在社交活动中,大语言模型既可以是你的合作伙伴(partner),也可以成为你的导师(mentor)。
在人类的社交活动中,为了更有效地在工作和生活中与他人沟通,需要一定的社交技能,比如解决冲突。然而,社交技能的练习环境对于大多数人来说通常是遥不可及的。特别是由专家训练这些技能时,往往耗时、投入高且可用性有限。现有的练习和反馈机制很大程度上依赖专家监督,使训练难以扩展。此外,经过专业培训的教练也缺乏,而大多数可以提供定制化反馈的教练无法帮助大量有需要的人。近日,在由斯坦福助理教授杨笛一为共同一作的论文《Social Skill Training with Large Language Models》中,研究者认为,借助大语言模型可以使得社交技能训练变得更容易、更安全、更有吸引力,并在现实、虚拟练习空间中提供量身定制的反馈。
论文地址:https://arxiv.org/pdf/2404.04204.pdf第一个训练框架是 AI Partner,它可以通过模拟练习为体验式训练提供可扩展的解决方案。此前已经有研究表明,人类角色扮演可以有效地教授沟通、合作和领导技能。与 on-the-job 训练相比,模拟可以让学习者承担更少的风险和机会成本。而通过模拟,AI Partner 将减少进入专业领域的社会经济障碍。第二个补充训练框架是 AI Mentor, 它将根据领域专业知识和事实知识提供个性化反馈。这两个训练框架(合称为 APAM)都可以将体验式学习与现实练习、定制反馈相结合。研究者呼吁通过跨学科创新来解决 APAM 的广泛影响。论文作者杨笛一表示:「学习社交技能对大多数人来说是遥不可及的,我们如何才能使社交技能训练变得更容易实现?基于此,我们推出 APAM,其利用 LLM 通过现实实践和量身定制的反馈进行社交技能训练!」
她接着表示:「在 APAM 中,当用户想要学习一项新的社交技能时,AI Partner 可以帮助他们通过模拟对话来练习相关场景。AI Mentor 可以在模拟的关键时刻提供基于知识的反馈。」
该研究提出了一个通用框架专门用于社交技能训练,该框架包括 AI Partner 和 AI Mentor(两者简称 APAM),并且这两者至关重要。当用户想要学习一项新的社交技能时,AI Partner 可以通过模拟对话帮助他们练习相关场景。AI Mentor 可以在模拟的关键时刻提供基于知识的反馈。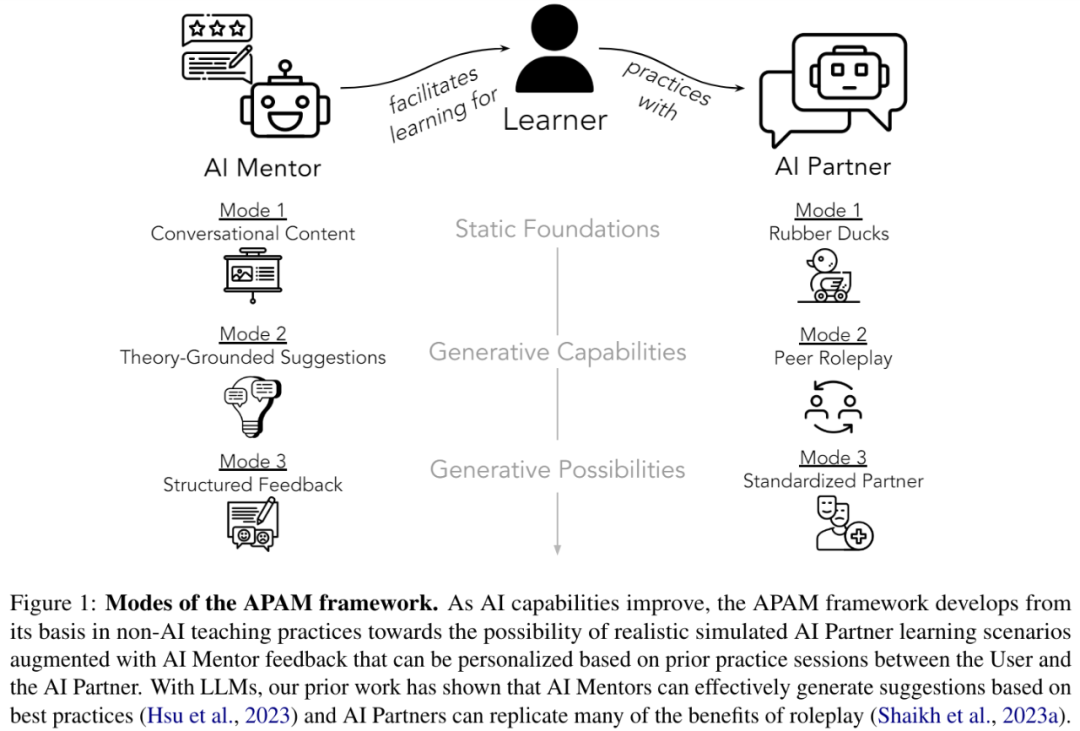
