


早听说用python做网络爬虫非常方便,正好这几天单位也有这样的需求,需要登陆XX网站下载部分文档,于是自己亲身试验了一番,效果还不错。
本例所登录的某网站需要提供用户名,密码和验证码,在此使用了python的urllib2直接登录网站并处理网站的Cookie。
Cookie的工作原理:
Cookie由服务端生成,然后发送给浏览器,浏览器会将Cookie保存在某个目录下的文本文件中。在下次请求同一网站时,会发送该Cookie给服务器,这样服务器就知道该用户是否合法以及是否需要重新登录。
Python提供了基本的cookielib库,在首次访问某页面时,cookie便会自动保存下来,之后访问其它页面便都会带有正常登录的Cookie了。
原理:
(1)激活cookie功能
(2)反“反盗链”,伪装成浏览器访问
(3)访问验证码链接,并将验证码图片下载到本地
(4)验证码的识别方案网上较多,python也有自己的图像处理库,此例调用了火车头采集器的OCR识别接口。
(5)表单的处理,可用fiddler等抓包工具获取需要提交的参数
(6)生成需要提交的数据,生成http请求并发送
(7)根据返回的js页面判断是否登陆成功
(8)登陆成功后下载其它页面
此例中使用多个账号轮询登陆,每个账号下载3个页面。
下载网址因为某些问题,就不透露了。
以下是部分代码:
#!usr/bin/env python
#-*- coding: utf-8 -*-
import os
import urllib2
import urllib
import cookielib
import xml.etree.ElementTree as ET
#-----------------------------------------------------------------------------
# Login in www.***.com.cn
def ChinaBiddingLogin(url, username, password):
# Enable cookie support for urllib2
cookiejar=cookielib.CookieJar()
urlopener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cookiejar))
urllib2.install_opener(urlopener)
urlopener.addheaders.append(('Referer', 'http://www.chinabidding.com.cn/zbw/login/login.jsp'))
urlopener.addheaders.append(('Accept-Language', 'zh-CN'))
urlopener.addheaders.append(('Host', 'www.chinabidding.com.cn'))
urlopener.addheaders.append(('User-Agent', 'Mozilla/5.0 (compatible; MISE 9.0; Windows NT 6.1); Trident/5.0'))
urlopener.addheaders.append(('Connection', 'Keep-Alive'))
print 'XXX Login......'
imgurl=r'http://www.*****.com.cn/zbw/login/image.jsp'
DownloadFile(imgurl, urlopener)
authcode=raw_input('Please enter the authcode:')
#authcode=VerifyingCodeRecognization(r"http://192.168.0.106/images/code.jpg")
# Send login/password to the site and get the session cookie
values={'login_id':username, 'opl':'op_login', 'login_passwd':password, 'login_check':authcode}
urlcontent=urlopener.open(urllib2.Request(url, urllib.urlencode(values)))
page=urlcontent.read(500000)
# Make sure we are logged in, check the returned page content
if page.find('login.jsp')!=-1:
print 'Login failed with username=%s, password=%s and authcode=%s' \
% (username, password, authcode)
return False
else:
print 'Login succeeded!'
return True
#-----------------------------------------------------------------------------
# Download from fileUrl then save to fileToSave
# Note: the fileUrl must be a valid file
def DownloadFile(fileUrl, urlopener):
isDownOk=False
try:
if fileUrl:
outfile=open(r'/var/www/images/code.jpg', 'w')
outfile.write(urlopener.open(urllib2.Request(fileUrl)).read())
outfile.close()
isDownOK=True
else:
print 'ERROR: fileUrl is NULL!'
except:
isDownOK=False
return isDownOK
#------------------------------------------------------------------------------
# Verifying code recoginization
def VerifyingCodeRecognization(imgurl):
url=r'http://192.168.0.119:800/api?'
user='admin'
pwd='admin'
model='ocr'
ocrfile='cbi'
values={'user':user, 'pwd':pwd, 'model':model, 'ocrfile':ocrfile, 'imgurl':imgurl}
data=urllib.urlencode(values)
try:
url+=data
urlcontent=urllib2.urlopen(url)
except IOError:
print '***ERROR: invalid URL (%s)' % url
page=urlcontent.read(500000)
# Parse the xml data and get the verifying code
root=ET.fromstring(page)
node_find=root.find('AddField')
authcode=node_find.attrib['data']
return authcode
#------------------------------------------------------------------------------
# Read users from configure file
def ReadUsersFromFile(filename):
users={}
for eachLine in open(filename, 'r'):
info=[w for w in eachLine.strip().split()]
if len(info)==2:
users[info[0]]=info[1]
return users
#------------------------------------------------------------------------------
def main():
login_page=r'http://www.***.com.cnlogin/login.jsp'
download_page=r'http://www.***.com.cn***/***?record_id='
start_id=8593330
end_id=8595000
now_id=start_id
Users=ReadUsersFromFile('users.conf')
while True:
for key in Users:
if ChinaBiddingLogin(login_page, key, Users[key]):
for i in range(3):
pageUrl=download_page+'%d' % now_id
urlcontent=urllib2.urlopen(pageUrl)
filepath='./download/%s.html' % now_id
f=open(filepath, 'w')
f.write(urlcontent.read(500000))
f.close()
now_id+=1
else:
continue
#------------------------------------------------------------------------------
if __name__=='__main__':
main()

