


Python爬虫获取数据的方法
Python爬虫可以通过请求库发送HTTP请求、解析库解析HTML、正则表达式提取数据,或使用数据抓取框架来获取数据。更多关于Python爬虫相关知识。详情阅读本专题下面的文章。php中文网欢迎大家前来学习。
 159
159 12
12
Python爬虫获取数据的方法

Python爬虫获取数据的方法
Python爬虫可以通过请求库发送HTTP请求、解析库解析HTML、正则表达式提取数据,或使用数据抓取框架来获取数据。详细介绍:1、请求库发送HTTP请求,如Requests、urllib等;2、解析库解析HTML,如BeautifulSoup、lxml等;3、正则表达式提取数据,正则表达式是一种用来描述字符串模式的工具,可以通过匹配模式来提取出符合要求的数据等等。
Nov 13, 2023 am 10:44 AM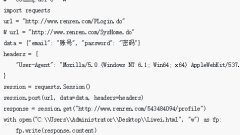
requests库的基本使用
1. response.content和response.text的区别response.content是编码后的byte类型(“str”数据类型),response.text是unicode类型。这两种方法的使用要视情况而定。注意:unicode -> str 是编码过程(encode()); str -> unicode 是解码过程(decode())。示例如下:# --codin...
Jun 11, 2018 pm 10:55 PM
Python网络爬虫requests库怎么使用
1.什么是网络爬虫简单来说,就是构建一个程序,以自动化的方式从网络上下载、解析和组织数据。就像我们浏览网页的时候,对于我们感兴趣的内容我们会复制粘贴到自己的笔记本中,方便下次阅读浏览——网络爬虫帮我们自动完成这些内容当然如果遇到一些无法复制粘贴的网站——网络爬虫就更能显示它的力量了为什么需要网络爬虫当我们需要做一些数据分析的时候——而很多时候这些数据存储在网页中,手动下载需要花
May 15, 2023 am 10:34 AM
一篇文章带你搞定Python中urllib库(操作URL)
使用Python语言,能够帮助大家更好的学习Python。urllib提供的功能就是利用程序去执行各种HTTP请求。如果要模拟浏览器完成特定功能,需要把请求伪装成浏览器。伪装的方法是先监控浏j览器发出的请求,再根据浏览器的请求头来伪装,User-Agent头就是用来标识浏览器的。
Jul 25, 2023 pm 02:08 PM
python3.6想使用urllib2包怎么办
Pyhton2中的urllib2工具包,在Python3中分拆成了urllib.request和urllib.error两个包。就导致找不到包,同时也没办法安装。所以安装这两个包,导入时即可使用方法。
Jul 01, 2019 pm 02:18 PM
Python 2.x 中如何使用urllib.urlopen()函数发送GET请求
Python是一种流行的编程语言,广泛用于Web开发、数据分析和自动化任务等领域。在Python2.x版本中,使用urllib库的urlopen()函数可以方便地发送GET请求和获取响应数据。本文将详细介绍在Python2.x中如何使用urlopen()函数发送GET请求,并提供相应的代码示例。在使用urlopen()函数发送GET请求之前,我们首先需要
Jul 29, 2023 am 08:48 AM
详解Python之urllib爬虫、request模块和parse模块
urllib是Python中用来处理URL的工具包,本文利用该工具包进行爬虫开发讲解,毕竟爬虫应用开发在Web互联网数据采集中十分重要。文章目录urllibrequest模块访问URLRequest类其他类parse模块解析URL转义URLrobots.txt文件
Mar 21, 2021 pm 03:15 PM
python beautifulsoup4模块怎么用
一、BeautifulSoup4基础知识补充BeautifulSoup4是一款python解析库,主要用于解析HTML和XML,在爬虫知识体系中解析HTML会比较多一些,该库安装命令如下:pipinstallbeautifulsoup4BeautifulSoup在解析数据时,需依赖第三方解析器,常用解析器与优势如下所示:python标准库html.parser:python内置标准库,容错能力强;lxml解析器:速度快,容错能力强;html5lib:容错性最强,解析方式与浏览器一致。接下来用一段
May 11, 2023 pm 10:31 PM
一文搞懂Python爬虫解析器BeautifulSoup4
本篇文章给大家带来了关于Python的相关知识,其中主要整理了爬虫解析器BeautifulSoup4的相关问题,Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方式,下面一起来看一下,希望对大家有帮助。
Jul 12, 2022 pm 04:56 PM
Python爬虫之怎么使用BeautifulSoup和Requests抓取网页数据
一、简介网络爬虫的实现原理可以归纳为以下几个步骤:发送HTTP请求:网络爬虫通过向目标网站发送HTTP请求(通常为GET请求)获取网页内容。在Python中,可以使用requests库发送HTTP请求。解析HTML:收到目标网站的响应后,爬虫需要解析HTML内容以提取有用信息。HTML是一种用于描述网页结构的标记语言,它由一系列嵌套的标签组成。爬虫可以根据这些标签和属性定位和提取需要的数据。在Python中,可以使用BeautifulSoup、lxml等库解析HTML。数据提取:解析HTML后,
Apr 29, 2023 pm 12:52 PM
Python正则表达式 - 检查输入是否为浮点数
浮点数在从数学计算到数据分析的各种编程任务中发挥着至关重要的作用。然而,当处理用户输入或来自外部源的数据时,验证输入是否是有效的浮点数变得至关重要。Python提供了强大的工具来应对这一挑战,其中一个工具就是正则表达式。在本文中,我们将探讨如何在Python中使用正则表达式来检查输入是否为浮点数。正则表达式(通常称为regex)提供了一种简洁灵活的方式来定义模式并在文本中搜索匹配项。通过利用正则表达式,我们可以构建一个与浮点数格式精确匹配的模式,并相应地验证输入。在本文中,我们将探讨如何在Pyt
Sep 15, 2023 pm 04:09 PM

热门文章

热工具
Kits AI
用人工智能艺术家的声音改变你的声音。创建并训练您自己的人工智能语音模型。
SOUNDRAW - AI Music Generator
使用 SOUNDRAW 的 AI 音乐生成器轻松为视频、电影等创作音乐。
Web ChatGPT.ai
使用OpenAI聊天机器人免费的Chrome Extension,以进行有效的浏览。
LoveChat
最高质量的AI聊天,令人惊叹的视觉效果,多合一平台
Regrow AI
使用自定义诊断的AI平台跟踪和重生头发。

