



虽然我从来没见过你,但是我有可能「认识」你 —— 这是人们希望人工智能在「一眼初见」下达到的状态。
为了达到这个目的,在传统的图像识别任务中,人们在带有不同类别标签的大量图像样本上训练算法模型,让模型获得对这些图像的识别能力。而在零样本学习(ZSL)任务中,人们希望模型能够举一反三,识别在训练阶段没有见过图像样本的类别。
生成式零样本学习(GZSL)被认为是零样本学习的一种有效方法。在GZSL中,首要步骤是训练一个生成器,用以合成未见类别的视觉特征。这个生成过程是通过利用属性标签等语义描述作为条件来驱动的。一旦生成了这些虚拟的视觉特征,就可以像训练传统分类器一样,开始训练一个能够辨识出未见类别的分类模型。
生成器的培训对于生成式零样本学习算法至关重要。在理想情况下,生成器根据语义描述生成的未见类别的视觉特征样本,应该与该类别的真实样本的视觉特征具有相同的分布。这意味着生成器需要能够准确地捕捉到视觉特征之间的关系和规律,以便生成出具有高度一致性和可信度的样本。通过训练生成器,使其能够有效地学习到不同类别之间的视觉特征差异,并
在现有的生成式零样本学习方法中,生成器在被训练和使用时,都是以高斯噪声和类别整体的语义描述为条件的,这限制了生成器只能针对整个类别进行优化,而不是描述每个样本实例,所以难以准确反映真实样本视觉特征的分布,导致模型的泛化性能较差。另外,已见类与未见类所共享的数据集视觉信息,即域知识,也没有在生成器的训练过程中被充分利用,限制了知识从已见类到未见类的迁移。
为了解决这些问题,华中科技大学研究生与阿里巴巴旗下银泰商业集团的技术专家提出了一种名为视觉增强的动态语义原型方法(VADS)。该方法将已见类的视觉特征更充分地引入到语义条件中,从而让推动生成器能够学习准确的语义-视觉映射。这项研究论文《Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning》已经被计算机视觉领域顶级国际学术会议CVPR 2024所接收。
具体而言,上述研究呈现了三个创新点:
在零样本学习中,使用视觉特征来增强生成器,以便生成可靠的视觉特征,这是一种创新性的方法。
研究还引入了VDKL和VOSU两个组件,在这些组件的帮助下,数据集的视觉先验被有效获取,并且通过动态更新图像的视觉特征,预定义的类别语义描述得到了更新。这一方法有效地利用了视觉特征。
试验结果表明,本研究采用视觉特征来增强生成器的效果十分显著。这种即插即用的方法不仅具有强大的通用性,而且在提高生成器性能方面表现出色。
研究细节
VADS 由两个模块组成:(1)视觉感知域知识学习模块(VDKL)学习视觉特征的局部偏差和全局先验,即域视觉知识,这些知识取代了纯高斯噪声,提供了更丰富的先验噪声信息;(2)面向视觉的语义更新模块(VOSU)学习如何根据样本的视觉表示更新其语义原型,更新的后语义原型中也包含了域视觉知识。
最终,研究团队将两个模块的输出连接为一个动态语义原型向量,作为生成器的条件。大量实验表明,VADS 方法在常用的零样本学习数据集上实现了显著超出已有方法的性能,并可以与其他生成式零样本学习方法结合,获得精度的普遍提升。
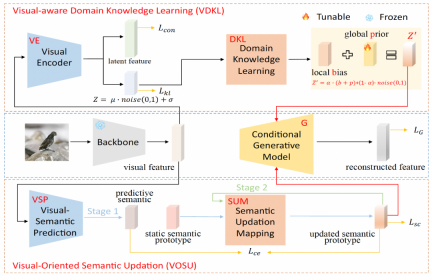
在视觉感知域知识学习模块(VDKL)中,研究团队设计了一个视觉编码器(VE)和一个域知识学习网络(DKL)。其中,VE 将视觉特征编码为隐特征和隐编码。通过使用对比损失在生成器训练阶段利用已见类图像样本训练 VE,VE 可以增强视觉特征的类别可分性。
