




论文地址:https://arxiv.org/abs/2307.09283
代码地址:https://github.com/THU-MIG/RepViT

RepViT 在移动端ViT 架构中表现出色,展现出显着的优势。接下来,我们将探讨本研究的贡献所在。
- 文中提到,轻量级ViTs 通常比轻量级CNNs 在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(
MSHA)可以让模型学习全局表示 。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分研究。 - 在这项研究中,作者们通过整合轻量级ViTs 的有效架构选择,逐步提升了标准轻量级CNN(特别是
MobileNetV3的移动友好性。这便衍生出一个新的纯轻量级CNN 家族的诞生,即RepViT。值得注意的是,尽管RepViT 具有MetaFormer 结构,但它完全由卷积组成。 - 实验结果表明,
RepViT超越了现有的最先进的轻量级ViTs,并在各种视觉任务上显示出优于现有最先进轻量级ViTs的性能和效率,包括ImageNet 分类、COCO-2017 上的目标检测和实例分割,以及ADE20k 上的语义分割。特别地,在ImageNet上,RepViT在iPhone 12上达到了近乎1ms 的延迟和超过80% 的Top-1 准确率,这是轻量级模型的首次突破。
好了,接下来大家应该关心的应该时“如何设计到如此低延迟但精度还很6的模型”出来呢?
方法
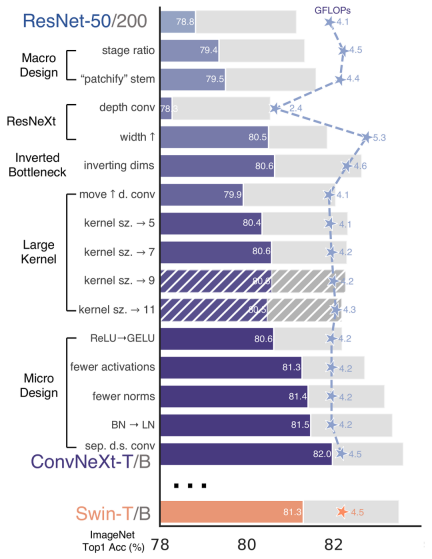
再 ConvNeXt 中,作者们是基于 ResNet50 架构的基础上通过严谨的理论和实验分析,最终设计出一个非常优异的足以媲美 Swin-Transformer 的纯卷积神经网络架构。同样地,RepViT也是主要通过将轻量级ViTs 的架构设计逐步整合到标准轻量级CNN,即MobileNetV3-L,来对其进行针对性地改造(魔改)。在这个过程中,作者们考虑了不同粒度级别的设计元素,并通过一系列步骤达到优化的目标。

