
Attention isn't all you need!Mamba混合大模型开源:三倍Transformer吞吐量

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-03-30 09:41:16961浏览
Mamba 时代来了?
自 2017 年开创性研究论文《Attention is All You Need》问世以来,transformer 架构就一直主导着生成式人工智能领域。
然而,transformer 架构实际上有两个显着缺点:
Transformer 的内存占用量随上下文长短而变化。这使得在没有大量硬件资源的情况下运行长上下文窗口或大量并行处理变得具有挑战性,从而限制了广泛的实验和部署。 Transformer 模型的内存占用量随上下文长度的变化而变化,这使得在没有大量硬件资源的情况下运行长上下文窗口或大量并行处理变得困难,从而限制了广泛的实验和部署。
Transformer 模型中的注意力机制会根据上下文长度的增加来调整速度,这种机制会随机扩展序列长度并降低计算量,因为每个token 都依赖于它之前的整个序列,从而将上下文应用于高效生产产生的范围之外。
transformer并非生产式人工智能唯一的前进方向。最近,AI21 Labs推出并开源了一种名为“Jamba”的新方法,在多个基准上超越了transformer。

Hugging Face 地址:https://huggingface.co/ai21labs/Jamba-v0.1
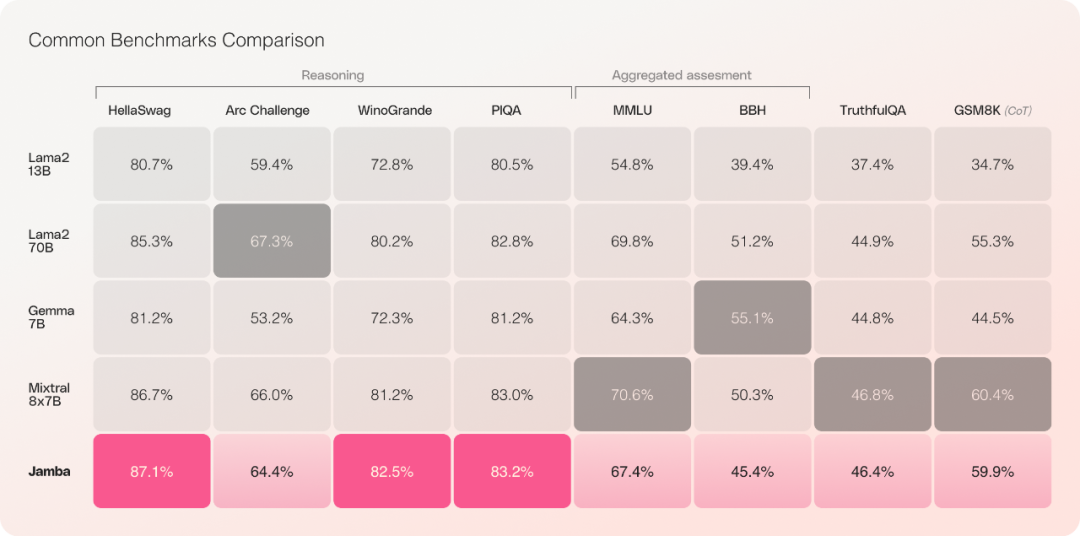
