
OpenAI官宣开源Transformer Debugger!不用写代码,人人可以破解LLM黑箱

- PHPz转载
- 2024-03-12 15:16:191251浏览
AGI真的越来越近了!
为了确保人类不被AI杀死,在解密神经网络/Transfomer黑箱这一方面,OpenAI从未停下脚步。
去年5月,OpenAI团队发布了一个令人震惊的发现:GPT-4竟可以解释GPT-2的三十万神经元!
网友纷纷惊呼,智慧原来是这个样子。
 图片
图片
而就在刚刚,OpenAI超级对齐团队负责人又正式官宣,要开源内部一直使用的大杀器——Transformer调试器(Transformer Debugger)。
简之,研究者可以用TDB工具分析Transformer的内部结构,从而对小模型的特定行为进行调查。
 图片
图片
也就是说,有了这个TDB工具,未来它就可以帮我们剖析和分析AGI了!
 图片
图片
Transformer调试器将稀疏自动编码器,与OpenAI开发的「自动可解释性」——即用大模型自动解释小模型,技术相结合。
链接:OpenAI炸裂新作:GPT-4破解GPT-2大脑!30万神经元全被看透
 图片
图片
论文地址:https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html#sec-intro
值得一提的是,研究人员不用写代码,就能快速探索LLM的内部构造。
比如,它可以回答「为什么模型会输出token A而不是token B」,「为什么注意力头H会关注token T」之类的问题。
 图片
图片
因为TDB能支持神经元和注意力头,所以就可以让研究人员通过消融单个神经元来干预前向传递,并观察发生的具体变化。
不过根据Jan Leike的说法,这个工具现在还只是一个早期的版本,OpenAI放出来是希望更多的研究人员能够用上,并且在现有基础上进一步改进。
 图片
图片
项目地址:https://github.com/openai/transformer-debugger
工作原理
要理解这个Transformer Debugger的工作原理,需要回顾OpenAI在2023年5月份放出的一份和对齐有关的研究。

TDB工具是基于此前发布的两项研究,不会发布论文
简单来说,OpenAI希望用参数更大能力更强的模型(GPT-4)去自动分析小模型(GPT-2)的行为,解释它的运行机制。
 图片
图片
当时OpenAI研究的初步结果是,参数比较少的模型容易被理解,但是随着模型参数变大,层数增加,解释的效果会暴降。
 图片
