



想尝试爬下北邮人的论坛,但是看到页面的源代码都是js,几乎没有我想要的信息。
回复内容:
今天偶然发现了PyV8这个东西,感觉就是你想要的。它直接搭建了一个js运行环境,这意味着你可以直接在python里面执行页面上的js代码来获取你需要的内容。
参考:
http://www.silverna.org/blog/?p=252
https://code.google.com/p/pyv8/ 我是直接看js源码,分析完,然后爬的。
例如看页面是用Ajax请求一个JSON文件,我就先爬那个页面,获取Ajax所需的参数,然后直接请求JSON页,然后解码,再处理数据并入库。
如果你直接运行页面上所有js(就像浏览器做的那样),然后获取最终的HTML DOM树,这样的性能非常地糟糕,不建议使用这样的方法。因为Python和js性能本身都很差,如果这样做,会消耗大量CPU资源并且最终只能获得极低的抓取效率。 js代码是需要js引擎运行的,Python只能通过HTTP请求获取到HTML、CSS、JS原始代码而已。
不知道有没有用Python编写的JS引擎,估计需求不大。
我一般用PhantomJS、CasperJS这些引擎来做浏览器抓取。
直接在其中写JS代码来做DOM操控、分析,以文件方式输出结果。
让Python去调用该程序,通过读文件方式获得内容。 去年还真爬过这样的数据,因为赶时间,我的方法就比较丑陋了。
PyQt有一个具体的库来模拟浏览器请求和行为(好像是webkit,忘记了,查一下就好。使用时就几行代码就够了),在一次运行程序中,第一次(只有第一次)的返回结果是js运行之后的代码。于是写了一个py脚本做一次访问解析,然后再写了windows脚本通过传递命令行参数循环这个py脚本,最后搞到数据。
方法dirty了些,不过数据拿到了就好~ 针对某网站的,可以自己看网络请求找到返回实际内容的那些有针对性地发。如果是通用的,得用 headless browser 了,比如 PhantomJS。 又一个爬北邮人论坛的。。
文艺的方法,上浏览器引擎,比如 PhantomJS ,用它导出 html,再对html用 python 解析。千万别直接 PhantomJS 解析,虽然我知道这很容易,为什么?
普通的方法,分析 AJAX 请求。即使它是 JS 渲染的,数据还是通过 HTTP 协议传输的。什么?你模拟不出来?
X-Requested-With:XMLHttpRequest
这里举个栗子:拉勾网的职位列表
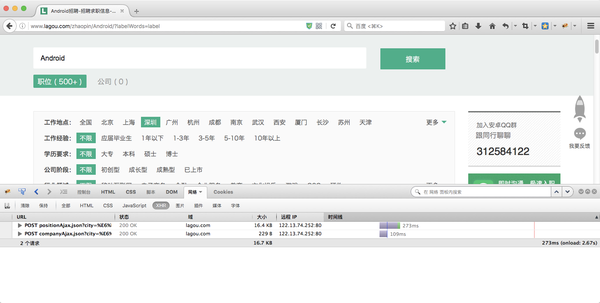

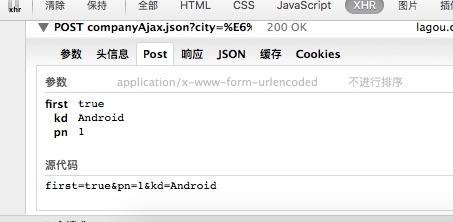
点击了Android之后 我们从浏览器上传了几个参数到拉勾的服务器
一个是 first =true, 一个是kd = android, (关键字) 一个是pn =1 (page number 页码)
所以我们就可以模仿这一个步骤来构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这是一个很久以前的问题,题主似乎也已经解决的这个问题。但是看到好多答案的办法有点太重了,这里分享一个效率更优、资源占用更低的方法。由于题主并没有指明需要什么,这里的示例取首页所有帖子的链接和标题。首先请一定记住,浏览器环境对内存和CPU的消耗都非常严重,模拟浏览器环境的爬虫代码要尽可能避免。请记住,对于一些前端渲染的网页,虽然在HTML源码中看不到我们需要的数据,但是更大的可能是它会通过另一个请求拿到纯数据(很大可能以JSON格式存在),我们不但不需要模拟浏览器,反而可以省去解析HTML的消耗。
然后,打开北邮人论坛的首页,发现它的首页HTML源码中确实没有页面所显示文章的内容,那么,很可能这是通过JS异步加载到页面的。通过浏览器开发工具(Chrome浏览器在OS X下通过command+option+i或Win/Linux下通过F12)分析在加载首页的时候请求,容易发现,如下截图中的请求:
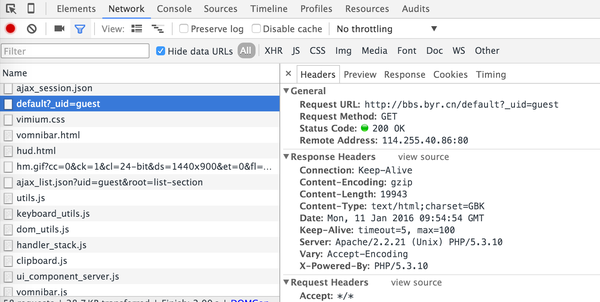 截图中选中的请求得到的response即是首页的文章链接,在preview选项中可以看到渲染后的预览图:
截图中选中的请求得到的response即是首页的文章链接,在preview选项中可以看到渲染后的预览图: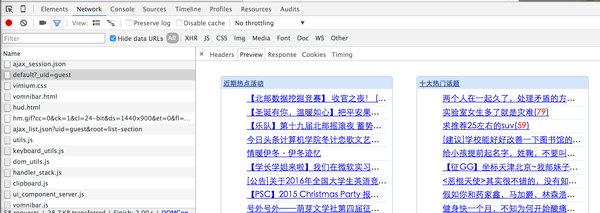 至此,我们确定这个链接可以拿到首页的文章及链接。
至此,我们确定这个链接可以拿到首页的文章及链接。在headers选项中,有这次请求的请求头及请求参数,我们通过Python模拟这次请求,即可拿到相同的响应。再配合BeautifulSoup等库解析HTML,即可得到相应的内容了。
对于如何模拟请求和如何解析HTML,请移步我的专栏,有详细的介绍,这里便不再赘述。
通过这样的方式可以不用模拟浏览器环境来抓取数据,对内存和CPU消耗、抓取速度都有很大的提升。在编写爬虫的时候,请务必记得,如非必要,不要模拟浏览器环境。 如果是在windows下,可以尝试调用windows系统中的webbrowser控件。另外ie本身也提供了接口。不过这两种方式都要渲染页面,性能上多少有点浪费,为了加快速度可以把ie的图片下载显示关闭掉,然后通过click等方法来模拟真实行为。 Google Phantom JS

