



本次分享的主题为基于因果推断的推荐系统,回顾过去的相关工作,并提出本方向的未来展望。
为什么在推荐系统中需要使用因果推断技术?现有的研究工作用因果推断来解决三类问题(参见 Gao et al.的 TOIS 2023 论文 Causal Inference in Recommender Systems: A Survey and Future Directions):

首先,在推荐系统中存在各种各样的偏差(BIAS),因果推断是一种有效去除这些偏差的工具。
为了解决数据稀缺性和无法准确估计因果效应的问题,推荐系统可能面临挑战。为了解决这一问题,可利用基于因果推断的数据增强或因果效应估计的方法,来有效解决数据稀缺性、因果效应难估计的问题。
最后,通过利用因果知识或因果先验知识指导推荐系统的设计,可以更好地构建推荐模型。这种方法使得推荐模型超越传统的黑盒模型,不仅在准确性方面有所提升,在可解释性、公平性等方面更有显著改善。
从这三种思路出发,本次分享展开介绍下面三部分工作:
- 用户兴趣和从众性的解纠缠学习(Y. Zheng, Chen Gao, et al. Disentangling user interest and conformity for recommendation with causal embedding[C]//Proceedings of the Web Conference 2021. 2021: 2980-2991.)
- 长期兴趣和短期兴趣的解纠缠学习(Y. Zheng, Chen Gao*, et al. Disentangling long and short-term interests for recommendation[C]//Proceedings of the ACM Web Conference 2022. 2022: 2256-2267.)
- 短视频推荐的去偏(Y. Zheng, Chen Gao*, et al. DVR: micro-video recommendation optimizing watch-time-gain under duration bias[C]//Proceedings of the 30th ACM International Conference on Multimedia. 2022: 334-345.)
一、用户兴趣和从众性的解纠缠学习
首先,通过因果推断方法为用户的兴趣以及从众性分辨学习相应的表征。这属于前述分类框架中的第三部分,即在有因果先验知识的情况下,使模型更具解释性。
回到研究背景。可以观测到用户和商品的交互背后存储在深层次的、不同方面的原因。一方面是用户本身的兴趣,另一方面用户可能会倾向于追随其他用户的做法(从众性/Conformity)。在具体的系统中,这可能表现为销量或流行度。例如,现有推荐系统会将销量较高的商品展示在靠前的位置,这就导致了用户自身兴趣之外的流行度影响交互、带来偏差。所以,为了进行更精准的推荐,需要分辨学习和解决缠绕这两部分的表征。
为什么需要学习解纠缠表征呢?在这里,进一步做一个更深入的解读。解纠缠表征可以帮助克服离线训练数据和线上实验数据分布不一致(OOD)的问题。在真实的推荐系统中,如果在某一个数据分布下训练了一个离线推荐系统模型,需要考虑到部署到线上时数据分布可能发生变化。用户最终的行为是由从众性和兴趣共同作用产生的,这两部分的相对重要性在线上和线下环境存在区别,可能导致数据分布发生变化;而如果分布发生变化,无法保证学习的兴趣仍然有效。这是一个跨分布的问题。下图可以形象化地说明这个问题。在这个图中,训练数据集和测试数据集存在分布差异:同样的形状,其大小和颜色发生了变化。而对形状的预测,传统模型在训练数据集上可能会依据大小和颜色来推断形状,比如矩形都是蓝色的和最大的,但是对于测试数据集推断并不成立。

如果要更好地克服这个困难,就需要有效地确保每个部分的表征是由相应的因子决定的。这是学习解纠缠表征的一个动机。能够将潜在因子解纠缠出来的模型,在类似上图的跨分布情况下可以取得更好的效果:比如解纠缠学习到轮廓、颜色和大小等因子,并偏向使用轮廓预测形状。
传统做法是使用 IPS 方法来平衡商品的流行度。这种方法在推荐系统模型学习的过程中,惩罚过于流行的商品(这些商品在从众上具有更大的权重)。但这种做法将兴趣和从众性捆绑在一起,没有有效地将它们分开。