在训练 ZSL 分类器时,生成器生成的未见类视觉特征也被输入 VE,得到的隐特征与生成的视觉特征连接,作为最终的视觉特征样本。VE 的另一个输出,即隐编码,经过 DKL 变换后形成局部偏差 b,与可学习的全局先验 p,以及随机高斯噪声一起,组合成域相关的视觉先验噪声,代替其他生成式零样本学习中常用的纯高斯噪声,作为生成器生成条件的一部分。
在面向视觉的语义更新模块(VOSU)中,研究团队设计了一个视觉语义预测器 VSP 和一个语义更新映射网络 SUM。在 VOSU 的训练阶段,VSP 以图像视觉特征为输入,生成一个能够捕获目标图像视觉模式的预测语义向量,同时,SUM 以类别语义原型为输入,对其进行更新,得到更新后的语义原型,然后通过最小化预测语义向量与更新后语义原型之间的交叉熵损失对 VSP 和 SUM 进行训练。VOSU 模块可以基于视觉特征对语义原型进行动态调整,使得生成器在合成新类别特征时能够依据更精确的实例级语义信息。
在试验部分,上述研究使用了学术界常用的三个 ZSL 数据集:Animals with Attributes 2(AWA2),SUN Attribute(SUN)和 Caltech-USCD Birds-200-2011(CUB),对传统零样本学习和广义零样本学习的主要指标,与近期有代表性的其他方法进行了全面对比。
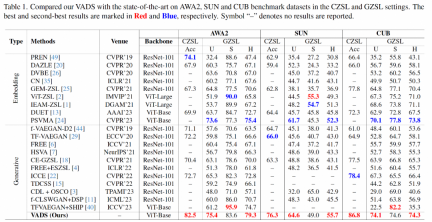
在传统零样本学习的 Acc 指标方面,该研究的方法与已有方法相比,取得了明显的精度提升,在三个数据集上分别领先 8.4%,10.3% 和 8.4%。在广义零样本学习场景,上述研究方法在未见类和已见类精度的调和平均值指标 H 上也处于领先地位。
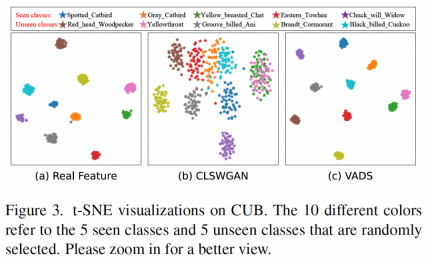
VADS 方法还可以与其他生成式零样本学习方法结合。例如,与 CLSWGAN,TF-VAEGAN 和 FREE 这三种方法结合后,在三个数据集上的 Acc 和 H 指标均有明显提升,三个数据集的平均提升幅度为 7.4%/5.9%, 5.6%/6.4% 和 3.3%/4.2%。
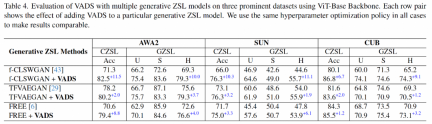
通过对生成器生成的视觉特征进行可视化可以看出,原本混淆在一起的部分类别的特征,例如下图 (b) 中显示的已见类「Yellow breasted Chat」和未见类「Yellowthroat」两类特征,在使用 VADS 方法后,在图(c)中能够被明显地分离为两个类簇,从而避免了分类器训练时的混淆。
可延展到智能安防和大模型领域
机器之心了解到,上述研究研究团队关注的零样本学习旨在使模型能够识别在训练阶段没有图像样本的新类别,在智能安防领域具有潜在的价值。
第一,处理安防场景中新出现的风险,由于安防场景下,会不断出现新的威胁类型或不寻常的行为模式,它们可能在之前的训练数据中未曾出现。零样本学习使安防系统能快速识别和响应新风险类型,从而提高安全性。
第二,减少对样本数据的依赖:获取足够的标注数据来训练有效的安防系统是昂贵和耗时的,零样本学习减少了系统对大量图像样本的依赖,从而节约了研发成本。
第三,提升动态环境下的稳定性:零样本学习使用语义描述实现对未见类模式的识别,与完全依赖图像特征的传统方法相比,对于视觉环境的变化天然具有更强的稳定性。
该技术作为解决图像分类问题的底层技术,还可以在依赖视觉分类技术的场景落地,例如人、货、车、物的属性识别,行为识别等。尤其在需要快速增加新的待识别类别,来不及收集训练样本,或者难以收集大量样本的场景(如风险识别),零样本学习技术相对于传统方法具有较大优势。
该研究技术对于当前大模型的发展有无借鉴之处?