图片
当时OpenAI在研究中称,限于GPT-4本身设计就不是用来解释小模型行为的,所以整体上对于GPT-2的解释成果还很差。
 图片
图片
未来需要开发出能够更好地解释模型行为的算法和工具。
而现在开源的Transformer Debugger,就是OpenAI在之后这一年的阶段性成果。
而这个「更好的工具」——Transformer Debugger,就是将「稀疏自动编码器」结合进这个「用大模型解释小模型」的技术线路中去。
然后再将之前OpenAI在可解释性研究中用GPT-4解释小模型的过程零代码化,从而大大降低了研究人员上手的门槛。
GPT-2 Small被看穿了
在GitHub项目主页,OpenAI团队成员通过视频介绍了最新Transformer调试器工具。
与Python调试器类似,TDB可以让你逐步查看语言模型输出、跟踪重要激活并分析上游激活。
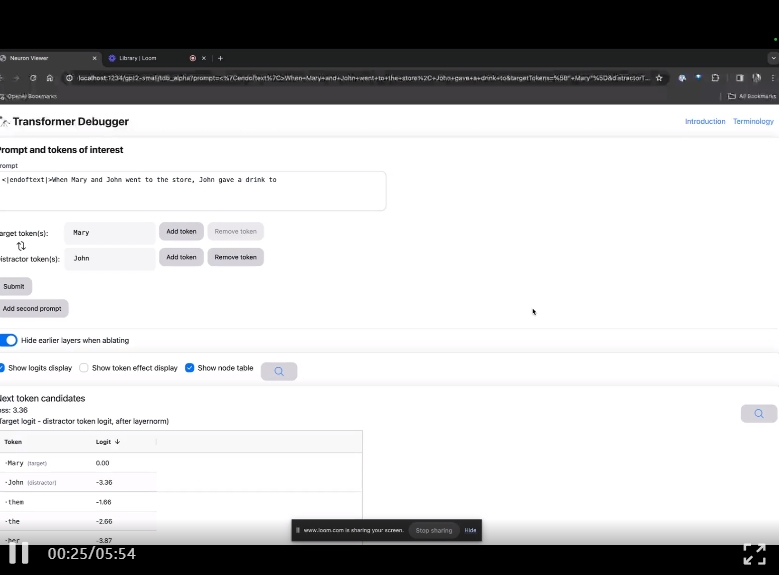
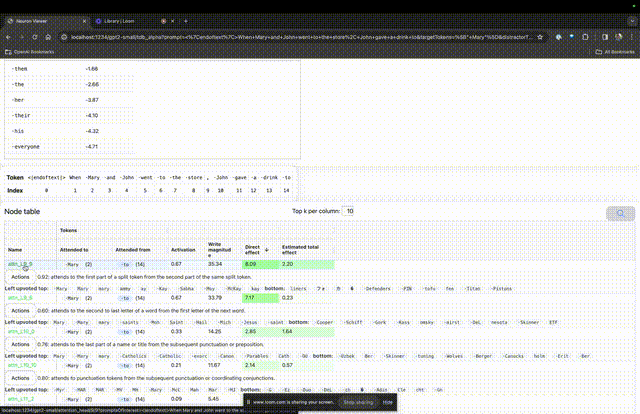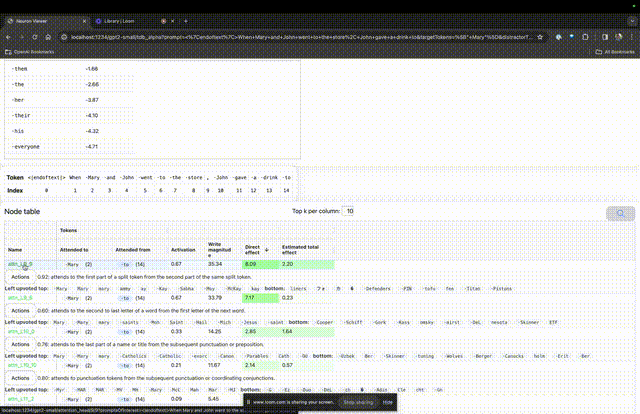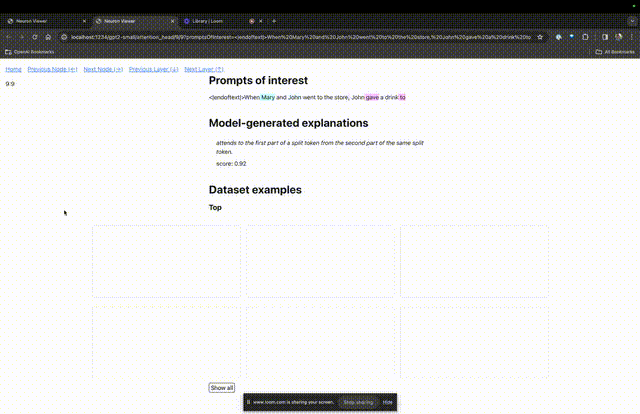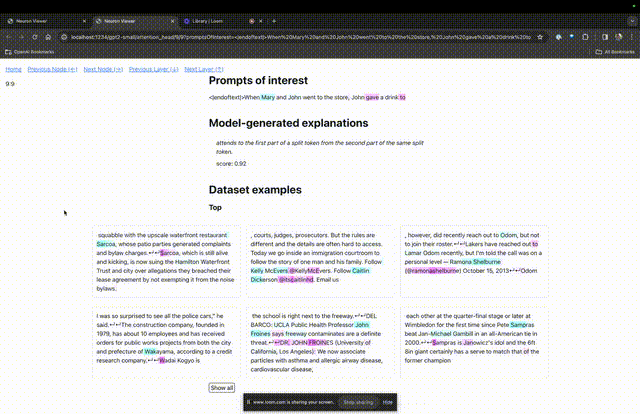
