



作者 | Pengfei Zheng
单位 | USTC, HKBU TMLR Group
近年来,生成AI的迅猛发展为文本到图像生成、视频生成等令人瞩目的领域注入了强大的动力。这些技术的核心在于扩散模型的应用。扩散模型首先通过定义一个不断加噪声的前向过程来将图片逐步变为高斯噪声,再通过逆向过程将高斯噪声逐步去噪,变为清晰图片以得到真实样本。其中扩散常微分模型被用于生成的图片的插值数值,这在生成视频以及一些广告创意上有着极大的应用潜力。然而,我们注意到,当这种方法应用于自然图片时,插值出的图片效果往往很难如人意。
在一般情况下,扩散模型会对高斯噪声进行采样,然后逐步去噪以生成高质量的图片。插值图片的低质量意味着其潜在的变量不再遵循我们所期望的高斯分布。为了提高插值图片的质量,我们需要确保潜在的变量更接近于从高斯分布中采样。直接对潜在的变量进行缩放和偏移会严重破坏生成的图片,并且为了保留原始图片的信息,我们不能过多地修改潜在的变量。因此,在尽可能不破坏潜在的变量下提高插值图片的质量成为一个难题。
我们首先改变潜在变量的噪声水平来分析什么样的潜在变量能够被扩散模型还原成高质量的图片,并结合SDEdit方法引入高斯噪声来提高插值图片的质量,而高斯噪声的引入会带来额外的信息。此外我们还分析了高维空间中潜在的正交性,这为我们方法奠定了基础。我们结合球面线性插值法和直接引入噪声的方法,提出了一个全新的插值方法:对潜在的极值进行约束,并结合微小的高斯噪声使其更接近预期的分布,并引入了原始图片来缓解信息丢失的问题。利用这种插值方法,我们能够在保留原图信息的同时,显著提高自然图片的插值结果。
接下来,我将简要向大家分享我们的研究结果。

论文标题:NoiseDiffusion: Correcting Noise for Image Interpolation with Diffusion Models beyond Spherical Linear Interpolation
论文链接:https://www.php.cn/link/68310dc294a1c38c7ba636380151daca
代码链接:https://www.php.cn/link/fc9e5c39356354a60d33ca59499913ca
Introduction

图1:球面线性插值法在人脸图片上的运用
扩散模型最常用的图片插值方法是球面线性插值法[1,2]:
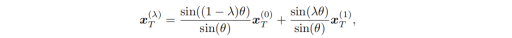