然而,构建和部署 AI Partner 并非易事,比如很难保持模拟人物的风格、行为和情感特征的一致性。而开发 AI Mentor 在很大程度上依赖于领域专业知识、情境感知和反馈效率等因素。为了解决上述问题,研究者提出通过 LLM 进行社交技能训练的通用方法,分四个步骤完成:
- 设计一个 AI partner 来模拟对话,让学习者(即用户)接触目标过程,进行练习;
研究者表示,APAM 框架的理想受众是初学者,但是有经验的人也可以使用 APAM 系统来刷新他们的知识。APAM 可以在许多领域提高学习者的技能,表 1 列举了一些应用场景,例如如何倾听、心理健康咨询等。不过 APAM 框架不仅限于这些典型的例子,论文第 6 节有更多的介绍。
虽然 LLM 作为社交技能训练工具潜力巨大,因为它们可以生成连贯且自然的文本。然而,这种灵活性往往伴随着有限的可控性。出于安全考虑, APAM 框架为如何应用 AI 提供了一系列措施,他们将使用过程分解为一个连续体:AI Partner 连续体以及 AI Mentor 连续体,每个连续体都由三个模型完成(如图 1 所示)。AI partner 和 AI mentor 的评估是一个重大挑战,基于 APAM 的工具涉及复杂的计算系统以及与不同需求和背景的用户的交互。为了将这些训练工具开发为一个领域,评估措施需要超越自然语言处理中传统的指标,转而采用来自多个相关领域和利益相关者的方案。纳入多学科视角将有助于评估此类系统的实证性能、基于用户角度的可用性以及对用户和社区的长期影响。目前,文本生成的研究主要集中在内在评估上,即通过预定义的规则或交互来评估输出的质量。在下表 2 中,研究者主要划分为全自动评估和用户驱动评估。基于参考的指标(如困惑度或 Kullback-Leibler 散度)通常用于系统质量自动评估,它们既简单又允许通过演示对所需行为进行丰富的定义。表 2 详细列出了以往工作中适用于 APAM 系统的内在和外在评估程序。目前,自然语言处理从业者主要关注对系统的内在评估。本文中,研究者强调使用既定的教育成果衡量标准来评估 APAM 系统的重要性。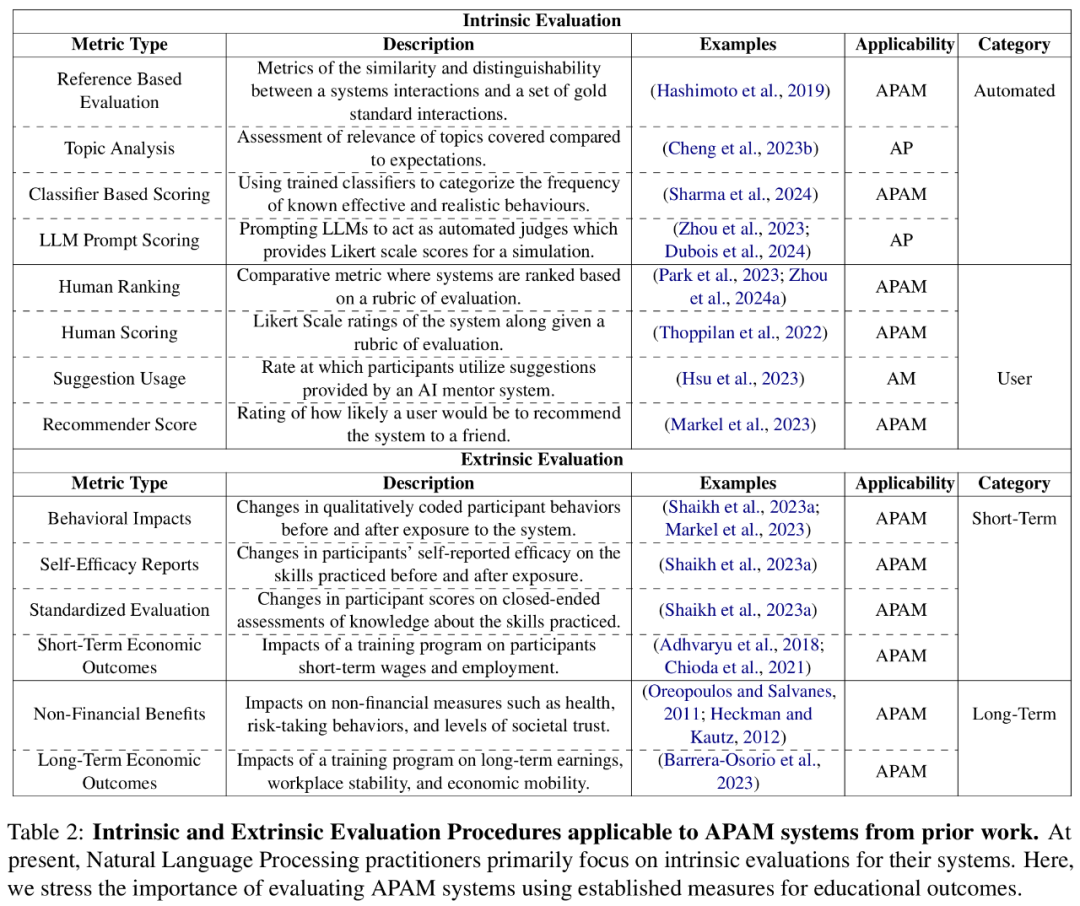
以上是杨笛一新作:社恐有救了,AI大模型一对一陪聊,帮i人变成e人的详细内容。更多信息请关注PHP中文网其他相关文章!