进入TDB主页,首先是「提示」一栏输入——提示和感兴趣的token:
Mary and Johon went to the store, Johon gave a drink to....
那么接下来,就是做一个「下一词」的预测,需要输入目标token,以及干扰性的token。
最后提交后,便可以看到系统给出的预测下一词候选的对数。
下面的「节点表」是TDB的核心部分。这里的每一行都对应一个节点,也就是激活一个模型组件。
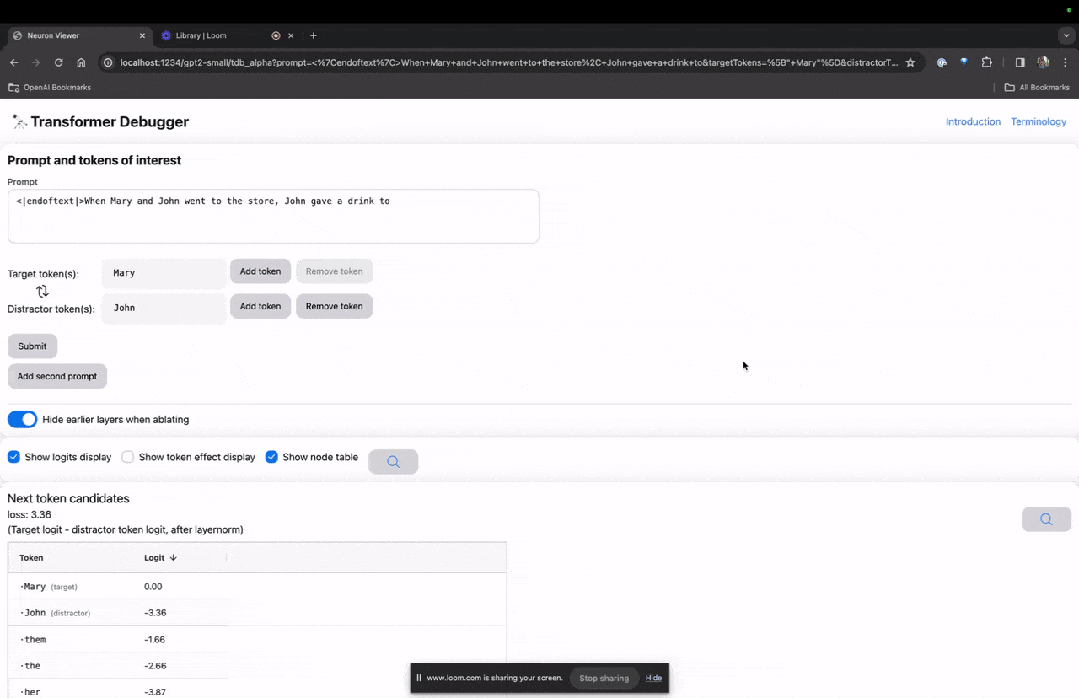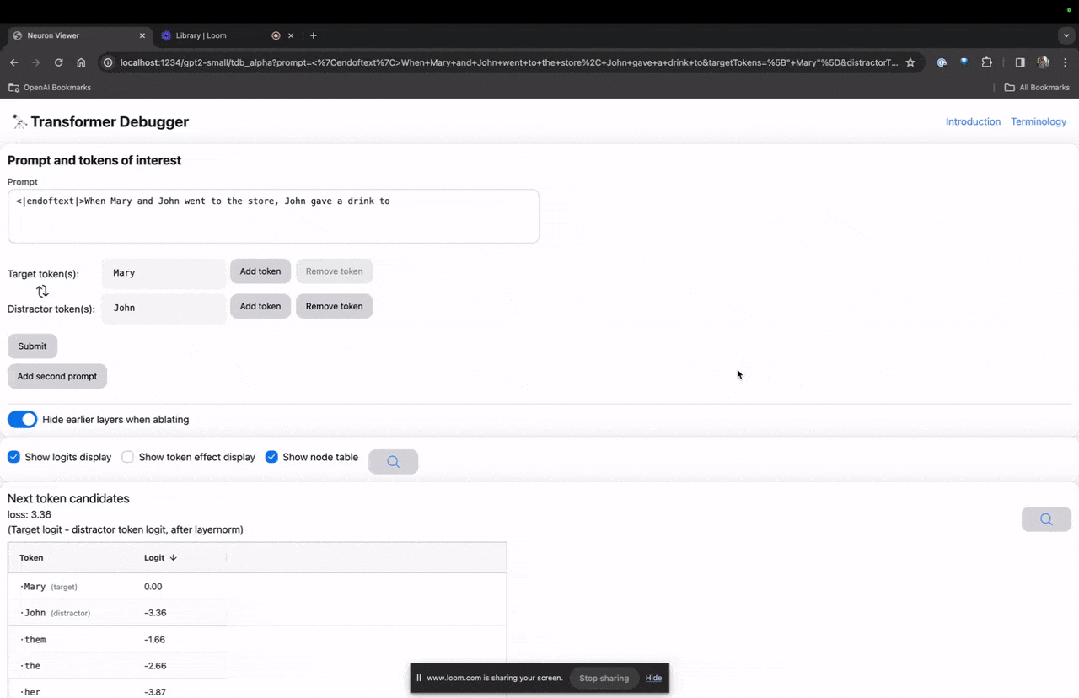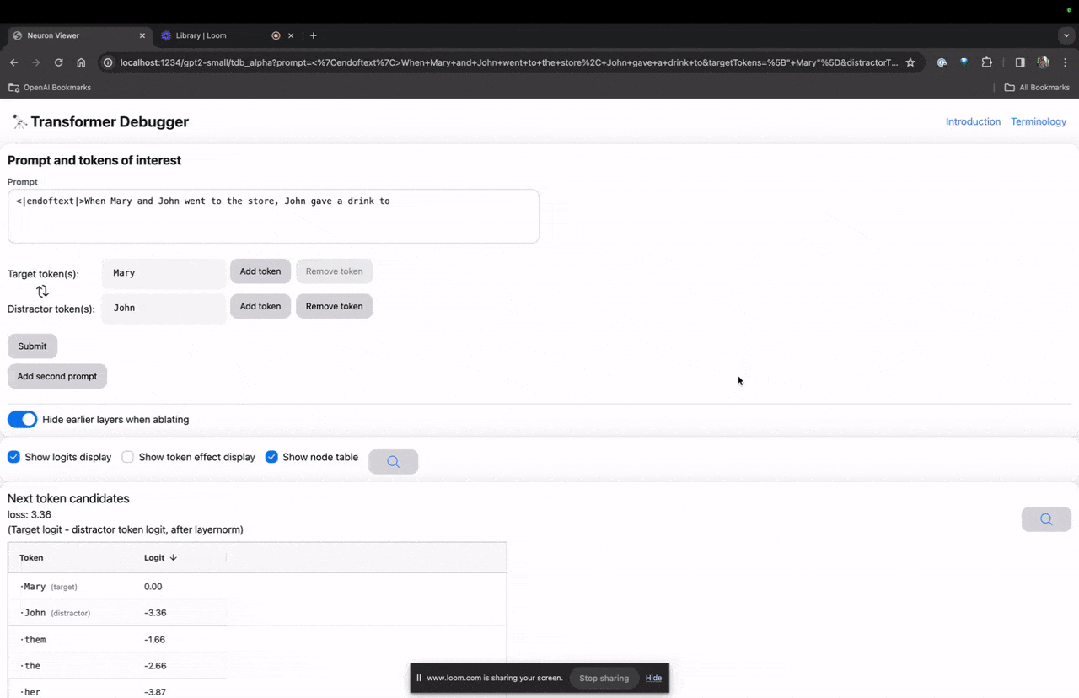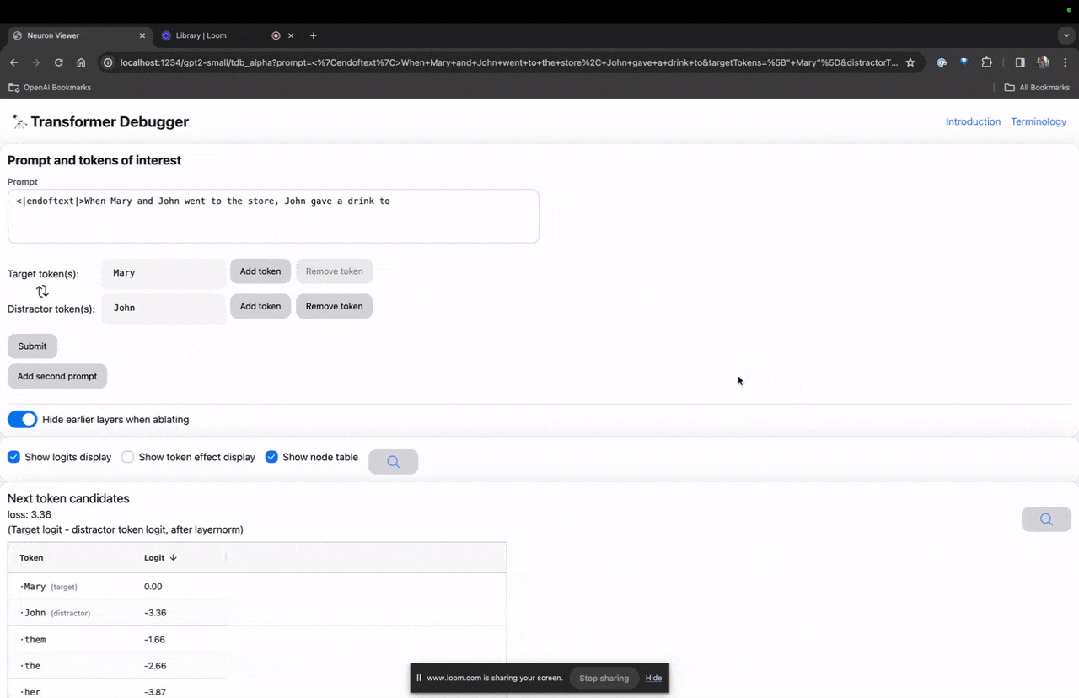 图片
图片
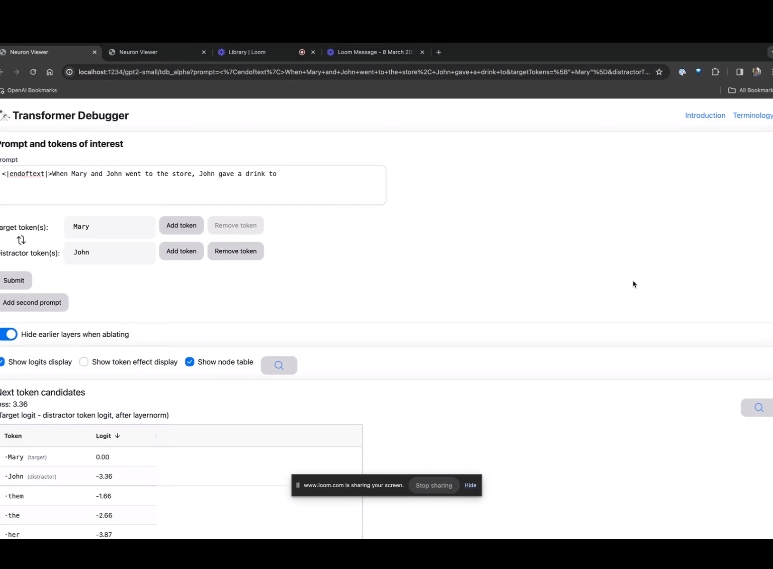
如果要了解对某个特定提示中非常重要的注意力头的功能,直接点击组件的名称。
