
多个SOTA !OV-Uni3DETR:提高3D检测在类别、场景和模态之间的普遍性(清华&港大)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-04-11 19:46:18632浏览
这篇论文讨论了3D目标检测的领域,特别是针对Open-Vocabulary的3D目标检测。在传统的3D目标检测任务中,系统需要在预测真实场景中物体的定位3D边界框和语义类别标签,这通常依赖于点云或RGB图像。尽管2D目标检测技术因其普遍性和速度展现出色,但相关研究表明,3D通用检测的发展相比之下显得滞后。当前,大多数3D目标检测方法仍依赖于完全监督学习,并受到特定输入模式下完全标注数据的限制,只能识别经过训练过程中出现的类别,无论是在室内还是室外场景。
这篇论文指出,3D通用目标检测面临的挑战主要包括:现有的3D检测器只能在封闭词汇汇总的情况下工作,因此只能检测已经见过的类别。紧迫需要Open-Vocabulary的3D目标检测,以识别和定位训练过程中未获取的新类别目标实例。现有的3D检测数据集在大小和类别上与2D数据集相比都有限制,这限制了在定位新目标方面的泛化能力。此外,3D领域缺乏预训练的图像-文本模型,这进一步加剧了Open-Vocabulary 3D检测的挑战。同时,缺乏一种针对多模态3D检测的统一架构,现有的3D检测器大多设计用于特定的输入模态(点云、RGB图像或二者),这阻碍了有效利用来自不同模态和场景(室内或室外)的有效信息,从而限制了对新目标的泛化能力。
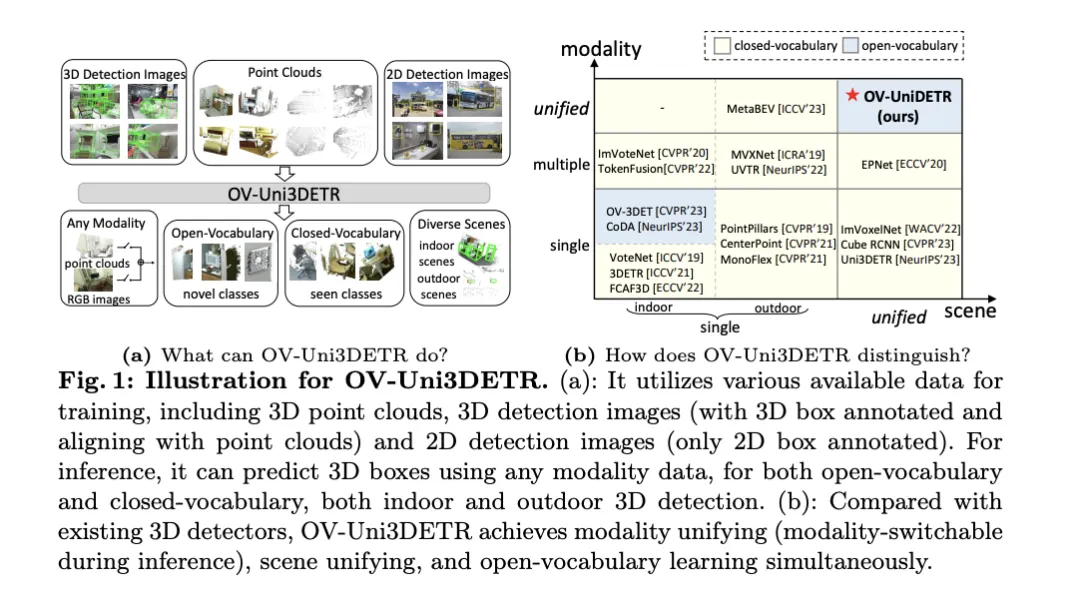
为了解决上述问题,论文提出了一种名为OV-Uni3DETR的统一多模态3D检测器。该检测器在训练期间能够利用多模态和多来源数据,包括点云、具有精确3D框标注的点云和点云对齐的3D检测图像,以及仅包含2D框标注的2D检测图像。通过这种多模态学习方式,OV-Uni3DETR能够在推理时处理任何模态的数据,实现测试时的模态切换,并在检测基础类别和新类别上表现出色。统一的结构进一步促使OV-Uni3DETR能够在室内和室外场景中进行检测,具备Open-Vocabulary能力,从而显著提高3D检测器在类别、场景和模态之间的普适性。
在此外,针对如何泛化检测器以识别新类别的问题,以及如何从没有3D框标注的大量2D检测图像中学习的问题,论文提出了一种称为周期模态传播的方法——通过这种方法,2D和3D模态之间传播知识以解决这两个挑战。通过这种方法,2D检测器的丰富语义知识可以传播到3D领域,以协助发现新的框,并3D检测器的几何知识则可用于在2D检测图像中定位目标,并通过匹配利匹配分类标签。