 手机为什么收不到验证码Aug 17, 2023 pm 02:49 PM
手机为什么收不到验证码Aug 17, 2023 pm 02:49 PM手机收不到验证码是网络问题、手机设置问题、手机运营商问题和个人设置问题导致的。详情介绍:1、网络问题,手机所处的网络环境不稳定或者信号弱,就有可能导致验证码无法及时送达;2、手机设置问题,不小心将手机的短信或语音功能关闭,或者将验证码的发送号码加入到黑名单中,从而导致验证码无法正常收到;3、手机运营商问题,手机运营商可能会出现故障或者维护,导致验证码无法及时送达等等。
 PHP图片处理案例:如何实现图片的验证码功能Aug 17, 2023 pm 12:09 PM
PHP图片处理案例:如何实现图片的验证码功能Aug 17, 2023 pm 12:09 PMPHP图片处理案例:如何实现图片的验证码功能随着互联网的快速发展,验证码成为了保护网站安全的重要手段之一。验证码是一种通过图像识别技术来确定用户是否为真实用户的验证方式。本文将介绍如何使用PHP来实现图片的验证码功能,并附带代码示例。简介验证码是一张包含随机字符的图片,用户需要输入图片中的字符才能通过验证。实现验证码的主要过程包括生成随机字符、绘制字符到图片
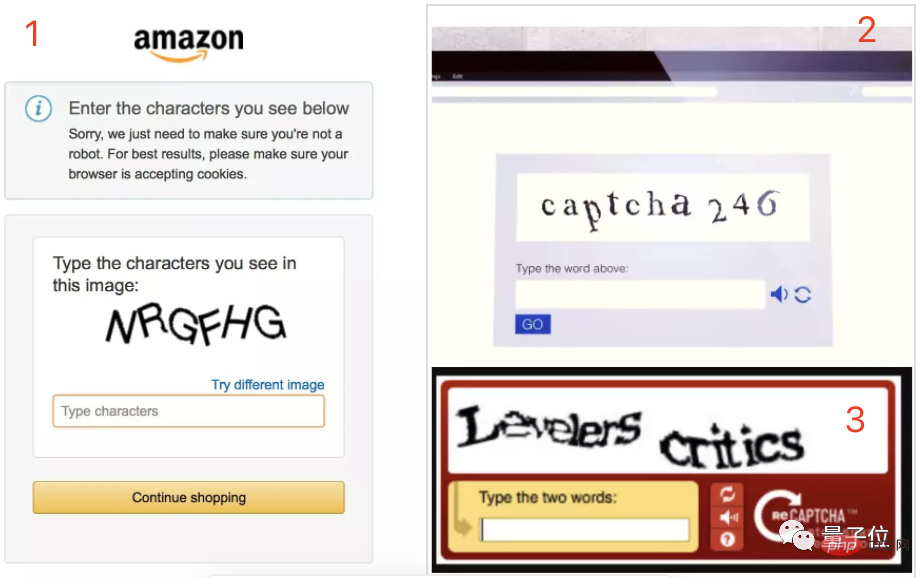 验证码拦不住机器人了!谷歌AI已能精准识别模糊文字,GPT-4则装瞎求人帮忙Apr 12, 2023 am 09:46 AM
验证码拦不住机器人了!谷歌AI已能精准识别模糊文字,GPT-4则装瞎求人帮忙Apr 12, 2023 am 09:46 AM“最烦登网站时各种奇奇怪怪(甚至变态)的验证码了。”现在,有一个好消息和一个坏消息。好消息就是:AI可以帮你代劳这件事了。不信你瞧,以下是三张识别难度依次递增的真实案例:而这些是一个名为“Pix2Struct”的模型给出的答案:全部准确无误、一字不差有没有?有网友感叹:确定,准确性比我强。所以可不可以做成浏览器插件??不错,有人表示:别看这几个案例相比还算简单,但凡微调一下,我都不敢想象其效果有多厉害了。所以,坏消息就是——验证码马上就要拦不住机器人了!(危险危险危险……)如何做到?Pix2St
 PHP开发指南:实现验证码登录Jul 01, 2023 am 09:27 AM
PHP开发指南:实现验证码登录Jul 01, 2023 am 09:27 AM随着互联网的发展和智能手机的普及,验证码登录功能被越来越多的网站和应用程序采用。验证码登录是一种通过输入正确的验证码来验证用户身份的登录方式,以提高安全性和防止恶意攻击。在PHP开发中,实现简单的验证码登录功能并不复杂,可以通过以下步骤来完成。创建数据库表首先,我们需要在数据库中创建一个用于存储验证码信息的表。表结构可以包含以下字段:id:自增主键phon
 用OCR技术,自动识别各种验证码,工具已开源May 25, 2023 am 10:07 AM