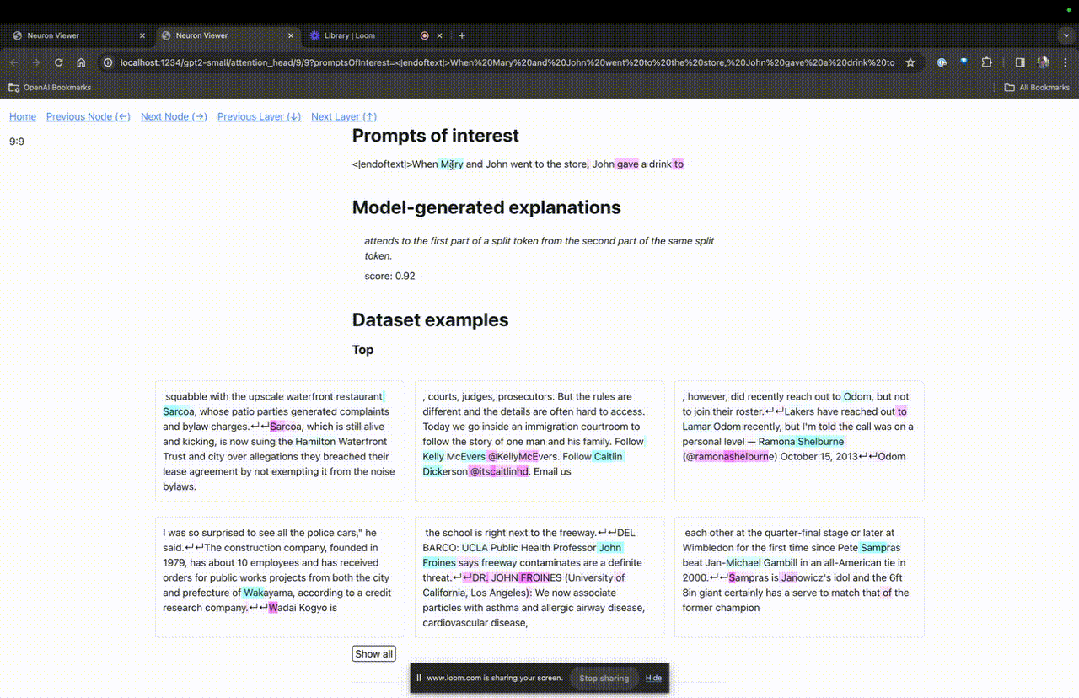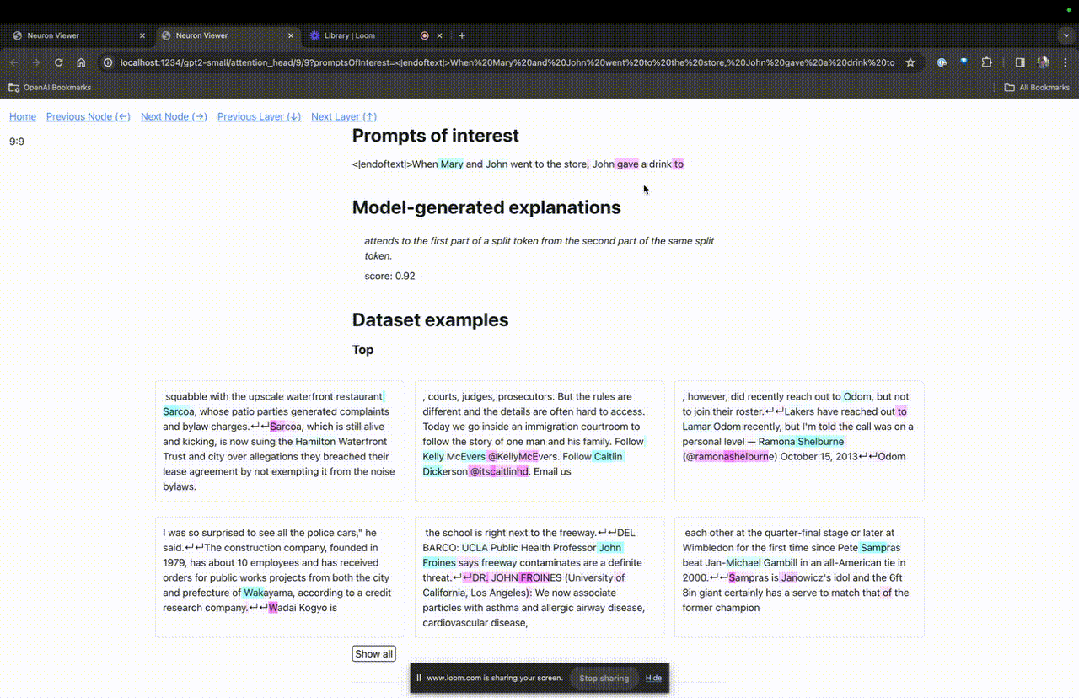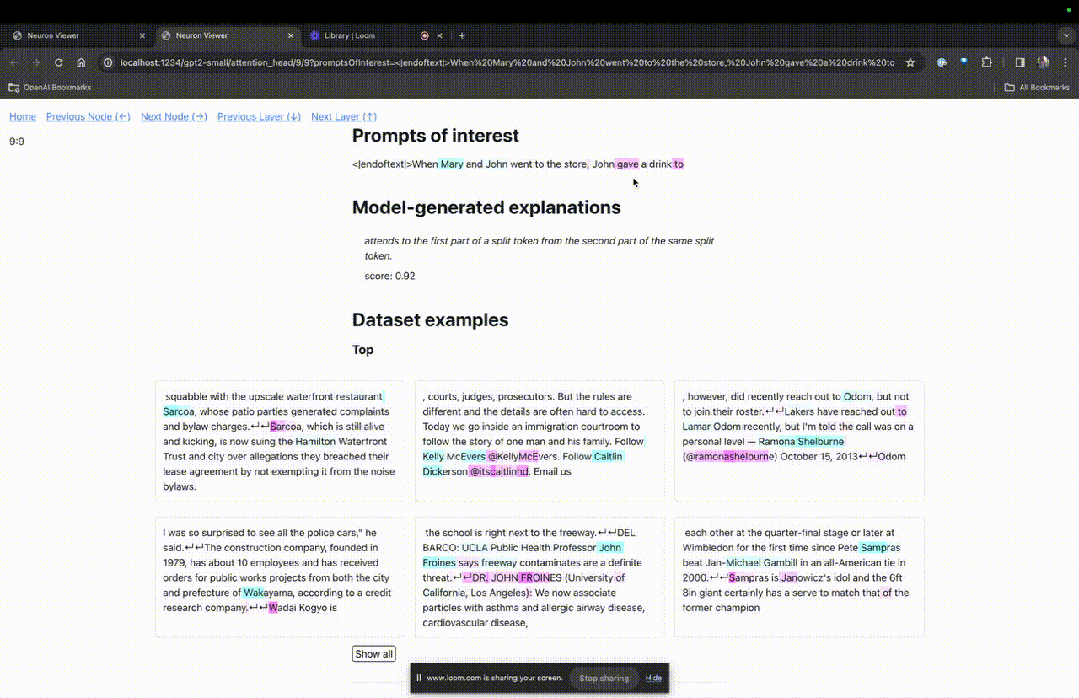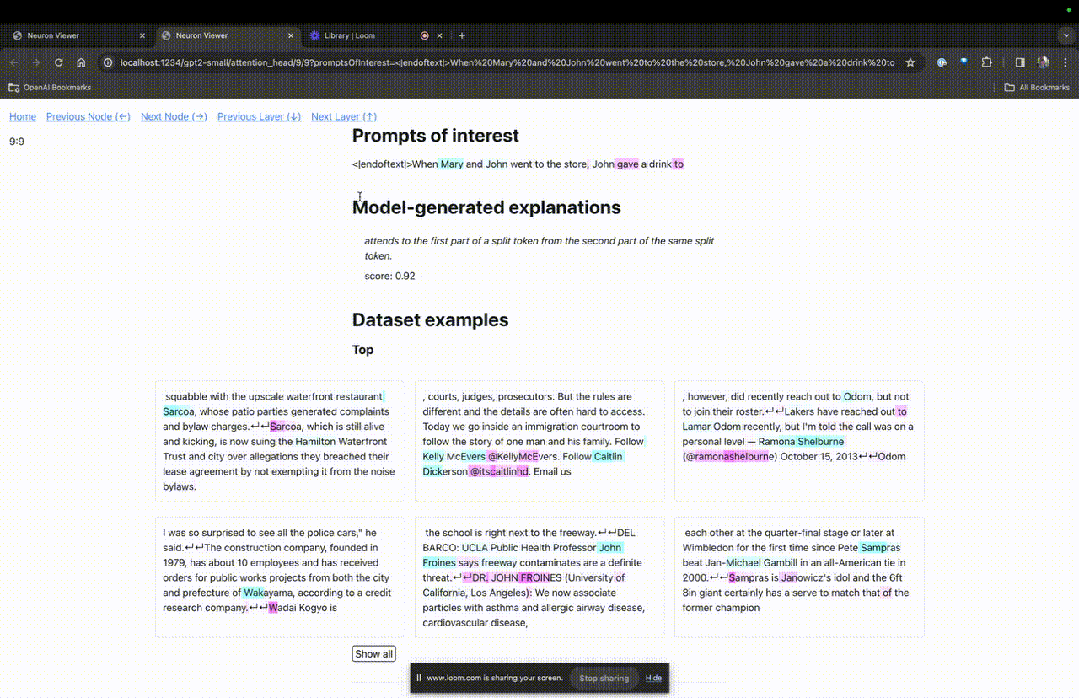
然后TDB会打开「神经元浏览器 」页面,顶部会显示之前的提示词。
 图片
图片
这里能看到浅蓝色和粉色的token。每个对应颜色的token之下,从后续标记到这个token的注意力会让一个大范数向量(large norm vector)被写入后续token中。
 图片
图片
在另外两个视频中,研究人员介绍了TDB的概念,以及其在理解回路中的应用。与此同时,他还演示了TDB如何定性地再现论文中的一个发现。
OpenAI自动可解释性研究
简单来说,OpenAI自动可解释性研究的思路是让GPT-4对神经元的行为进行自然语言解释,然后把这个过程应用到GPT-2中。
这何以成为可能?首先,我们需要「解剖」一下LLM。
像大脑一样,它们由「神经元」组成,它们会观察文本中的某些特定模式,这就会决定整个模型接下来要说什么。
比如,如果给出这么一个prompt,「哪些漫威超级英雄拥有最有用的超能力?」 「漫威超级英雄神经元」可能就会增加模型命名漫威电影中特定超级英雄的概率。
OpenAI的工具就是利用这种设定,把模型分解为单独的部分。