论文的主要贡献包括提出了一个能够在不同模态和多样化场景中检测任何类别目标的统一Open-Vocabulary 3D检测器OV-Uni3DETR;提出了一个针对室内和室外场景的统一多模态架构;以及提出了2D和3D模态之间知识传播循环的概念。通过这些创新,OV-Uni3DETR在多个3D检测任务上实现了最先进的性能,并在Open-Vocabulary设定下显著超过了之前的方法。这些成果表明,OV-Uni3DETR为3D基础模型的未来发展迈出了重要一步。
OV-Uni3DETR方法详解
Multi-Modal Learning
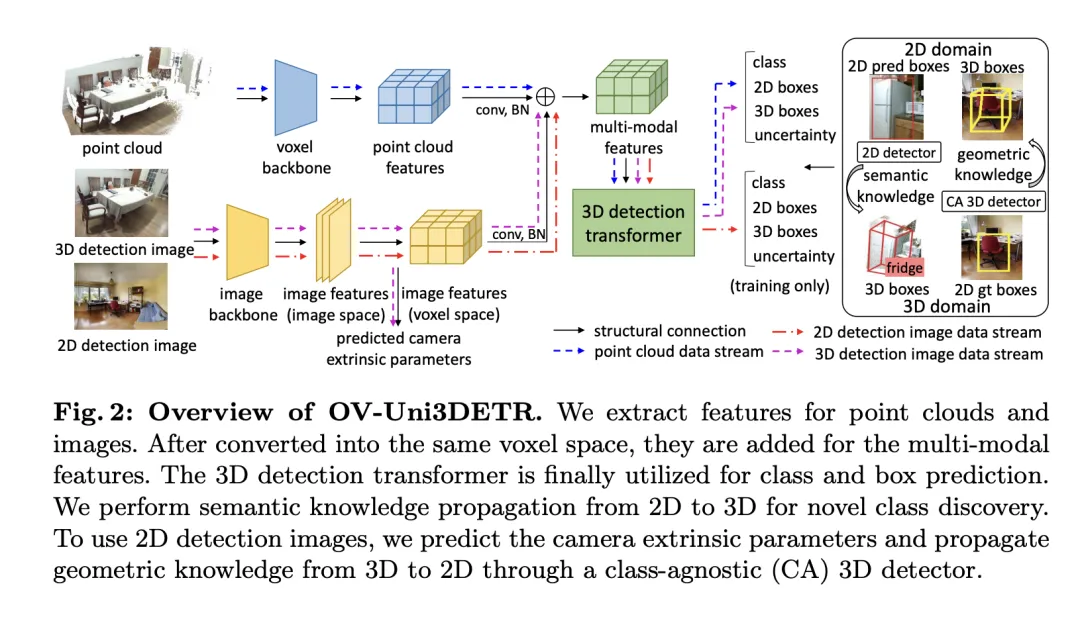
本文介绍了一种多模式学习框架,专门针对3D目标检测任务,通过整合云数据和图像数据来增强检测性能。这种框架能够处理在推理时可能缺失的某些传感器模态,即兼备测验时模态切换的能力。通过特定的网络结构提取并整合来自两种不同模态的特征,包括3D点云特征和2D图像特征,这些特征经过元素化处理和相机参数映射后,被融合用于后续的目标检测任务。
关键的技术点包括使用3D卷积和批量归一化来规范化和整合不同模式的特征,防止在特征级别上的不一致性导致某一模式被忽略。此外,采用随机切换模式的训练策略,确保模型能够灵活地处理只来自单一模式的数据,从而提高模型的鲁棒性和适应性。
最终,该架构利用复合损失函数,结合了类别预测、2D和3D边界框回归的损失,以及一个用于加权回归损失的不确定性预测,来优化整个检测流程。这种多模态学习方法不仅提高了对现有类别的检测性能,而且通过融合不同类型的数据,增强了对新类别的泛化能力。多模态架构最终预测类别标签、4维2D框和7维3D框,用于2D和3D目标检测。对于3D框回归,使用L1损失和解耦IoU损失;对于2D框回归,使用L1损失和GIoU损失。在Open-Vocabulary设置中,存在新类别样本,这增加了训练样本的难度。因此,引入了不确定性预测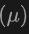 ,并用它来加权L1回归损失。目标检测学习的损失为:
,并用它来加权L1回归损失。目标检测学习的损失为:
对于某些3D场景,可能存在多视图图像,而不是单一的单眼图像。对于它们中的每一个,提取图像特征并使用各自的投影矩阵投影到体素空间。体素空间中的多个图像特征被求和以获取多模态特征。这种方法通过结合来自不同模态的信息,提高了模型对新类别的泛化能力,并增强了在多样化输入条件下的适应性。
Knowledge Propagation: 2D—3D
在介绍的多模态学习基础上,文中针对Open-Vocabulary的3D检测执行了一种称为“知识传播: ”的方法。Open-Vocabulary学习的核心问题是识别训练过程中未经人工标注的新类别。由于获取点云数据的难度,预训练的视觉-语言模型尚未在点云领域被开发。点云数据与RGB图像之间的模态差异限制了这些模型在3D检测中的性能。