研究者认为,生成式零样本学习的核心思想是对齐语义空间和视觉特征空间,这与当前多模态大模型中的视觉语言模型(如 CLIP)的研究目标是一致的。
它们最大的不同点是,生成式零样本学习是在预先定义好的有限类别的数据集上训练和使用,而视觉语言大模型则是通过对大数据的学习获得具有通用性的语义和视觉表征能力,不局限在有限的类别,作为基础模型,具有更宽广的应用范围。
如果技术的应用场景是特定领域,可以选择将大模型针对此领域进行适配微调,在此过程中,与本文相同或相似研究方向的工作,理论上可以带来一些有益的启发。
作者介绍
侯文金,华中科技大学硕士研究生,感兴趣的研究方向包括计算机视觉,生成建模,少样本学习等,他在阿里巴巴 - 银泰商业实习期间完成了本论文工作。
王炎,阿里巴巴 - 银泰商业技术总监,深象智能团队算法负责人。
冯雪涛,阿里巴巴 - 银泰商业资深算法专家,主要关注视觉和多模态算法在线下零售等行业的应用落地。
以上是提升生成式零样本学习能力,视觉增强动态语义原型方法入选CVPR 2024的详细内容。更多信息请关注PHP中文网其他相关文章!

 ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AM
ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AMai合并图层的快捷键是“Ctrl+Shift+E”,它的作用是把目前所有处在显示状态的图层合并,在隐藏状态的图层则不作变动。也可以选中要合并的图层,在菜单栏中依次点击“窗口”-“路径查找器”,点击“合并”按钮。
 ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AM
ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AMai橡皮擦擦不掉东西是因为AI是矢量图软件,用橡皮擦不能擦位图的,其解决办法就是用蒙板工具以及钢笔勾好路径再建立蒙板即可实现擦掉东西。
 谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM
谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM虽然谷歌早在2020年,就在自家的数据中心上部署了当时最强的AI芯片——TPU v4。但直到今年的4月4日,谷歌才首次公布了这台AI超算的技术细节。论文地址:https://arxiv.org/abs/2304.01433相比于TPU v3,TPU v4的性能要高出2.1倍,而在整合4096个芯片之后,超算的性能更是提升了10倍。另外,谷歌还声称,自家芯片要比英伟达A100更快、更节能。与A100对打,速度快1.7倍论文中,谷歌表示,对于规模相当的系统,TPU v4可以提供比英伟达A100强1.
 ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PM
ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PMai可以转成psd格式。转换方法:1、打开Adobe Illustrator软件,依次点击顶部菜单栏的“文件”-“打开”,选择所需的ai文件;2、点击右侧功能面板中的“图层”,点击三杠图标,在弹出的选项中选择“释放到图层(顺序)”;3、依次点击顶部菜单栏的“文件”-“导出”-“导出为”;4、在弹出的“导出”对话框中,将“保存类型”设置为“PSD格式”,点击“导出”即可;
 ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PM
ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PMai顶部属性栏不见了的解决办法:1、开启Ai新建画布,进入绘图页面;2、在Ai顶部菜单栏中点击“窗口”;3、在系统弹出的窗口菜单页面中点击“控制”,然后开启“控制”窗口即可显示出属性栏。
 GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AM
GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AMYann LeCun 这个观点的确有些大胆。 「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」最近,图灵奖得主 Yann LeCun 给一场辩论做了个特别的开场。而他口中的自回归,正是当前爆红的 GPT 家族模型所依赖的学习范式。当然,被 Yann LeCun 指出问题的不只是自回归模型。在他看来,当前整个的机器学习领域都面临巨大挑战。这场辩论的主题为「Do large language models need sensory grounding for meaning and u
 ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AM
ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AMai移动不了东西的解决办法:1、打开ai软件,打开空白文档;2、选择矩形工具,在文档中绘制矩形;3、点击选择工具,移动文档中的矩形;4、点击图层按钮,弹出图层面板对话框,解锁图层;5、点击选择工具,移动矩形即可。
 AI抢饭碗成真!近500家美国企业用ChatGPT取代员工,有公司省下超10万美元Apr 07, 2023 pm 02:57 PM
AI抢饭碗成真!近500家美国企业用ChatGPT取代员工,有公司省下超10万美元Apr 07, 2023 pm 02:57 PM自从ChatGPT掀起浪潮,不少人都在担心AI快要抢人类饭碗了。然鹅,现实可能更残酷QAQ......据就业服务平台Resume Builder调查统计,在1000多家受访美国企业中,用ChatGPT取代部分员工的,比例已达到惊人的48%。在这些企业中,有49%已经启用ChatGPT,还有30%正在赶来的路上。就连央视财经也为此专门发过一个报道:相关话题还曾一度冲上了知乎热榜,众网友表示,不得不承认,现在ChatGPT等AIGC工具已势不可挡——浪潮既来,不进则退。有程序员还指出:用过Copil


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