早期还有一些工作,通过因果推断的方法来学习因果表征(Causal embedding)。这类工作的缺点是必须依赖于一些无偏的数据集,通过无偏数据集来约束有偏数据集的学习过程。虽然不需要太多,但仍然需要一小部分无偏数据来学习解纠缠的表征。因此,在真实系统中,其适用性相对有限。

如果想对兴趣和从众性解纠缠,需要解决三个挑战:
- 多变的从众性:从众性实际上是一个更加泛化或者说更加普遍的概念,它涉及到流行度偏差。从众性是由用户和物品共同决定的,一个用户在不同物品上的从众性可能是不同的,反之亦然。
- 解纠缠的困难性:直接去学习一个解纠缠表征是颇具挑战性的。只能得到观测数据(一个受到兴趣和从众性两者影响之后的行为),而没有对用户兴趣的一个 ground truth,即对于兴趣和从众性两者本身各自没有显式的标签。
- 用户行为的多因性:用户的某次交互可能来自单个因子作用,也可能来自两个因子共同作用,推荐系统需要细致的设计来有效综合两个因子。
为了针对性解决上述挑战,我们提出了 DICE 方法(Disentangling Interest and Conformity with Causal Embedding (DICE))。
- 为了解决第一个挑战,为用户和商品在兴趣和从众性上各自设置了相应的表征。首先,高维空间上的用户和商品的 embedding 交互,能有效表达多样化的从众性。其次,这个方法能够有效地在高维空间上直接解开兴趣和从众性,而不再依赖于一个共同的表征,实现了这两者的独立性。

- 为了解决第二个挑战,利用了因果推断中的对撞关系。兴趣和从众共同导致行为,存在对撞关系,则利用这个关系获取特定因果的数据来为两部分分别学习相应的表征。

- 为了解决用户行为多因性挑战,使用一个多任务的渐进式学习(Curriculum learning, CL)方法来有效地结合这两个因子,实现最后的推荐。

接下来对这三部分设计(即因果 embedding、解纠缠表征学习、多任务课程学习)具体展开介绍。
1. 因果 embedding
首先,构建一个结构因果模型,包括兴趣和从众行为。

为这两个因素分别分配相应的独立表征,用户侧和物品侧每侧都有两部分表征。使用经典的点积来计算匹配分数。在最后的预测任务中,综合考虑两部分的内积分数。

2. 解纠缠表征学习

在给定上述这样一个对撞结构后,当固定条件 c 时,a 和 b 实际上是不独立的。举一个例子来解释这个效应:比如,a 代表一个学生的天赋,b 代表这个学生的勤奋程度,c 代表这个学生是否能够通过一个考试。如果这个学生通过考试,而且他没有特别强的天赋,那么他一定是很努力的。另外一个学生,他没有通过考试,但是他却非常有天赋,那么这个同学可能不太努力。
基于这样的思想,进行方法设计,分有兴趣的匹配和从众度的匹配,并使用商品流行程度作为从众性的代理。
第一个案例:如果一个用户点击了一个比较流行的项目 a,而没有点击另外一个不那么流行的项目 b,类似刚才的例子,会有下图这样的兴趣关系:a 对用户的从众性大于 b(因为 a 比 b 更流行),且 a 对用户的总体吸引力(兴趣 从众性)大于 b(因为用户点击了 a 而没有点击 b)。
第二个案例:一个用户点击了一个不流行的项目 c,但是没有点击一个流行的项目 d,产生如下的一个关系:c 对用户的从众性小于 d(因为 d 比 c 更流行),但 c 对用户的总体吸引力(兴趣 从众性)大于 d(因为用户点击了 c 而没有点击 d),从而用户对 c 的兴趣大于 d(因为对撞关系,如前述)。

总体而言,通过上述方法构造了两个集合:一是那些比正样本不流行的负样本(用户对正负样本的兴趣的对比关系未知),二是那些比正样本更流行的负样本(用户对正样本的兴趣大于负样本)。在这两个部分上,都可以构建对比学习的关系,从而有针对性地训练两个部分的表征向量。

当然,在实际训练过程中,最主要的目标仍然是拟合观测到的交互行为。和大多数推荐系统工作相同,使用 BPR loss预测点击行为。(u: 用户,i:正样本商品,j:负样本商品)。

另外基于上述思想,还分别设计了两个部分的对比学习方法,并引入对比学习的损失函数,额外引入两部分表征向量的约束,来优化这两部分的表征向量


此外,还要约束这两部分的表征向量尽可能地远离彼此。这是因为如果距离过近,它们可能会失去区分度。因此,额外引入了一个损失函数来约束两部分表征向量之间的距离。

3. 多任务课程学习
最终,多任务学习将把多个目标整合在一起。在这个过程中,设计了一种策略,确保能够从学习的难度上逐渐从简单过渡到困难。在训练的开始,使用区分度较小的样本,来引导模型参数在正确的大方向上进行优化,然后逐渐寻找困难样本进行学习,进一步精细调整模型参数。(将和正样本的流行度差异大的负样本视为简单样本,差异小的视为困难样本)。

4. 方法效果
在常见的数据集上,进行了测试,检验方法在主要排序指标上的性能。由于 DICE 是一个通用的框架,不依赖于具体的推荐模型,因此可以将不同模型视为一种 backbone,并将 DICE 作为一种即插即用的框架。

首先是主角 DICE。可以看到在不同的 backbone 上,DICE 的提升比较稳健,因此可以认为它是能带来性能提升的通用框架。

DICE 学习到的表征是可解释的,为兴趣和从众度分别学习表征之后,从众部分的向量蕴含了商品的流行度。通过进行可视化,发现它确实与流行度有关系(不同流行度的表征呈现明显的分层:绿橙黄色的点)。

并且,不同流行度的商品的兴趣向量表征均匀散布在空间中(青紫色叉)。从众性向量表征和兴趣向量表征也各自占有不同的空间,解纠缠区隔开来。这个可视化验证了 DICE 学习到的表征具有实际意义。

DICE 达到了设计的预期效果。进一步在不同干预强度的数据上进行了测试,结果显示 DICE 的性能在不同实验组上都要好于 IPS 方法。

总结一下,DICE 通过因果推断工具,为兴趣和从众性分别学习相应的表征向量,在非 IID 情形下提供了良好的鲁棒性和可解释性。

二、长期兴趣和短期兴趣的解纠缠学习
第二项工作主要解决序列推荐中长期兴趣和短期兴趣的解纠缠问题,具体而言,用户兴趣是复杂的,一部分兴趣可能相对稳定,被称为长期兴趣,而另一部分兴趣可能是突发的,被称为短期兴趣。在下图这个例子中,用户长期对电子产品感兴趣,但短期内想买一些衣服。如果能够很好地识别这些兴趣,就能更好地解释每次行为产生的原因,并提升整个推荐系统的性能。

这样的问题可以称为长短时兴趣的建模,即能够自适应地分别建模长时兴趣和短时兴趣,并且进一步推断用户当前的行为主要由哪一部分驱动。如果能够识别当前驱动行为的兴趣,就能更好地根据当前兴趣进行推荐。例如,如果用户在短时间内浏览相同的类别,那可能是一种短时兴趣;如果用户在短时间内广泛探索,那么可能需要更多地参考以前观测到的长期兴趣,而不局限于当前兴趣。总的来说,长期兴趣和短期兴趣性质相异,需要很好地解决长期需求和短期需求的解纠缠。

一般而言,可以认为协同过滤实际上是一种捕捉长期兴趣的方法,因为它忽略了兴趣的动态变化;而现有的序列推荐更多关注短期兴趣建模,这导致了长期兴趣的遗忘,即使考虑到了长期兴趣,它在建模时仍主要依赖于短期兴趣。因此,现有方法在结合这两种兴趣学习方面仍有所欠缺。

一些最近的工作开始考虑长期和短期兴趣的建模,分别设计短期模块和长期模块,然后将它们直接结合在一起。但这些方法中,最终学习的用户向量只有一个,同时包含短期信号和长期信号,两者依然纠缠在一起,需要进一步改进。

然而,解耦长短时兴趣依然是具有挑战性的:
- 首先,长期和短期兴趣实际上反映了用户可能相当不同的偏好差异,它们的特征也不同。长期兴趣是一种相对稳定的通用兴趣,而短期兴趣是动态的,并且会迅速演化。
- 其次,长短时兴趣没有显式的标签。最终收集的数据中大部分数据其实是最终行为,对于到底属于哪一种兴趣,并没有一个 ground truth。
- 最后,对于当前的行为到底由长短期兴趣的哪一部分驱动,哪一部分的重要性更高,同样是不确定的。
针对这个问题,提出了对比学习的方法,来同时建模长短期兴趣。(Contrastive learning framework of Long and Short-term interests for Recommendation (CLSR))
1. 长短期兴趣分离
对于第一个挑战——长期兴趣和短期兴趣分离,我们为长期和短期兴趣分别建立相应的演化机理。在结构因果模型中,设置和时间无关的长期兴趣,以及由上一个时刻的短期兴趣和通用的长期兴趣决定的短期兴趣。即在建模过程中长期兴趣是比较稳定的,而短期兴趣则是实时变化的。


2. 对比学习解决缺乏显式监督信号
第二个挑战是对于两部分兴趣缺乏显式的监督信号。为了解决这个问题,引入对比学习方法来进行监督,构建代理标签来替代显式标签。

代理标签分为两部分,一部分是对于长期兴趣的代理,另一部分是对于短期兴趣的代理。
使用整个历史的 pooling 作为长期兴趣的代理标签,在长期兴趣的学习中,使编码器学习的表征更多地朝向这个方向优化。
对于短期兴趣也是类似的,对用户最近若干次行为的平均 pooling,作为短期的代理;同样地,虽然它不直接代表用户兴趣,但是在用户短期兴趣的学习过程中,尽可能地朝这个方向进行优化。
这样的代理表征,虽然并不严格代表兴趣,但是它们代表了一个优化方向。对于长期兴趣表征和短期兴趣表征而言,它们会尽可能地接近相应的表征,而远离另外一个方向的表征,从而构建一个对比学习的约束函数。反过来同理,因为代理表征也要尽可能地接近实际的编码器输出,所以它是一个对称的两部分损失函数,这样的设计有效地弥补了刚刚提到的缺乏监督信号的问题。

3. 长短期兴趣权重判别
第三个挑战是对于给定的行为,判断两部分兴趣的重要性,解决方法是自适应地融合两块兴趣。这一部分的设计比较简单直接,因为前面已经有了两部分的表征向量,将它们混合在一起就并不困难了。具体而言,需要计算一个权重 α 来平衡两部分的兴趣,当 α 比较大时,当前的兴趣主要由长期兴趣主导;反之亦然。最后得到对交互行为的预估。

对于预测,一方面是前面提到的通用推荐系统的损失,另一方面以加权的形式将对比学习的损失函数加入其中。

以下是整体的框图:

这里有两个分离的编码器(BCD),相应的代理表征以及对比学习的目标(A),以及自适应地混合融合两部分的兴趣。
在这个工作中,使用了序列推荐的数据集,包括淘宝的电商数据集和快手的短视频数据集。将方法分为长期、短期和长短期结合三种。
4. 实验效果

观察整体实验结果可以看到,只考虑短期兴趣的模型比只考虑长期兴趣的模型表现更好,也就是说,序列推荐模型通常比纯静态的协同过滤模型更好。这是合理的,因为短期兴趣建模可以更好地识别当前最近的一些兴趣,而这些最近的行为对当前行为的影响最大。

第二个结论是同时建模长期和短期兴趣的 SLi-Rec 模型,并不一定比传统的序列推荐模型更好。这突出了现有工作的不足。原因是,如果只是简单地混合两种模型,可能会引入偏差或噪音;从这里可以看出,最好的 baseline 实际上是一种序列短期兴趣模型。
我们提出的长短期兴趣解耦方法解决了长期和短期兴趣之间的解纠缠建模问题,在两个数据集和四个指标上都能够取得稳定的最佳效果。
为了进一步研究这种解纠缠效果,为长短期兴趣相应的两部分表征进行实验。将 CLSR 学习的长期兴趣、短期兴趣和 Sli-Rec 学习的两种兴趣进行对比。实验结果表明,在每个部分上我们的工作(CLSR)都能够稳定地取得更好的效果,而且也证明了将长期兴趣建模和短期兴趣建模融合在一起的必要性,因为使用两种兴趣进行融合效果是最好的。

进一步,使用购买行为和点赞行为来对比研究,因为这些行为的成本比点击更高:购买需要花钱,点赞需要一定的操作成本,因此这些兴趣实际上反映了更强的偏好,更偏向于稳定的长期兴趣。首先,在性能对比方面,CLSR 取得了更好的效果。此外,建模的两个方面的权重更加合理。对于更偏向于长期兴趣的行为,CLSR 能够分配相比 SLi-Rec 模型更大的权重,这与之前的动机相吻合。

进一步进行了消融实验和超参数实验。首先,去掉了对比学习的损失函数,发现性能下降,说明对比学习对于解纠缠长期兴趣和短期兴趣是非常必要的。这个实验进一步证明了 CLSR 是一个更好的通用框架,因为它在现有方法的基础上也能发挥作用(自监督对比学习可以提升 DIEN 的性能),是一个即插即用的方法。对 β 的研究发现,一个比较合理的值是 0.1。

接下来进一步研究自适应融合和简单融合的关系。自适应权重融合相比固定权重融合在所有不同的 α 取值上都表现稳定更好,这验证了每次交互行为可能都由不同大小的权重决定,并且验证了通过自适应融合实现兴趣融合以及最后行为预测的必要性。

这项工作提出了一种对比学习方法来建模序列兴趣中的长期兴趣和短期兴趣,分别学习相应的表征向量,实现解纠缠。实验结果证明了该方法的有效性。

三、短视频推荐的去偏
前面介绍了两个工作,关注在兴趣的解纠缠。第三个工作则关注兴趣学习的行为纠偏。
短视频推荐成为了推荐系统中一个非常重要的组成部分。然而,现有的短视频推荐系统仍然遵循以前长视频推荐的范式,可能存在一些问题。

例如,如何评估在短视频推荐中用户的满意程度和活跃度?优化目标又是什么?常见的优化目标是观看时间或观看进度。那些被预估为可能具有更高完播率和观看时长的短视频,可能会被推荐系统排在更前的位置。在训练时可能基于观看时长进行优化,在服务时根据预估的观看时长进行排序,推荐那些观看时长更高的视频。
然而,在短视频推荐中存在一个问题是更长的观看时间并不一定代表用户对该短视频很感兴趣,即短视频的时长本身就是一个很重要的偏差。在使用上述优化目标(观看时间或观看进度)的推荐系统中,更长的视频天然具有优势。推荐过多这种长视频,很可能与用户的兴趣不匹配,但由于用户跳过视频的操作成本,实际的线上测试或离线训练得到的评估都会很高。因此,仅依靠观看时长是不够的。

可以看到,在短视频中存在两种形态。一种是比较长的视频,比如 vlog,而另一种是较短的娱乐视频。对真实的流量进行分析后发现,发布长视频的用户基本上能够获得更多的推荐流量,这个比例非常悬殊。仅仅使用观看时长来评估不仅不能满足用户的兴趣,也可能存在不公平的问题。

在本工作中,希望解决两个问题:
- 如何更好地无偏地评估用户的满意程度。
- 如何学习这种无偏的用户兴趣来提供良好的推荐。
实际上,核心挑战是不同时长的短视频无法直接进行比较。由于这个问题是天然且普遍存在于不同的推荐系统中的,而且不同推荐系统的结构差异很大,所以设计的方法需要与模型无关。
首先,选择了几个具有代表性的方法,并使用观看时长进行了模拟训练。

可以从曲线中看到时长偏差被增强了:对比 ground truth 的曲线,推荐模型在长视频的观看时间预测结果上明显偏高。在预测模型中,对于长视频的推荐过多是有问题的。