我们将这种方法运用在自然图片上。从图2可以观察到,当在自然图片上应用球面线性插值法时,插值效果显著下降。
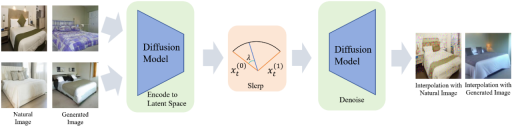
图2:自然图片和生成的图片插值效果比较
Analysis
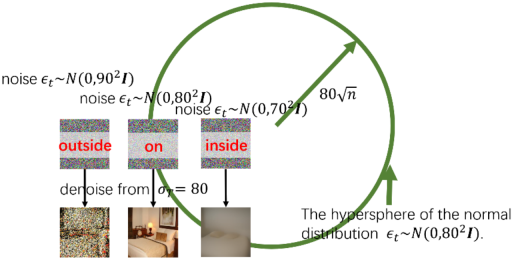
图3:不同噪声水平的高斯噪声去噪的效果
我们首先研究噪声水平对生成图片的影响。观察到只有当高斯噪声的水平与去噪的水平匹配时(中间的图片),才能得到质量较高的图片。如果噪声水平低于去噪水平(右图),或者高于去噪水平(左图),都会降低生成图片的质量。我们使用定理一来解释这种现象:
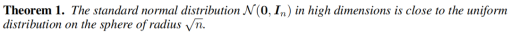
定理一阐述了在高维空间中,标准高斯噪声的分布特性:它们主要集中在一个超球面上。在这个超球面的内侧,尽管点的概率密度相对较高,但由于其占据的体积较小,其整体贡献并不显着;而在超球面的外侧,虽然点的体积较大,但由于概率密度随着距离的增大而迅速衰减,因此外侧点的贡献同样可以忽略不计。因此,在训练扩散模型时,我们主要观察到的潜在变量集中在超球面上,而超球面内侧和外侧的潜在变量由于这些原因难以有效进行去噪。
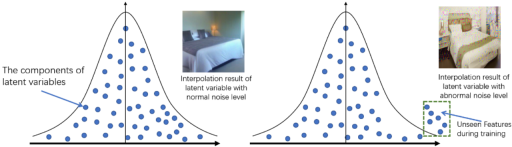
图4:自然图片插值失败的原因
自然图片通常具有扩散模型在训练过程中未曾见过的复杂特征,这使得扩散模型在尝试将自然图片转换为标准高斯噪声时遇到困难。具体而言,这些图片的潜在变量可能包含高于或低于模型去噪能力范围的高斯噪声。然而,扩散模型的能力主要局限于还原定理一中所描述的超球面上的高斯噪声。对于超出这一范围的噪声,模型往往无法有效处理。因此,在进行图片插值时,通常会产生质量较低的插值图片。
Introducing noise
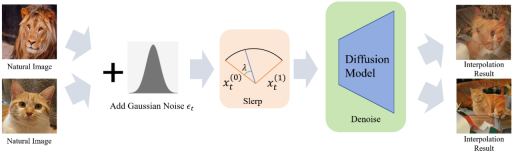
图5:直接引入噪声插值
为了改善图片的质量,使潜在变量更接近超球面,我们采用了结合SDEdit[3] 的方法。具体而言,我们直接向图片添加标准高斯噪声,然后进行插值,最后进行去噪处理。通过图5可以清晰地看出,这种方法显着提升了插值图片的质量。然而,需要注意的是,如图中所示,这种处理方法同时也会引入一些额外的信息。
Method

图6:NoiseDiffusion的整体设计
为了提高图片质量并尽可能减少信息丢失,我们创新地结合了球面线性插值法与直接引入噪声的插值方法,提出了全新的NoiseDiffusion方法。如图6所示,NoiseDiffusion的整体设计既考虑了插值过程中的信息保留,又通过引入噪声提升了图片质量,实现了两者之间的有效平衡。接下来,我们将详细阐述NoiseDiffusion的设计思路。
Design 1:
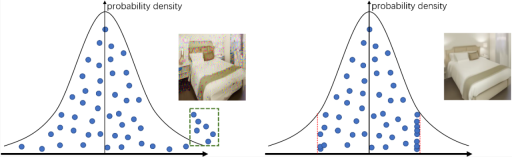
图7:对潜在变量的极值进行约束
根据统计学的,超出一定范围的噪声分量可以被视为异常值。且结合图3,我们发现高于去噪水平的高斯噪声会产生明显的噪点,而这与自然图片的插值结果上的异常色块非常相近,因此我们有理由认为是潜在变量的极值导致了这些异常色块的产生。基于这些分析,我们对潜在变量的极值施加了约束,以控制这些异常噪声的影响。从图7可以看出,通过对潜在变量极值的约束,我们大幅提升了图片的质量。
Design 2:

图8:引入原图信息
在对潜在变量施加约束时,我们可能会不小心影响到一些正常的分量,从而导致信息的损失。为了弥补这一潜在的信息损失,我们引入了原图信息作为补充。如图8所示,引入原图信息后,插值图片的质量得到了明显的提升。这表明原图信息在弥补信息损失方面发挥了重要作用。通过结合潜在变量的约束和原图信息的补充,我们能够在保证图片质量的同时,减少信息损失,实现更为准确和自然的插值效果。
Design 3:
球面线性插值法是一种依赖于计算两个潜在变量之间角度的插值方法。然而,在实际应用中,我们观察到这些潜在变量之间往往呈现出近乎正交的状态。为了解释这一现象,我们引入了定理二作为理论支撑。
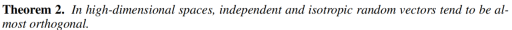