用OCR技术,自动识别各种验证码,工具已开源May 25, 2023 am 10:07 AM今天我在给大家分享一个OCR应用——ddddocr自动识别验证码。前面4个d是“带带弟弟”的首拼音。[/笑哭]。项目地址:https://github.com/sml2h3/ddddocr。使用的时候用pip命令直接安装即可pipinstallddddocr。OCR的核心技术包含两方面,一是目标检测模型检测图片中的文字,二是文字识别模型,将图片中的文字转成文本文字。第一类验证码最简单,它们没有复杂的背景图片,所以目标检测模型可以省略,直接将图片送入文字识别模型即可。识别代码如下:impor
 如何使用PHP创建验证码图片?Sep 13, 2023 am 11:40 AM
如何使用PHP创建验证码图片?Sep 13, 2023 am 11:40 AM如何使用PHP创建验证码图片?验证码(CAPTCHA)是一种常用的验证用户是否为人而不是机器的方法。在网站上,我们经常会看到验证码图片,要求用户输入图片上显示的随机字符或数字,以完成登录、注册、评论等操作。本文将介绍如何使用PHP创建验证码图片,并提供具体的代码示例。一、PHPGD库要创建验证码图片,我们需要使用PHP的GD库。GD库是一个用于处理图像的扩
 react怎么实现手机验证码Jan 04, 2023 am 10:17 AM
react怎么实现手机验证码Jan 04, 2023 am 10:17 AMreact实现手机验证码的方法:1、下载antd button和input组件;2、通过“<Input className={`apiMobileInput`} disabled value={this.props.phoneNumber} />”获取客户的手机号;3、通过“await this.props.sendCode({...})”实现获取验证码即可。
 如何使用 JavaScript 实现验证码功能?Oct 19, 2023 am 10:46 AM
如何使用 JavaScript 实现验证码功能?Oct 19, 2023 am 10:46 AM如何使用JavaScript实现验证码功能?随着网络的发展,验证码已经成为了网站和应用程序中不可或缺的安全机制之一。验证码(VerificationCode)是一种用于判断用户是否为人类而不是机器的技术。通过验证码,网站和应用程序可以防止垃圾信息提交、恶意攻击、机器人爬虫等问题。本文将介绍如何使用JavaScript实现验证码功能,并提供具体的代码


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

记事本++7.3.1
好用且免费的代码编辑器

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