”的方法。Open-Vocabulary学习的核心问题是识别训练过程中未经人工标注的新类别。由于获取点云数据的难度,预训练的视觉-语言模型尚未在点云领域被开发。点云数据与RGB图像之间的模态差异限制了这些模型在3D检测中的性能。

为了解决这个问题,提出利用预训练的2DOpen-Vocabulary检测器的语义知识,并为新类别生成相应的3D边界框。这些生成的3D框将补充训练时可用类别有限的3D真实标签。
具体来说,首先使用2DOpen-Vocabulary检测器生成2D边界框或实例遮罩。考虑到在2D领域可用的数据和标注更为丰富,这些生成的2D框能够实现更高的定位精度,并覆盖更广泛的类别范围。然后,通过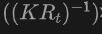 将这些2D框投影到3D空间,以获得相应的3D框。具体操作是使用
将这些2D框投影到3D空间,以获得相应的3D框。具体操作是使用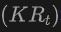
将3D点投影到2D空间,找到2D框内的点,然后对2D框内的这些点进行聚类以消除离群值,从而获得相应的3D框。由于预训练的2D检测器的存在,未标注的新目标可以在生成的3D框集中被发现。通过这种方式,从2D领域到生成的3D框传播的丰富语义知识,极大地促进了3DOpen-Vocabulary检测。对于多视图图像,分别生成3D框并将它们集成在一起以供最终使用。
在推理过程中,当点云和图像都可用时,可以以类似的方式提取3D框。这些生成的3D框也可以视为3DOpen-Vocabulary检测结果的一种形式。将这些3D框添加到多模态3D变换器的预测中,以补充可能缺失的目标,并通过3D非极大值抑制(NMS)过滤重叠的边界框。由预训练的2D检测器分配的置信度得分通过预定的常数系统地除以,然后重新解释为相应3D框的置信度得分。
实验
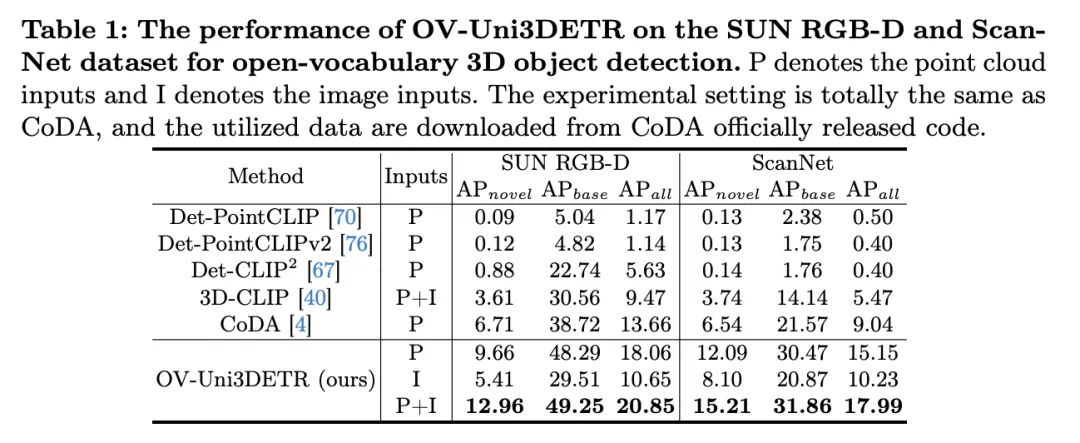
表格展示了OV-Uni3DETR在SUN RGB-D和ScanNet数据集上进行Open-Vocabulary3D目标检测的性能。实验设置与CoDA完全相同,使用的数据来自CoDA官方发布的代码。性能指标包括新类别平均精度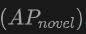 、基类平均精度
、基类平均精度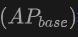 和所有类平均精度
和所有类平均精度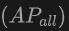 。输入类型包括点云(P)、图像(I)以及它们的组合(P I)。