图9:引入不同大小的高斯噪声
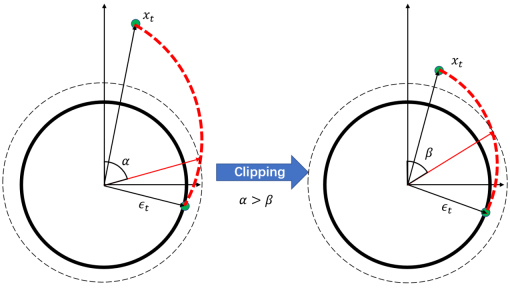
图10:结合Design 1减少引入的高斯噪声的量
从图9可以看出,随着我们逐步增加引入的高斯噪声量,插值图片的质量得到了显着提升。然而,这一改进并非没有代价,因为随着噪声量的增加,引入的额外信息也在逐渐增多。在实际插值过程中,为了在满足质量要求的同时尽量减少额外信息的引入,我们结合了前面提到的策略来有效地降低所需引入的高斯噪声的量(图10),从而更好地保留原始图像的信息。
Experiment

图11:和球面线性插值法的比较
我们将所提出的方法与球面线性插值法的结果进行了比较(如图11所示)。从插值结果来看,我们的方法在显着提高插值图片质量的同时,几乎不丢失信息。这充分展示了我们方法在保持信息完整性和提升图像质量方面的优越性能。
我们还在Stable Diffusion[4]上做了实验,由于Stable Diffusion的高度非结构化的潜在空间,在处插值很难得到平滑的插值(图12)。因此我们考虑在更小的时间步上进行插值(),这可以更多的保留原图的特征以让插值结果更加平滑,但是却导致了图片质量的降低(图13)。为了解决这个问题,我们运用了我们的方法NoiseDiffusion来修正潜在变量(图14)。从实验结果可以看出,我们的方法在较少改变信息的情况下,显着提高了图片的质量。

图12:在时使用球面线性插值法

图13:在时使用球面线性插值法

图14:在时使用NoiseDiffusion插值
Reference
[1] Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In ICLR,2021.
[2] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models . In ICLR,2021.
[3] Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon.
Sdedit: Guided image synthesis and editing with stochastic differential equations. In ICLR, 2022.
[4]Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. Highresolution image synthesis with latent diffusion models. In CVPR, 2022.
[5] Weihao Xia, Yulun Zhang, Yujiu Yang, Jing-Hao Xue, Bolei Zhou, and Ming-Hsuan Yang. Gan
inversion: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
课题组介绍
香港浸会大学可信机器学习和推理课题组(TMLR Group) 由多名青年教授、博士后研究员、博士生、访问博士生和研究助理共同组成,课题组隶属于理学院计算机系。课题组专攻可信表征学习、基于因果推理的可信学习、可信基础模型等相关的算法,理论和系统设计以及在自然科学上的应用,具体研究方向和相关成果详见本组Github (https ://github.com/tmlr-group)。课题组由政府科研基金以及工业界科研基金资助,如香港研究资助局杰出青年学者计划,国家自然科学基金面上项目和青年项目,以及微软、英伟达、百度、阿里、腾讯等企业的科研基金。青年教授和资深研究员手把手带,GPU计算资源充足,长期招收多名博士后研究员、博士生、研究助理和研究实习生。此外,本组也欢迎自费的访问博士后研究员、博士生和研究助理申请,访问至少3-6个月,支持远程访问。有兴趣的同学请发送个人简历和初步研究计划到邮箱 (bhanml@comp.hkbu.edu.hk)。
以上是ICLR 2024 Spotlight | NoiseDiffusion: 矫正扩散模型噪声,提高插值图片质量的详细内容。更多信息请关注PHP中文网其他相关文章!

