如这个:
