
文生图的基石CLIP模型的发展综述

- 王林转载
- 2024-03-22 20:50:221350浏览
CLIP stands for Contrastive Language-Image Pre-training, which is a pre-training method or model based on contrastive text-image pairs. It is a multimodal model that relies on contrastive learning. The training data for CLIP consists of text-image pairs, where an image is paired with its corresponding text description. Through contrastive learning, the model aims to understand the relationship between text and image pairs.

Open AI在2021年1月份发布了DALL-E和CLIP,这两个模型都是多模态模型,能够结合图像和文本。DALL-E是一种基于文本生成图像的模型,而CLIP则是利用文本作为监督信号来训练可迁移的视觉模型。
在Stable Diffusion模型中,通过cross attention将CLIP文本编码器提取的文本特征嵌入到扩散模型的UNet中。具体来说,文本特征被用作attention的key和value,而UNet的特征则被用作query。换句话说,CLIP实际上是将文字和图片之间建立连接的关键桥梁,将文本信息与图像信息有机地结合起来。这种结合方式使得模型能够更好地理解和处理不同模态之间的信息,从而在处理复杂任务时取得更好的效果。通过这种方式,Stable Diffusion模型能够更加有效地利用CLIP的文本编码能力,从而提升整体性能并拓展应用领域。
CLIP
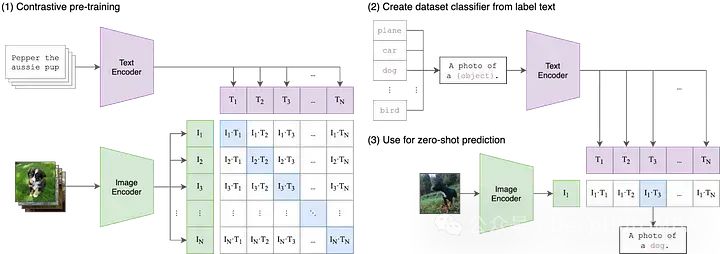
这是OpenAI在21年最早发布的论文,要想理解CLIP,我们需要将缩略词解构为三个组成部分:(1)Contrastive ,(2)Language-Image,(3)Pre-training。
我们先从Language-Image开始。
在传统机器学习模型中,通常只能接受单一模态的输入数据,比如文本、图像、表格数据或音频。如果需要使用不同模态的数据来进行预测,就必须训练多个不同的模型。而在CLIP中,“Language-Image”表示该模型可以同时接受文本(语言)和图像两种类型的输入数据。这种设计使得CLIP能够更灵活地处理不同模态的信息,从而提高了其预测能力和应用范围。
CLIP通过使用两个不同的编码器处理文本和图像输入,分别是文本编码器和图像编码器。这两个编码器将输入数据映射到较低维度的潜在空间中,为每个输入生成相应的嵌入向量。一个重要的细节是,文本和图像编码器将数据嵌入到相同的空间中,即原始的CLIP空间是一个512维向量空间。这种设计使得文本和图像之间可以进行直接的比较和匹配,无需额外的转换或处理。这样一来,CLIP可以在同一个向量空间中表示文本描述和图像内容,从而实现了跨模态的语义对齐和检索功能。这种共享的嵌入空间的设计使得CLIP具有更好的泛化能力和适应性,使其能够在各种任务和数据集上表现出色。
Contrastive
虽然将文本和图像数据嵌入到同一向量空间可能是一个有用的起点,但仅仅做到这一点并不能确保模型能够有效地比较文本和图像的表示。举例来说,建立文本中“狗”或“一张狗的照片”的嵌入与狗图像的嵌入之间的合理且可解释的关系是很重要的。然而,我们需要一种方法来弥合这两种模式之间的差距。