。输入类型包括点云(P)、图像(I)以及它们的组合(P I)。
分析这些结果,我们可以观察到以下几点:
-
多模态输入的优势:当使用点云和图像的组合作为输入时,OV-Uni3DETR在两个数据集的所有评价指标上都取得了最高分,尤其是在新类别平均精度
 上的提升最为显着。这表明结合点云和图像可以显着提高模型对未见类别的检测能力,以及整体检测性能。
上的提升最为显着。这表明结合点云和图像可以显着提高模型对未见类别的检测能力,以及整体检测性能。 - 对比其他方法:与其他基于点云的方法相比(如Det-PointCLIP、Det-PointCLIPv2、Det-CLIP、3D-CLIP和CoDA ),OV-Uni3DETR在所有评价指标上都展现出优异的性能。这证明了OV-Uni3DETR在处理Open-Vocabulary3D目标检测任务上的有效性,尤其是在利用多模态学习和知识传播策略方面。
- 图像与点云输入的比较:仅使用图像(I)作为输入的OV-Uni3DETR虽然在性能上低于使用点云(P)作为输入的情况,但依然表现出不错的检测能力。这证明了OV-Uni3DETR架构的灵活性和对单一模态数据的适应能力,同时也强调了融合多种模态数据对提升检测性能的重要性。
-
在新类别上的表现:OV-Uni3DETR在新类别平均精度上的表现尤其值得关注,这对于Open-Vocabulary检测尤为关键。在SUN RGB-D数据集上,使用点云和图像输入时的达到了12.96%,在ScanNet数据集上达到了15.21%,这显着高于其他方法,显示了其在识别训练过程中未见过的类别上的强大能力。
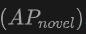 上的提升最为显着。这表明结合点云和图像可以显着提高模型对未见类别的检测能力,以及整体检测性能。
上的提升最为显着。这表明结合点云和图像可以显着提高模型对未见类别的检测能力,以及整体检测性能。 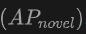 上的表现尤其值得关注,这对于Open-Vocabulary检测尤为关键。在SUN RGB-D数据集上,使用点云和图像输入时的
上的表现尤其值得关注,这对于Open-Vocabulary检测尤为关键。在SUN RGB-D数据集上,使用点云和图像输入时的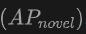 达到了12.96%,在ScanNet数据集上达到了15.21%,这显着高于其他方法,显示了其在识别训练过程中未见过的类别上的强大能力。
达到了12.96%,在ScanNet数据集上达到了15.21%,这显着高于其他方法,显示了其在识别训练过程中未见过的类别上的强大能力。 总的来说,OV-Uni3DETR通过其统一的多模态学习架构,在Open-Vocabulary3D目标检测任务上表现出卓越的性能,尤其是在结合点云和图像数据时,能够有效提升对新类别的检测能力,证明了多模态输入和知识传播策略的有效性和重要性。
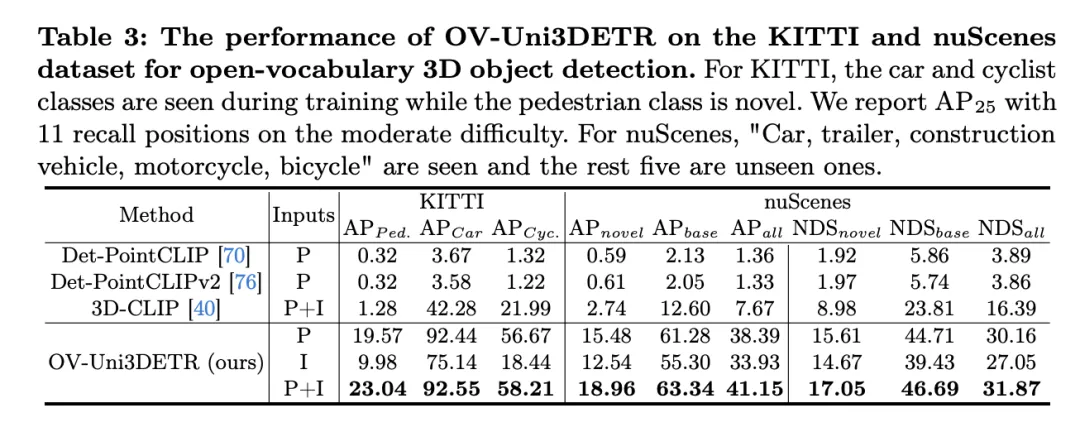
这个表格展示了OV-Uni3DETR在KITTI和nuScenes数据集上进行Open-Vocabulary3D目标检测的性能,涵盖了在训练过程中已见(base)和未见(novel)的类别。对于KITTI数据集,"car"和"cyclist"类别在训练过程中已见,而"pedestrian"类别是新颖的。性能使用在中等难度下的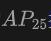
指标来衡量,且采用了11个召回位置。对于nuScenes数据集,"car, trailer, construction vehicle, motorcycle, bicycle"是已见类别,剩余五个为未见类别。除了AP指标外,还报告了NDS(NuScenes Detection Score)来综合评估检测性能。
分析这些结果可以得出以下结论:
- 多模态输入的显着优势:与仅使用点云(P)或图像(I)作为输入的情况相比,当同时使用点云和图像(P I)作为输入时,OV-Uni3DETR在所有评价指标上都获得了最高分。这一结果强调了多模态学习在提高对未见类别检测能力和整体检测性能方面的显着优势。
- Open-Vocabulary检测的有效性:OV-Uni3DETR在处理未见类别时展现出了出色的性能,尤其是在KITTI数据集的"pedestrian"类别和nuScenes数据集的"novel"类别上。这表明了模型对新颖类别具有很强的泛化能力,是一个有效的Open-Vocabulary检测解决方案。
- 与其他方法的对比:与其他基于点云的方法相比(如Det-PointCLIP、Det-PointCLIPv2和3D-CLIP),OV-Uni3DETR展现出了显着的性能提升,无论是在已见还是未见类别的检测上。这证明了其在处理Open-Vocabulary3D目标检测任务上的先进性。
- 图像输入与点云输入的对比:尽管使用图像输入的性能略低于使用点云输入,但图像输入仍然能够提供相对较高的检测精度,这表明了OV-Uni3DETR架构的适应性和灵活性。
- 综合评价指标:通过NDS评价指标的结果可以看出,OV-Uni3DETR不仅在识别准确性上表现出色,而且在整体检测质量上也取得了很高的分数,尤其是在结合点云和图像数据时。
OV-Uni3DETR在Open-Vocabulary3D目标检测上展示了卓越的性能,特别是在处理未见类别和多模态数据方面。这些结果验证了多模态输入和知识传播策略的有效性,以及OV-Uni3DETR在提升3D目标检测任务泛化能力方面的潜力。
讨论

这篇论文通过提出OV-Uni3DETR,一个统一的多模态3D检测器,为Open- Vocabulary的3D目标检测领域带来了显着的进步。该方法利用了多模态数据(点云和图像)来提升检测性能,并通过2D到3D的知识传播策略,有效地扩展了模型对未见类别的识别能力。在多个公开数据集上的实验结果证明了OV-Uni3DETR在新类别和基类上的出色性能,尤其是在结合点云和图像输入时,能够显着提高对新类别的检测能力,同时在整体检测性能上也达到了新的高度。
优点方面,OV-Uni3DETR首先展示了多模态学习在提升3D目标检测性能中的潜力。通过整合点云和图像数据,模型能够从每种模态中学习到互补的特征,从而在丰富的场景和多样的目标类别上实现更精确的检测。其次,通过引入2D到3D的知识传播机制,OV-Uni3DETR能够利用丰富的2D图像数据和预训练的2D检测模型来识别和定位训练过程中未见过的新类别,这大大提高了模型的泛化能力。此外,该方法在处理Open-Vocabulary检测时显示出的强大能力,为3D检测领域带来了新的研究方向和潜在应用。
缺点方面,虽然OV-Uni3DETR在多个方面展现了其优势,但也存在一些潜在的局限性。首先,多模态学习虽然能提高性能,但也增加了数据采集和处理的复杂性,尤其是在实际应用中,不同模态数据的同步和配准可能会带来挑战。其次,尽管知识传播策略能有效利用2D数据来辅助3D检测,但这种方法可能依赖于高质量的2D检测模型和准确的3D-2D对齐技术,这在一些复杂环境中可能难以保证。此外,对于一些极其罕见的类别,即使是Open-Vocabulary检测也可能面临识别准确性的挑战,这需要进一步的研究来解决。
OV-Uni3DETR通过其创新的多模态学习和知识传播策略,在Open-Vocabulary3D目标检测上取得了显着的进展。虽然存在一些潜在的局限性,但其优点表明了这一方法在推动3D检测技术发展和应用拓展方面的巨大潜力。未来的研究可以进一步探索如何克服这些局限性,以及如何将这些策略应用于更广泛的3D感知任务中。
结论
在本文中,我们主要提出了OV-Uni3DETR,一种统一的多模态开放词汇三维检测器。借助于多模态学习和循环模态知识传播,我们的OV-Uni3DETR很好地识别和定位了新类,实现了模态统一和场景统一。实验证明,它在开放词汇和封闭词汇环境中,无论是室内还是室外场景,以及任何模态数据输入中都有很强的能力。针对多模态环境下统一的开放词汇三维检测,我们相信我们的研究将推动后续研究沿着有希望但具有挑战性的通用三维计算机视觉方向发展。
以上是多个SOTA !OV-Uni3DETR:提高3D检测在类别、场景和模态之间的普遍性(清华&港大)的详细内容。更多信息请关注PHP中文网其他相关文章!