Mamba的SSM 架构可以很好地解决transformer 的内存资源和上下文问题。然而,Mamba 方法很难提供与 transformer 模型相同的输出水平。
Jamba 将基于结构化状态空间模型 (SSM) 的 Mamba 模型与 transformer 架构相结合,旨在将 SSM 和 transformer 的最佳属性结合在一起。

Jamba 还可以作为 NVIDIA NIM 推理微服务从 NVIDIA API 目录进行访问,企业应用程序开发人员可以使用 NVIDIA AI Enterprise 软件平台进行部署。
总的来说,Jamba 模型具有以下特点:
第一个基于Mamba 的生产级模型,采用新颖的SSM-Transformer 混合架构;
与Mixtral 8x7B 相比,长上下文上的吞吐量提高了3 倍;
提供对256K 上下文窗口的访问;
公开了模型权重;
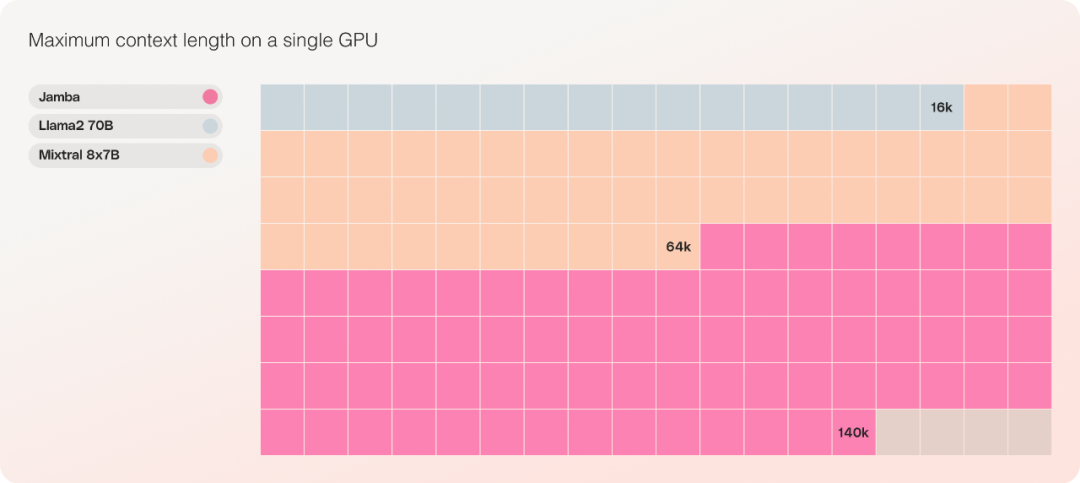
同等参数规模中唯一能够在单个GPU 上容纳高达140K 上下文的模型。
模型架构
如下图所示,Jamba 的架构采用块层(blocks-and-layers)方法,使Jamba 能够集成两种架构。每个 Jamba 块包含一个注意力层或一个 Mamba 层,后跟一个多层感知器(MLP),从而形成 transformer 层。
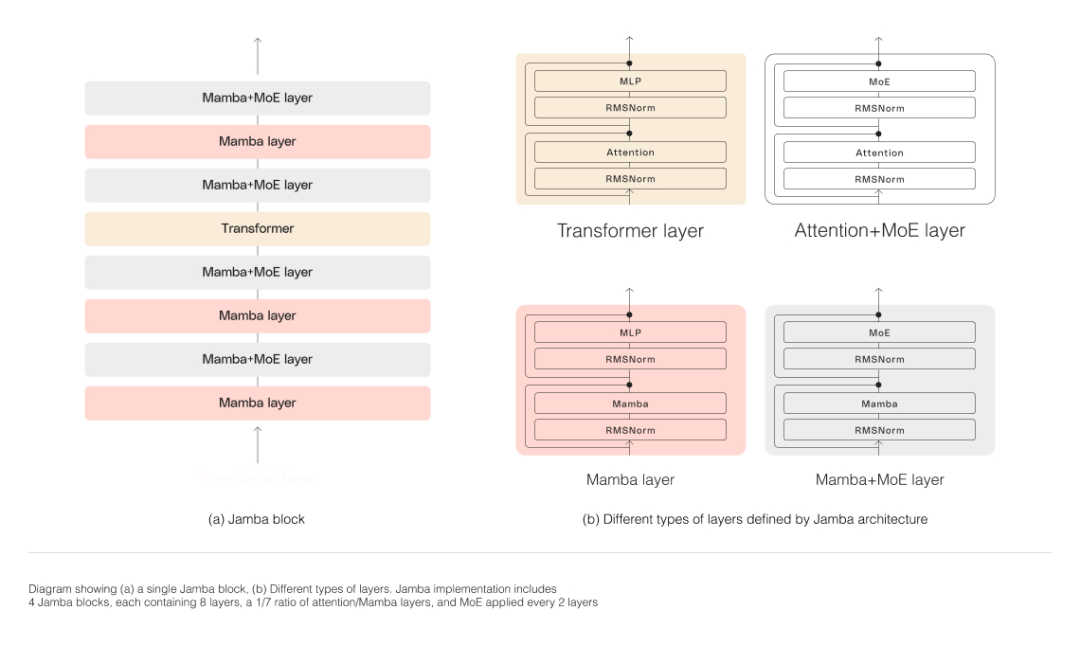
Jamba 利用MoE 来增加模型参数的总数,同时简化推理中使用的活跃参数的数量,从而在计算需求没有相应增加的情况下获得更高的模型容量。为了在单个 80GB GPU 上最大限度地提高模型的质量和吞吐量,研究团队优化了所使用的 MoE 层和专家的数量,为常见推理工作负载留出了足够的内存。