此外,还发现推荐结果中存在许多不准确的推荐(#BC)。

我们可以看到一些 bad case,即观看时间小于 2 秒且用户很不喜欢的视频。然而,由于偏差的影响,这些视频被错误地推荐。换而言之,模型只学习到了推荐视频的时长差异,基本上只能区分视频的长短。因为想要预测的结果是推荐更长的视频,以增加用户的观看时长。所以模型选择的是长视频,而不是用户喜欢的视频。可以看到,这些模型在 bad case 的数量上什至与随机推荐一样,因此这种偏差导致了非常不准确的推荐。
进一步说,这里存在不公平性问题。当控制 top k 值较小时,较短的视频发布者很难被推荐;即使 k 值足够大,这种推荐的比例也小于 20%。

1. WTG 指标
为了解决这个问题,我们首先提出了一个叫WTG( Watch Time Gain)的新指标,考虑了观看时长,以尝试实现无偏。例如,一个用户观看了一个 60 秒的视频达 50 秒;另一个视频也是 60 秒,但只看了 5 秒。显然,如果控制在 60 秒的视频上,这两个视频的兴趣差异就很明显。这是一个简单但有效的想法,只有当其他视频数据的时长相近时,观看时长才具有比较的意义。
首先将所有的视频等间距地划分到不同的时长组中,然后在每个时长组中比较用户的兴趣强度。在固定的时长组中,用户的兴趣可以由时长来代表。引入了 WTG 之后,实际上就是直接使用 WTG 来表示用户的兴趣强度,不再关注原始的时长。在 WTG 的评价下,分布就更加均匀了。


在 WTG 的基础上,进一步考虑了排序位置的重要性。因为 WTG 只考虑了一个指标(单一点),进一步地将这种累计效应考虑进来。即在计算排序列表中各个元素的指标时,还要考虑到每一个数据点的相对位置。这个思路与 NDCG 类似。因此,在此基础上,定义了 DCWTG。

2. 消除偏差的推荐方法
我们之前定义了能够反映时长无关的用户兴趣的指标,即 WTG 和 NDWTG。接下来,设计一个能够消除偏差的推荐方法,该方法与具体模型无关,并且适用于不同的 backbone。提出方法 DVR(Debiased Video Recommendation),核心思想是,在推荐模型中,如果能够去除与时长相关的特征,即使输入的特征很复杂,其中可能包含与时长有关的信息,只要在学习过程中能够使模型的输出忽略这些时长特征,那么可以认为它本身是无偏的,也就是让模型能够过滤掉时长相关的特征,从而实现无偏推荐。这里涉及一种对抗的思想,需要另一个模型,基于推荐模型的输出来预测时长,如果它无法精确预测时长,那么认为前一个模型的输出就不包含时长特征。因此,采用对抗学习方法,在推荐模型上加入一个回归层,该回归层基于预测出的 WTG 来预测原始的时长。如果 backbone 模型确实能够实现没有偏差的效果,那么回归层就无法重新预测还原出原始的时长。





以上是该方法的细节,用于实现对抗学习。
3. 实验效果

在微信和快手的两个数据集上进行了实验。首先是 WTG 和观看时长的对比。可以看到,分别使用了这两个优化目标,并与 ground truth 中的观看时长进行比较。使用 WTG 作为目标后,模型在短视频和长视频上的推荐效果都更好,WTG 曲线稳定地位于观看时长曲线上方。

此外,使用 WTG 作为目标后,带来了更平衡的长短视频推荐流量(传统模型中长视频的推荐份额显然更多)。

提出的 DVR 方法适用于不同的 backbone 模型:测试了 7 种常见的 backbone 模型,结果显示没有使用去偏方法的性能较差,而 DVR 在所有的 backbone 模型和所有指标上都有一定的提升。

进一步做了一些消融实验。前文中提到,这个方法有三部分设计,分别去掉了这三个部分。第一个是将时长作为输入特征去掉,第二个是将 WTG 作为预测目标去掉,第三个是去掉对抗学习的方法。可以看到每个部分的去掉都会导致性能下降。因此,这三个设计都至关重要。