在多模态机器学习中,有各种各样的技术来对齐两个模态,但目前最流行的方法是对比。对比技术从两种模式中获取成对的输入:比如一张图像和它的标题并训练模型的两个编码器尽可能接近地表示这些输入的数据对。与此同时,该模型被激励去接受不配对的输入(如狗的图像和“汽车的照片”的文本),并尽可能远地表示它们。CLIP并不是第一个图像和文本的对比学习技术,但它的简单性和有效性使其成为多模式应用的支柱。
Pre-training
虽然CLIP本身对于诸如零样本分类、语义搜索和无监督数据探索等应用程序很有用,但CLIP也被用作大量多模式应用程序的构建块,从Stable Diffusion和DALL-E到StyleCLIP和OWL-ViT。对于大多数这些下游应用程序,初始CLIP模型被视为“预训练”的起点,并且整个模型针对其新用例进行微调。
虽然OpenAI从未明确指定或共享用于训练原始CLIP模型的数据,但CLIP论文提到该模型是在从互联网收集的4亿对图像-文本上进行训练的。
https://www.php.cn/link/7c1bbdaebec5e20e91db1fe61221228f
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision

使用CLIP, OpenAI使用了4亿对图像-文本,因为没有提供细节,所以我们不可能确切地知道如何构建数据集。但是在描述新的数据集时,他们参考了谷歌的Google’s Conceptual Captions 作为灵感——一个相对较小的数据集(330万图像描述对,这个数据集使用了昂贵的过滤和后处理技术,虽然这些技术很强大,但不是特别可扩展)。
所以高质量的数据集就成为了研究的方向,在CLIP之后不久,ALIGN通过规模过滤来解决这个问题。ALIGN不依赖于小的、精心标注的、精心策划的图像字幕数据集,而是利用了18亿对图像和替代文本。
虽然这些替代文本描述平均而言比标题噪音大得多,但数据集的绝对规模足以弥补这一点。作者使用基本的过滤来去除重复的,有1000多个相关的替代文本的图像,以及没有信息的替代文本(要么太常见,要么包含罕见的标记)。通过这些简单的步骤,ALIGN在各种零样本和微调任务上达到或超过了当时最先进的水平。
https://arxiv.org/abs/2102.05918
K-LITE: Learning Transferable Visual Models with External Knowledge

与ALIGN一样,K-LITE也在解决用于对比预训练的高质量图像-文本对数量有限的问题。
K-LITE专注于解释概念,即将定义或描述作为上下文以及未知概念可以帮助发展广义理解。一个通俗的解释就是人们第一次介绍专业术语和不常用词汇时,他们通常会简单地定义它们!或者使用一个大家都知道的事物作为类比。
为了实现这种方法,微软和加州大学伯克利分校的研究人员使用WordNet和维基词典来增强图像-文本对中的文本。对于一些孤立的概念,例如ImageNet中的类标签,概念本身被增强,而对于标题(例如来自GCC),最不常见的名词短语被增强。通过这些额外的结构化知识,对比预训练模型在迁移学习任务上表现出实质性的改进。
https://arxiv.org/abs/2204.09222
OpenCLIP: Reproducible scaling laws for contrastive language-image learning
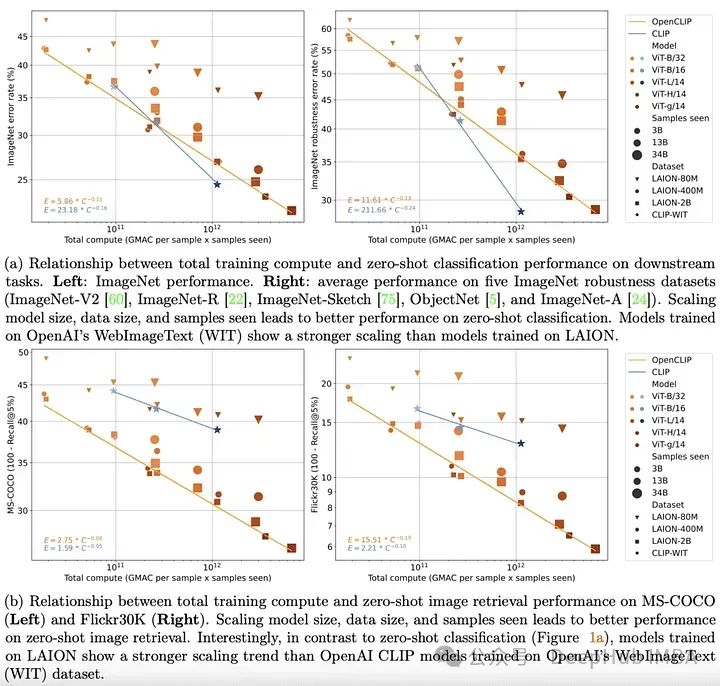
到2022年底,transformer 模型已经在文本和视觉领域建立起来。在这两个领域的开创性经验工作也清楚地表明,transformer 模型在单峰任务上的性能可以通过简单的缩放定律来很好地描述。也就是说随着训练数据量、训练时间或模型大小的增加,人们可以相当准确地预测模型的性能。
OpenCLIP通过使用迄今为止发布的最大的开源图像-文本对数据集(5B)将上面的理论扩展到多模式场景,系统地研究了训练数据对模型在零样本和微调任务中的性能的影响。与单模态情况一样,该研究揭示了模型在多模态任务上的性能在计算、所见样本和模型参数数量方面按幂律缩放。
比幂律的存在更有趣的是幂律缩放和预训练数据之间的关系。保留OpenAI的CLIP模型架构和训练方法,OpenCLIP模型在样本图像检索任务上表现出更强的缩放能力。对于ImageNet上的零样本图像分类,OpenAI的模型(在其专有数据集上训练)表现出更强的缩放能力。这些发现突出了数据收集和过滤程序对下游性能的重要性。
https://arxiv.org/abs/2212.07143
但是在OpenCLIP发布不久,LAION数据集因包含非法图像已从互联网上被下架了。
MetaCLIP: Demystifying CLIP Data
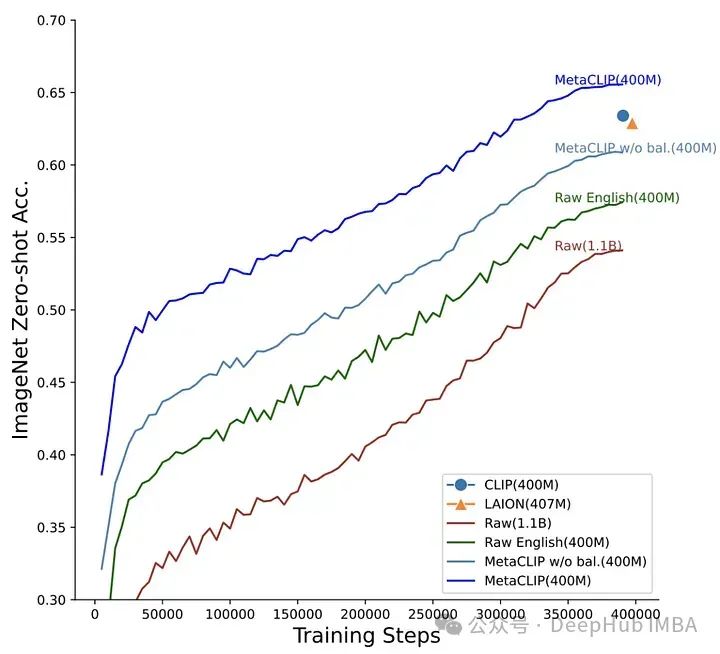
OpenCLIP试图理解下游任务的性能如何随数据量、计算量和模型参数数量的变化而变化,而MetaCLIP关注的是如何选择数据。正如作者所说,“我们认为CLIP成功的主要因素是它的数据,而不是模型架构或预训练目标。”
为了验证这一假设,作者固定了模型架构和训练步骤并进行了实验。MetaCLIP团队测试了与子字符串匹配、过滤和平衡数据分布相关的多种策略,发现当每个文本在训练数据集中最多出现20,000次时,可以实现最佳性能,为了验证这个理论他们甚至将在初始数据池中出现5400万次的单词 “photo”在训练数据中也被限制为20,000对图像-文本。使用这种策略,MetaCLIP在来自Common Crawl数据集的400M图像-文本对上进行了训练,在各种基准测试中表现优于OpenAI的CLIP模型。
https://arxiv.org/abs/2309.16671
DFN: Data Filtering Networks
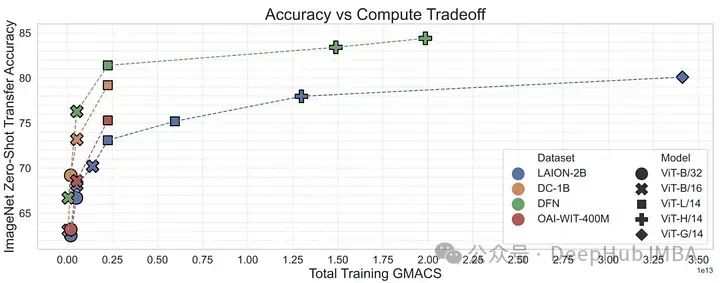
有了MetaCLIP的研究,可以说明数据管理可能是训练高性能多模态模型(如CLIP)的最重要因素。MetaCLIP的过滤策略非常成功,但它也主要基于启发式的方法。研究人员又将研究目标变为是否可以训练一个模型来更有效地进行这种过滤。
为了验证这一点,作者使用来自概念性12M的高质量数据来训练CLIP模型,从低质量数据中过滤高质量数据。这个数据过滤网络(DFN)被用来构建一个更大的高质量数据集,方法是只从一个未经管理的数据集(在本例中是Common Crawl)中选择高质量数据。在过滤后的数据上训练的CLIP模型优于仅在初始高质量数据上训练的模型和在大量未过滤数据上训练的模型。
https://arxiv.org/abs/2309.17425
总结
OpenAI的CLIP模型显著地改变了我们处理多模态数据的方式。但是CLIP只是一个开始。从预训练数据到训练方法和对比损失函数的细节,CLIP家族在过去几年中取得了令人难以置信的进步。ALIGN缩放噪声文本,K-LITE增强外部知识,OpenCLIP研究缩放定律,MetaCLIP优化数据管理,DFN增强数据质量。这些模型加深了我们对CLIP在多模态人工智能发展中的作用的理解,展示了在连接图像和文本方面的进步。
以上是文生图的基石CLIP模型的发展综述的详细内容。更多信息请关注PHP中文网其他相关文章!