 Python和时间:充分利用您的学习时间Apr 14, 2025 am 12:02 AM
Python和时间:充分利用您的学习时间Apr 14, 2025 am 12:02 AM要在有限的时间内最大化学习Python的效率,可以使用Python的datetime、time和schedule模块。1.datetime模块用于记录和规划学习时间。2.time模块帮助设置学习和休息时间。3.schedule模块自动化安排每周学习任务。
 Python:游戏,Guis等Apr 13, 2025 am 12:14 AM
Python:游戏,Guis等Apr 13, 2025 am 12:14 AMPython在游戏和GUI开发中表现出色。1)游戏开发使用Pygame,提供绘图、音频等功能,适合创建2D游戏。2)GUI开发可选择Tkinter或PyQt,Tkinter简单易用,PyQt功能丰富,适合专业开发。
 Python vs.C:申请和用例Apr 12, 2025 am 12:01 AM
Python vs.C:申请和用例Apr 12, 2025 am 12:01 AMPython适合数据科学、Web开发和自动化任务,而C 适用于系统编程、游戏开发和嵌入式系统。 Python以简洁和强大的生态系统着称,C 则以高性能和底层控制能力闻名。
 2小时的Python计划:一种现实的方法Apr 11, 2025 am 12:04 AM
2小时的Python计划:一种现实的方法Apr 11, 2025 am 12:04 AM2小时内可以学会Python的基本编程概念和技能。1.学习变量和数据类型,2.掌握控制流(条件语句和循环),3.理解函数的定义和使用,4.通过简单示例和代码片段快速上手Python编程。
 Python:探索其主要应用程序Apr 10, 2025 am 09:41 AM
Python:探索其主要应用程序Apr 10, 2025 am 09:41 AMPython在web开发、数据科学、机器学习、自动化和脚本编写等领域有广泛应用。1)在web开发中,Django和Flask框架简化了开发过程。2)数据科学和机器学习领域,NumPy、Pandas、Scikit-learn和TensorFlow库提供了强大支持。3)自动化和脚本编写方面,Python适用于自动化测试和系统管理等任务。
 您可以在2小时内学到多少python?Apr 09, 2025 pm 04:33 PM
您可以在2小时内学到多少python?Apr 09, 2025 pm 04:33 PM两小时内可以学到Python的基础知识。1.学习变量和数据类型,2.掌握控制结构如if语句和循环,3.了解函数的定义和使用。这些将帮助你开始编写简单的Python程序。
 如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?Apr 02, 2025 am 07:18 AM
如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?Apr 02, 2025 am 07:18 AM如何在10小时内教计算机小白编程基础?如果你只有10个小时来教计算机小白一些编程知识,你会选择教些什么�...
 如何在使用 Fiddler Everywhere 进行中间人读取时避免被浏览器检测到?Apr 02, 2025 am 07:15 AM
如何在使用 Fiddler Everywhere 进行中间人读取时避免被浏览器检测到?Apr 02, 2025 am 07:15 AM使用FiddlerEverywhere进行中间人读取时如何避免被检测到当你使用FiddlerEverywhere...


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