 微软工作趋势指数2025显示工作场所容量应变Apr 24, 2025 am 11:19 AM
微软工作趋势指数2025显示工作场所容量应变Apr 24, 2025 am 11:19 AM由于AI的快速整合而加剧了工作场所的迅速危机危机,要求战略转变以外的增量调整。 WTI的调查结果强调了这一点:68%的员工在工作量上挣扎,导致BUR
 AI可以理解吗?中国房间的论点说不,但是对吗?Apr 24, 2025 am 11:18 AM
AI可以理解吗?中国房间的论点说不,但是对吗?Apr 24, 2025 am 11:18 AM约翰·塞尔(John Searle)的中国房间论点:对AI理解的挑战 Searle的思想实验直接质疑人工智能是否可以真正理解语言或具有真正意识。 想象一个人,对下巴一无所知
 中国的'智能” AI助手回应微软召回的隐私缺陷Apr 24, 2025 am 11:17 AM
中国的'智能” AI助手回应微软召回的隐私缺陷Apr 24, 2025 am 11:17 AM与西方同行相比,中国的科技巨头在AI开发方面的课程不同。 他们不专注于技术基准和API集成,而是优先考虑“屏幕感知” AI助手 - AI T
 Docker将熟悉的容器工作流程带到AI型号和MCP工具Apr 24, 2025 am 11:16 AM
Docker将熟悉的容器工作流程带到AI型号和MCP工具Apr 24, 2025 am 11:16 AMMCP:赋能AI系统访问外部工具 模型上下文协议(MCP)让AI应用能够通过标准化接口与外部工具和数据源交互。由Anthropic开发并得到主要AI提供商的支持,MCP允许语言模型和智能体发现可用工具并使用合适的参数调用它们。然而,实施MCP服务器存在一些挑战,包括环境冲突、安全漏洞以及跨平台行为不一致。 Forbes文章《Anthropic的模型上下文协议是AI智能体发展的一大步》作者:Janakiram MSVDocker通过容器化解决了这些问题。基于Docker Hub基础设施构建的Doc
 使用6种AI街头智能策略来建立一家十亿美元的创业Apr 24, 2025 am 11:15 AM
使用6种AI街头智能策略来建立一家十亿美元的创业Apr 24, 2025 am 11:15 AM有远见的企业家采用的六种策略,他们利用尖端技术和精明的商业敏锐度来创造高利润的可扩展公司,同时保持控制权。本指南是针对有抱负的企业家的,旨在建立一个
 Google照片更新解锁了您所有图片的惊人Ultra HDRApr 24, 2025 am 11:14 AM
Google照片更新解锁了您所有图片的惊人Ultra HDRApr 24, 2025 am 11:14 AMGoogle Photos的新型Ultra HDR工具:改变图像增强的游戏规则 Google Photos推出了一个功能强大的Ultra HDR转换工具,将标准照片转换为充满活力的高动态范围图像。这种增强功能受益于摄影师
 Descope建立AI代理集成的身份验证框架Apr 24, 2025 am 11:13 AM
Descope建立AI代理集成的身份验证框架Apr 24, 2025 am 11:13 AM技术架构解决了新兴的身份验证挑战 代理身份集线器解决了许多组织仅在开始AI代理实施后发现的问题,即传统身份验证方法不是为机器设计的
 Google Cloud Next 2025以及现代工作的未来Apr 24, 2025 am 11:12 AM
Google Cloud Next 2025以及现代工作的未来Apr 24, 2025 am 11:12 AM(注意:Google是我公司的咨询客户,Moor Insights&Strateging。) AI:从实验到企业基金会 Google Cloud Next 2025展示了AI从实验功能到企业技术的核心组成部分的演变,


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

记事本++7.3.1
好用且免费的代码编辑器

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