第一步:使用GPT-4生成解释
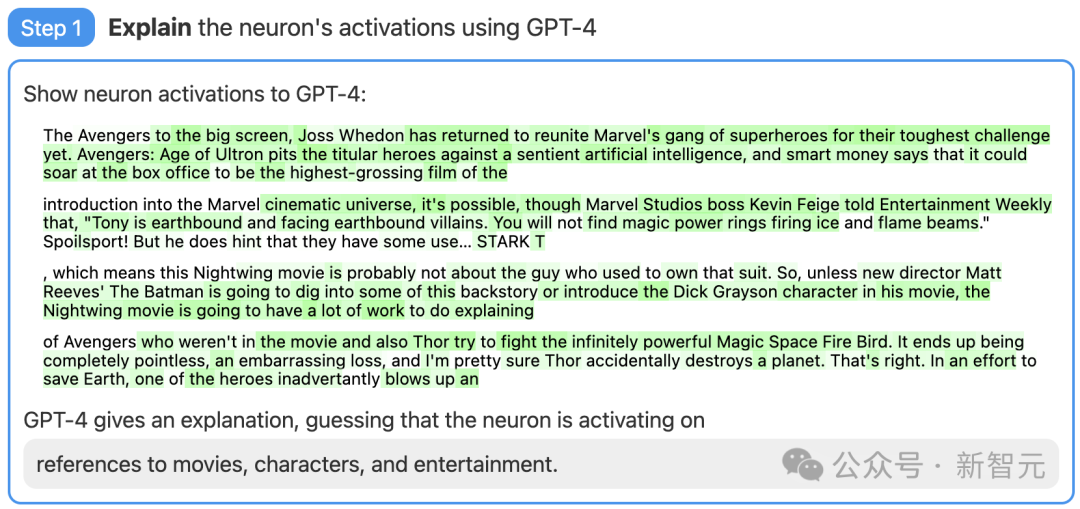
首先,找一个GPT-2的神经元,并向GPT-4展示相关的文本序列和激活。
然后,让GPT-4根据这些行为,生成一个可能的解释。
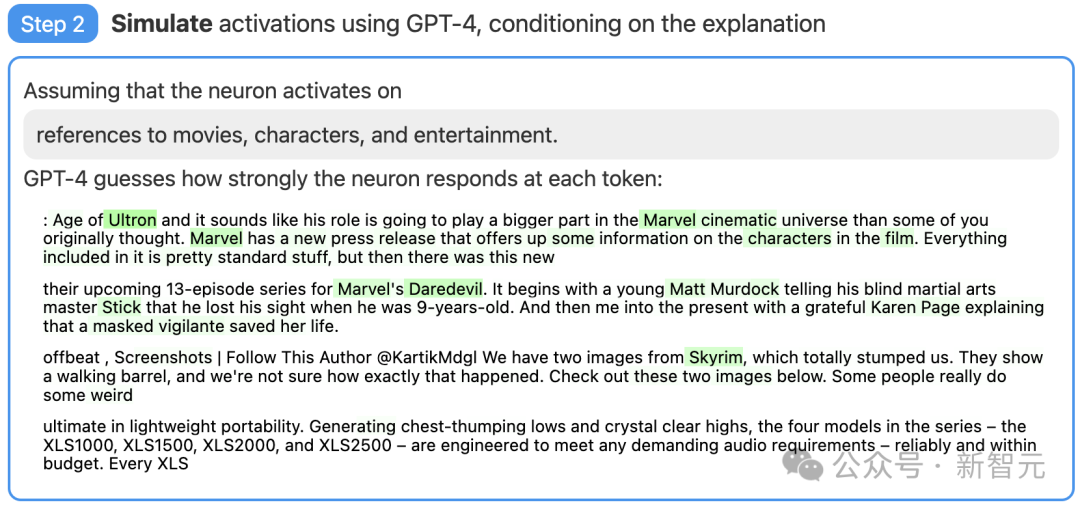
比如,在下面的例子中GPT-4就认为,这个神经元与电影、人物和娱乐有关。
 图片
图片
第二步:使用GPT-4进行模拟
接着,让GPT-4根据自己生成的解释,模拟以此激活的神经元会做什么。
 图片
图片
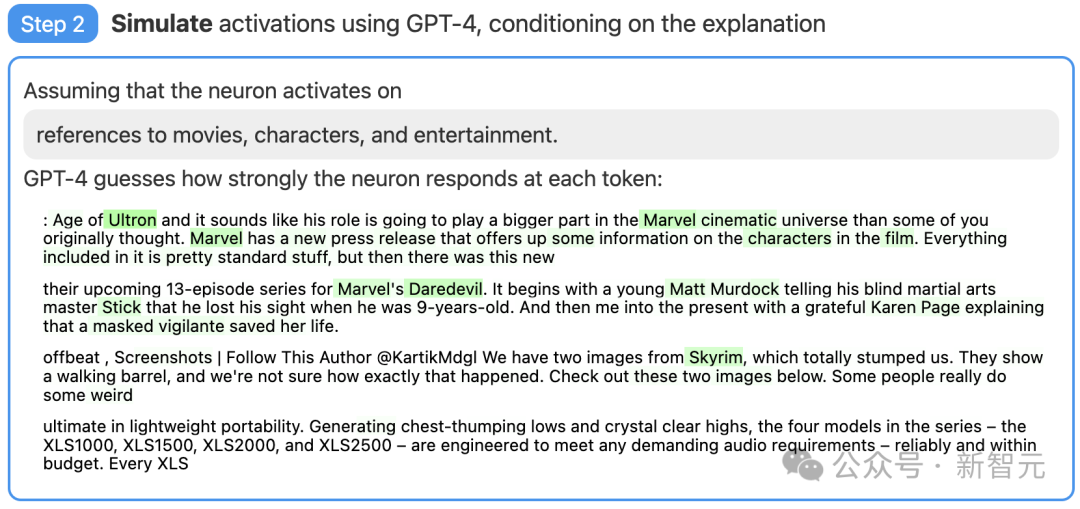
第三步:对比打分
最后,将模拟神经元(GPT-4)的行为与实际神经元(GPT-2)的行为进行比较,看看GPT-4究竟猜得有多准。
 图片
图片
还有局限
通过评分,OpenAI的研究者衡量了这项技术在神经网络的不同部分都是怎样的效果。对于较大的模型,这项技术的解释效果就不佳,可能是因为后面的层更难解释。
 图片
图片
目前,绝大多数解释评分都很低,但研究者也发现,可以通过迭代解释、使用更大的模型、更改所解释模型的体系结构等方法,来提高分数。