Jamba 的 MoE 层允许它在推理时仅利用可用的 52B 参数中的 12B,并且其混合架构使这些 12B 活跃参数比同等大小的纯 transformer 模型更有效。
此前,没有人将 Mamba 扩展到 3B 参数之外。 Jamba 是同类模型中第一个达到生产级规模的混合架构。
吞吐量和效率
初步评估实验表明,Jamba 在吞吐量和效率等关键衡量指标上表现出色。
在效率方面,Jamba 在长上下文上的吞吐量达到了 Mixtral 8x7B 的 3 倍。 Jamba 比 Mixtral 8x7B 等大小相当的基于 Transformer 的模型更高效。
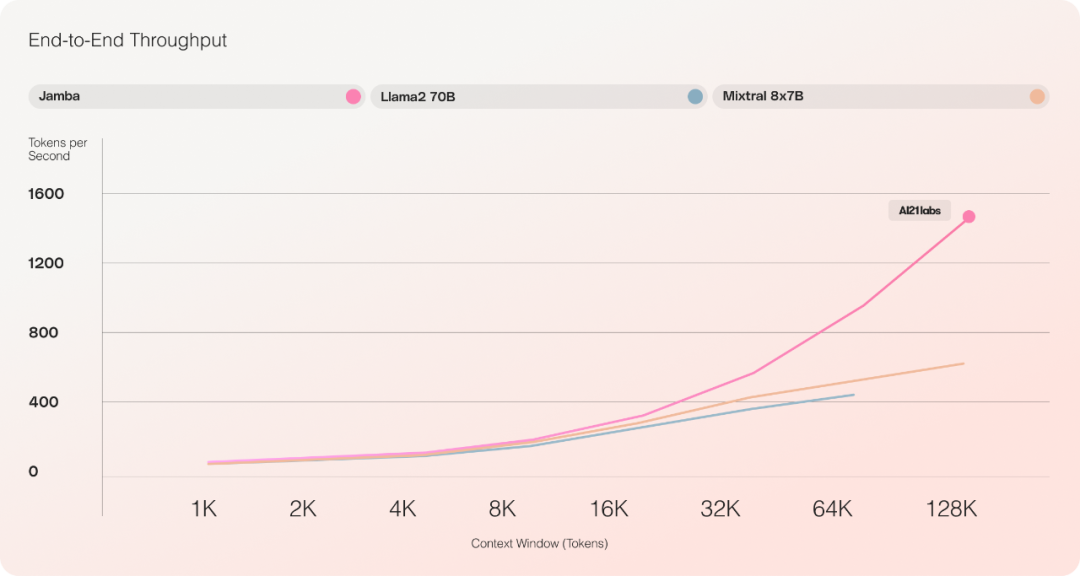
在成本方面,Jamba 可以在单个 GPU 上容纳 140K 上下文。与当前类似大小的其他开源模型相比,Jamba 能提供更多的部署和实验机会。
需要注意的是,Jamba 目前不太可能取代当前基于 Transformer 的大型语言模型 (LLM),但它可能会成为某些领域的补充。
参考链接:
https://www.ai21.com/blog/announcing-jamba
https://venturebeat.com/ai/ai21-labs-juices-up-gen-ai-transformers-with-jamba/
以上是Attention isn't all you need!Mamba混合大模型开源:三倍Transformer吞吐量的详细内容。更多信息请关注PHP中文网其他相关文章!