
 < /p>
< /p>
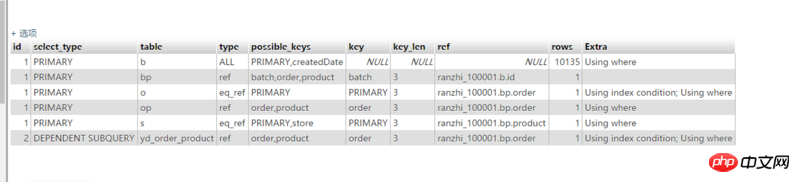
sql语句是:
解释一下 SELECT bp.amount / (select count(*) from yd_order_product where order = bp.order and Product = bp.product ) 作为金额,s.costprice 作为价格,s.store,b.type 来自 yd_batch_product 作为 bp left 将 yd_order_product 作为 op on op.order = bp.order 和 op.product = bp.product left join yd_batch as b on bp.batch = b.id left join yd_order as o on bp.order = o .id left join yd_stock as s on bp.product = s.id where o.deleted = '0'和 s.forbidden = '0' 和 b.createdDate 之间 '2015-10-13 00:00:00' 和'2017-04-30 23:59:59' 和 s.store 在 (1,2,3,4,5,6) 和 s.chainID = 1
请问这个第一行的类型值为什么会是ALL
巴扎黑2017-05-16 13:15:12
@TroyLiu ,你给的建议,创建的索引太多了,建立order/product/batch/amount组合索引的思路感觉不对。
sql优化的核心思路是,对大数据的表能够尽量根据已有的where语句中的条件对数据进行过滤,在这个例子中:
yd_batch_product表的数量量应该是最大的,但在where语句中没有过滤条件,导致执行效率较差。
出现“Using temporary; Using filesort”的原因是,group by中的字段,不完全在第一个表yd_batch_product表字段范围内。
建议:
1、yd_batch/yd_order/yd_stock用的是LEFT JOIN,但是在where语句中有这些表字段的过滤条件,因此和INNER JOIN是等价的,因此连接方式可以改成INNER JOIN,这样mysql在判断执行计划的时候,就不是只能先查询yd_batch_product 表了。
2、yd_batch表的createdDate字段建立索引,看执行计划中第一个驱动表是否有变化,如果createdDate的条件过滤性很强,执行计划中第一个表应该是yd_batch。
3、yd_stock表,如何store和chainID组合后过滤性强,可以建立组合索引,和上一步同样判断执行计划是否有变化。
当然,最理想的情况是从业务和数据出发,能找出yd_batch_product表上能大量过滤数据的条件,然后根据这个条件创建索引。如yd_batch表的createdDate字段在yd_batch_product表上也有类似的冗余字段,就使用这个字段创建索引。
更新问题后的建议:
1、TYPE=ALL表示用的是全表扫描,虽然createdDate已经创建索引,但数据库评估后认为使用全表扫描的成本更低,总体上认为是正常(createdDate的范围较大,含一年多数据数,共1万多条)。如果想用索引可以把范围缩小的几天内,看执行计划是否有变化。当然也可以使用提示强制使用索引,但效率就不一定高了。
2、yd_order_product表查询了两次,尤其是在执行计划中select的子查询,应该尽量避免。

阿神2017-05-16 13:15:12
首先 yd_batch_product 表里面数据量很大,而且没有正确建立索引,导致整个查询没有利用到索引。
由 table bp 的对应 key 列为 NULL 可以看出。
优化参考:
为 yd_batch_product 表在 order/product/batch/amount 列上建立联合索引,注意联合索引顺序.(amount 也添加到索引里面,为的是使用覆盖索引)
如果 yd_batch_product 没有其他的查询,则考虑删除表上所有的单列索引。
yd_stock 表在 forbidden/store/chainID 列上建立联合索引(注意索引顺序)。
yd_order 表在 deleted 列上建立单列索引。
yd_batch 表在 createdDate 列上建立单列索引。
根据目前的分析,可以做以上的优化。
由于没有数据表做测试,如有错误,请指正。