
Meta新增两大万卡集群,投入近50000块英伟达H100 GPU

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-03-15 09:34:13764浏览

Meta日前推出两个功能强大的GPU集群,用于支持下一代生成式AI模型的训练,包括即将推出的Llama 3。
据报道,这两个数据中心都配备了高达24,576块GPU,旨在支持比之前发布的更大、更复杂的生成式AI模型。
作为一种流行的开源算法模型,Meta的Llama能与OpenAI的GPT和Google的Gemini相媲美。
Meta刷新AI集群规模
据极客网了解,这两个GPU集群都搭载了英伟达目前功能最强大的H100 GPU,规模比Meta之前推出的大型集群要庞大得多。此前,Meta的集群拥有大约16,000块Nvidia A100 GPU。
据报道,Meta已经采购了成千上万块英伟达最新推出的GPU。市场调研公司Omdia在最新报告中指出,Meta已经成为英伟达最重要的客户之一。
Meta工程师宣布,他们计划利用全新的GPU集群对现有的AI系统进行微调,以训练出更新更强大的AI系统,其中包括Llama 3。
该工程师指出,Llama 3的开发工作目前正在“进行中”,但并没有透露何时对外发布。
Meta的长期目标是发展通用人工智能(AGI)系统,因为AGI在创造性方面更接近人类,与现有的生成式AI模型有着明显的区别。
新的GPU集群将有助于Meta实现这些目标。此外,该公司正在改进PyTorch AI框架,使其能够支持更多的GPU。
两个GPU集群采用不同架构
值得一提的是,虽然这两个集群的GPU数量完全相同,都能以每秒400GB的端点相互连接,但它们采用了不同的架构。
其中,一个GPU集群可以通过融合以太网网络结构远程访问直接存储器或RDMA,该网络结构采用Arista Networks的Arista 7800与Wedge400和Minipack2 OCP机架交换机构建。另一个GPU集群使用英伟达的Quantum2 InfiniBand网络结构技术构建。
这两个集群都使用了Meta的开放式GPU硬件平台Grand Teton,该平台旨在支持大规模的AI工作负载。Grand Teton的主机到GPU带宽是其前身Zion-EX平台的四倍,计算能力、带宽以及功率是Zion-EX的两倍。
Meta表示,这两个集群采用了最新的开放式机架电源和机架基础设施,旨在为数据中心设计提供更大的灵活性。Open Rack v3允许将电源架安装在机架内部的任何地方,而不是将其固定在母线上,从而实现更灵活的配置。
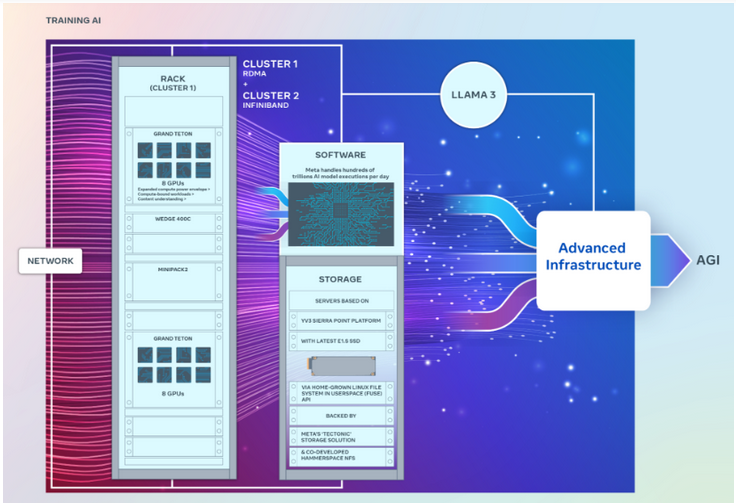
此外,每个机架的服务器数量也是可定制的,从而在每个服务器的吞吐量容量方面实现更有效的平衡。
在存储方面, 这两个GPU集群基于YV3 Sierra Point服务器平台,采用了最先进的E1.S固态硬盘。
更多GPU正在路上
Meta工程师在文中强调,该公司致力于AI硬件堆栈的开放式创新。“当我们展望未来时,我们认识到,以前或目前有效的方法可能不足以满足未来的需求。这就是我们不断评估和改进基础设施的原因。”
Meta是最近成立的AI联盟的成员之一。该联盟旨在创建一个开放的生态系统,以提高AI开发的透明度和信任,并确保每个人都能从其创新中受益。
Meta方面还透露,将继续购买更多的Nvidia H100 GPU,计划在今年年底前拥有35万块以上的GPU。这些GPU将用于持续构建AI基础设施,意味着未来还有更多、更强大的GPU集群问世。
以上是Meta新增两大万卡集群,投入近50000块英伟达H100 GPU的详细内容。更多信息请关注PHP中文网其他相关文章!