现在,OpenAI正在开源「用GPT-4来解释GPT-2中全部307,200个神经元」结果的数据集和可视化工具,也通过OpenAI API公开了市面上现有模型的解释和评分的代码,并且呼吁学界开发出更好的技术,产生得分更高的解释。
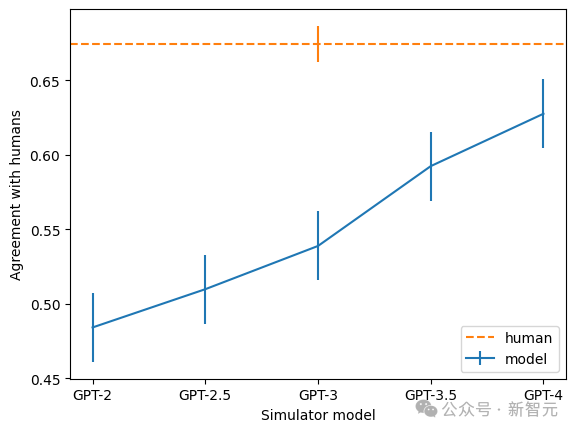
此外,团队还发现,越大的模型,解释的一致率也越高。其中,GPT-4最接近人类,但依然有不小的差距。
 图片
图片
以下是不同层神经元被激活的例子,可以看到,层数越高,就越抽象。
 图片
图片
 图片
图片
 图片
图片
 图片
图片
稀疏自动编码器设置
OpenAI使用的的稀疏自动编码器是一个在输入端具有偏置的模型,还包括一个用于编码器的具有偏置和ReLU的线性层,以及另一个用于解码器的线性层和偏置。
研究人员发现偏置项对自动编码器的性能非常重要,他们将输入和输出中应用的偏差联系起来,结果相当于从所有激活中减去固定偏差。
研究人员使用Adam优化器训练自动编码器,以使用MSE重建Transformer的MLP激活。使用MSE损耗可以避免多语义性的挑战,用损失加上L1惩罚项来鼓励稀疏性。
在训练自动编码器时,有几个原则非常重要。
首先是规模。在更多数据上训练自动编码器会使特征主观上“更清晰”且更具可解释性。所以OpenAI为自动编码器使用了80亿个训练点。