总结我们的工作:从削减偏差的思路来研究短视频推荐,关注时长偏差。首先,提出了一种新的指标:WTG。它能够很好地消除实际行为中(用户兴趣和时长)时长的偏差。第二,提出了一种通用的方法,使模型不再受视频时长的影响,从而产生无偏的推荐。

最后对本次分享进行总结。首先,对用户兴趣和从众度进行了解纠缠学习。接下来,在序列行为建模方面,研究了长期兴趣和短期兴趣的解纠缠。最后,针对短视频推荐中观看时长优化的问题,提出了一种消偏的学习方法。
以上就是本次分享的内容,谢谢大家。
相关文献:
[1] Gao et al. Causal Inference in Recommender Systems: A Survey and Future Directions, TOIS 2024
[2] Zheng et al. Disentangling User Interest and Conformity for Recommendation with Causal Embedding, WWW 2021.
[3] Zheng et al. DVR:Micro-Video Recommendation Optimizing Watch-Time-Gain under Duration Bias, MM 2022
[4] Zheng et al. Disentangling Long and Short-Term Interests for Recommendation, WWW 2022.
以上是基于因果推断的推荐系统:回顾和前瞻的详细内容。更多信息请关注PHP中文网其他相关文章!

 AV字节:Openai' apple apple and visual ai等 - 分析vidhyaApr 12, 2025 am 09:38 AM
AV字节:Openai' apple apple and visual ai等 - 分析vidhyaApr 12, 2025 am 09:38 AM介绍 本周,人工智能(AI)世界上充满了重大更新。从OpenAI的O1模型展示高级推理到苹果的开创性视觉智能技术,Tech
 如何监视生产级代理抹布管道?Apr 12, 2025 am 09:34 AM
如何监视生产级代理抹布管道?Apr 12, 2025 am 09:34 AM介绍 2022年,Chatgpt的推出彻底改变了技术和非技术行业,从而使个人和组织具有生成性AI的能力。在2023年,努力集中在利用大语言模式
 如何使用Star模式优化数据仓库?Apr 12, 2025 am 09:33 AM
如何使用Star模式优化数据仓库?Apr 12, 2025 am 09:33 AMStar模式是用于数据仓库和商业智能的高效数据库设计。它将数据组织到链接到周围尺寸表的中心事实表中。这种类似恒星的结构简化了复杂Q
 代理抹布系统如何改变技术?Apr 12, 2025 am 09:21 AM
代理抹布系统如何改变技术?Apr 12, 2025 am 09:21 AM介绍 人工智能进入了一个新时代。模型将基于预定义的规则输出信息的日子已经一去不复返了。当今AI中的尖端方法围绕抹布(检索-Aigmente)
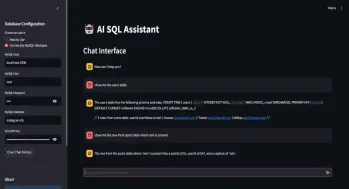 SQL自动生成查询助手Apr 12, 2025 am 09:13 AM
SQL自动生成查询助手Apr 12, 2025 am 09:13 AM您是否希望您可以简单地与数据库交谈,用简单的语言提出问题,并在不编写复杂的SQL查询或通过电子表格进行分类的情况下获得即时答案?使用Langchain的SQL工具包,Groq A
 阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM
阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM斯坦福大学以人为本人工智能研究所发布的《2025年人工智能指数报告》对正在进行的人工智能革命进行了很好的概述。让我们用四个简单的概念来解读它:认知(了解正在发生的事情)、欣赏(看到好处)、接纳(面对挑战)和责任(弄清我们的责任)。 认知:人工智能无处不在,并且发展迅速 我们需要敏锐地意识到人工智能发展和传播的速度有多快。人工智能系统正在不断改进,在数学和复杂思维测试中取得了优异的成绩,而就在一年前,它们还在这些测试中惨败。想象一下,人工智能解决复杂的编码问题或研究生水平的科学问题——自2023年
 开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PMMeta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