其次,在训练过程中,一些神经元会停止激活,即使在大量数据点上也是如此。
研究人员于是在训练期间「重采样」这些死神经元,允许模型代表给定的自动编码器隐藏层维度的更多特征,从而产生更好的结果。
判断指标
怎样判断自己的方法是否有效?在机器学习中可以简单地用loss作为标准,但在这里就不太容易找到类似的参考。
比如寻找一个基于信息的指标,这样可以在某种意义上说,最好的分解是最小化自动编码器和数据总信息的分解。
——但事实上,总信息通常与主观特征可解释性或激活稀疏性无关。
最终,研究人员使用了了几个附加指标的组合:
- 手动检查:特征是否看起来可以解释?
- 特征密度:实时特征数量和触发它们的token的百分比是一个非常有用的指导。
- 重建损失:衡量自动编码器重建MLP激活的程度。最终目标是解释MLP层的功能,因此MSE损耗应该很低。
- 玩具模型:使用一个已经非常了解的模型,可以清晰地评估自动编码器的性能。
不过研究人员也表示,希望从Transformer上训练的稀疏自动编码器中,为字典学习解决方案确定更好的指标。
参考资料:
以上是OpenAI官宣开源Transformer Debugger!不用写代码,人人可以破解LLM黑箱的详细内容。更多信息请关注PHP中文网其他相关文章!