训练配方的对齐
在论文中,新引入了一个用于衡量移动设备上延迟的指标,并确保训练策略与目前流行的轻量级 ViTs 保持一致。这一举措的目的是为了保证模型训练的一贯性,其中涉及到延迟度量和训练策略的调整两个关键概念。
延迟度量指标
为了更准确地衡量模型在真实移动设备上的性能,作者选择了直接测量模型在设备上的实际延迟,以此作为基准度量。这个度量方法不同于之前的研究,它们主要通过FLOPs或模型大小等指标优化模型的推理速度,这些指标并不总能很好地反映在移动应用中的实际延迟。
训练策略的对齐
这里,将 MobileNetV3-L 的训练策略调整以与其他轻量级 ViTs 模型对齐。这包括使用 AdamW 优化器【ViTs 模型必备的优化器】,进行 5 个 epoch 的预热训练,以及使用余弦退火学习率调度进行 300 个 epoch 的训练。尽管这种调整导致了模型准确率的略微下降,但可以保证公平性。
块设计的优化
接下来,基于一致的训练设置,作者们探索了最优的块设计。块设计是 CNN 架构中的一个重要组成部分,优化块设计有助于提高网络的性能。
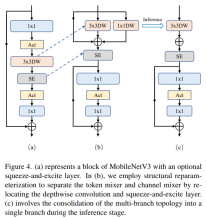
分离 Token 混合器和通道混合器
这块主要是对 MobileNetV3-L 的块结构进行了改进,分离了令牌混合器和通道混合器。原来的 MobileNetV3 块结构包含一个 1x1 扩张卷积,然后是一个深度卷积和一个 1x1 的投影层,然后通过残差连接连接输入和输出。在此基础上,RepViT 将深度卷积提前,使得通道混合器和令牌混合器能够被分开。为了提高性能,还引入了结构重参数化来在训练时为深度滤波器引入多分支拓扑。最终,作者们成功地在 MobileNetV3 块中分离了令牌混合器和通道混合器,并将这种块命名为 RepViT 块。
降低扩张比例并增加宽度
在通道混合器中,原本的扩张比例是 4,这意味着 MLP 块的隐藏维度是输入维度的四倍,消耗了大量的计算资源,对推理时间有很大的影响。为了缓解这个问题,我们可以将扩张比例降低到 2,从而减少了参数冗余和延迟,使得 MobileNetV3-L 的延迟降低到 0.65ms。随后,通过增加网络的宽度,即增加各阶段的通道数量,Top-1 准确率提高到 73.5%,而延迟只增加到 0.89ms!
宏观架构元素的优化
在这一步,本文进一步优化了MobileNetV3-L在移动设备上的性能,主要是从宏观架构元素出发,包括 stem,降采样层,分类器以及整体阶段比例。通过优化这些宏观架构元素,模型的性能可以得到显著提高。
浅层网络使用卷积提取器
 图片
图片
ViTs 通常使用一个将输入图像分割成非重叠补丁的 "patchify" 操作作为 stem。然而,这种方法在训练优化性和对训练配方的敏感性上存在问题。因此,作者们采用了早期卷积来代替,这种方法已经被许多轻量级 ViTs 所采纳。对比之下,MobileNetV3-L 使用了一个更复杂的 stem 进行 4x 下采样。这样一来,虽然滤波器的初始数量增加到24,但总的延迟降低到0.86ms,同时 top-1 准确率提高到 73.9%。
更深的下采样层
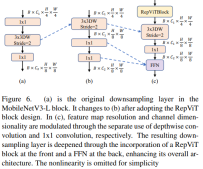
在 ViTs 中,空间下采样通常通过一个单独的补丁合并层来实现。因此这里我们可以采用一个单独和更深的下采样层,以增加网络深度并减少由于分辨率降低带来的信息损失。具体地,作者们首先使用一个 1x1 卷积来调整通道维度,然后将两个 1x1 卷积的输入和输出通过残差连接,形成一个前馈网络。此外,他们还在前面增加了一个 RepViT 块以进一步加深下采样层,这一步提高了 top-1 准确率到 75.4%,同时延迟为 0.96ms。
更简单的分类器
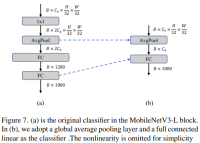
在轻量级 ViTs 中,分类器通常由一个全局平均池化层后跟一个线性层组成。相比之下,MobileNetV3-L 使用了一个更复杂的分类器。因为现在最后的阶段有更多的通道,所以作者们将它替换为一个简单的分类器,即一个全局平均池化层和一个线性层,这一步将延迟降低到 0.77ms,同时 top-1 准确率为 74.8%。
整体阶段比例
阶段比例代表了不同阶段中块数量的比例,从而表示了计算在各阶段中的分布。论文选择了一个更优的阶段比例 1:1:7:1,然后增加网络深度到 2:2:14:2,从而实现了一个更深的布局。这一步将 top-1 准确率提高到 76.9%,同时延迟为 1.02 ms。
微观设计的调整
接下来,RepViT 通过逐层微观设计来调整轻量级 CNN,这包括选择合适的卷积核大小和优化挤压-激励(Squeeze-and-excitation,简称SE)层的位置。这两种方法都能显著改善模型性能。
卷积核大小的选择
众所周知,CNNs 的性能和延迟通常受到卷积核大小的影响。例如,为了建模像 MHSA 这样的远距离上下文依赖,ConvNeXt 使用了大卷积核,从而实现了显著的性能提升。然而,大卷积核对于移动设备并不友好,因为它的计算复杂性和内存访问成本。MobileNetV3-L 主要使用 3x3 的卷积,有一部分块中使用 5x5 的卷积。作者们将它们替换为3x3的卷积,这导致延迟降低到 1.00ms,同时保持了76.9%的top-1准确率。
SE 层的位置
自注意力模块相对于卷积的一个优点是根据输入调整权重的能力,这被称为数据驱动属性。作为一个通道注意力模块,SE层可以弥补卷积在缺乏数据驱动属性上的限制,从而带来更好的性能。MobileNetV3-L 在某些块中加入了SE层,主要集中在后两个阶段。然而,与分辨率较高的阶段相比,分辨率较低的阶段从SE提供的全局平均池化操作中获得的准确率提升较小。作者们设计了一种策略,在所有阶段以交叉块的方式使用SE层,从而在最小的延迟增量下最大化准确率的提升,这一步将top-1准确率提升到77.4%,同时延迟降低到0.87ms。【这一点其实百度在很早前就已经做过实验比对得到过这个结论了,SE 层放置在靠近深层的地方效果好】
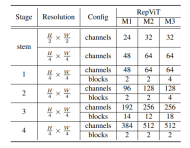
网络架构
最终,通过整合上述改进策略,我们便得到了模型RepViT的整体架构,该模型有多个变种,例如RepViT-M1/M2/M3。同样地,不同的变种主要通过每个阶段的通道数和块数来区分。
实验
图像分类

检测与分割

总结
本文通过引入轻量级 ViT 的架构选择,重新审视了轻量级 CNNs 的高效设计。这导致了 RepViT 的出现,这是一种新的轻量级 CNNs 家族,专为资源受限的移动设备设计。在各种视觉任务上,RepViT 超越了现有的最先进的轻量级 ViTs 和 CNNs,显示出优越的性能和延迟。这突显了纯粹的轻量级 CNNs 对移动设备的潜力。
以上是1.3ms耗时!清华最新开源移动端神经网络架构 RepViT的详细内容。更多信息请关注PHP中文网其他相关文章!

 GNN的基础、前沿和应用Apr 11, 2023 pm 11:40 PM
GNN的基础、前沿和应用Apr 11, 2023 pm 11:40 PM近年来,图神经网络(GNN)取得了快速、令人难以置信的进展。图神经网络又称为图深度学习、图表征学习(图表示学习)或几何深度学习,是机器学习特别是深度学习领域增长最快的研究课题。本次分享的题目为《GNN的基础、前沿和应用》,主要介绍由吴凌飞、崔鹏、裴健、赵亮几位学者牵头编撰的综合性书籍《图神经网络基础、前沿与应用》中的大致内容。一、图神经网络的介绍1、为什么要研究图?图是一种描述和建模复杂系统的通用语言。图本身并不复杂,它主要由边和结点构成。我们可以用结点表示任何我们想要建模的物体,可以用边表示两
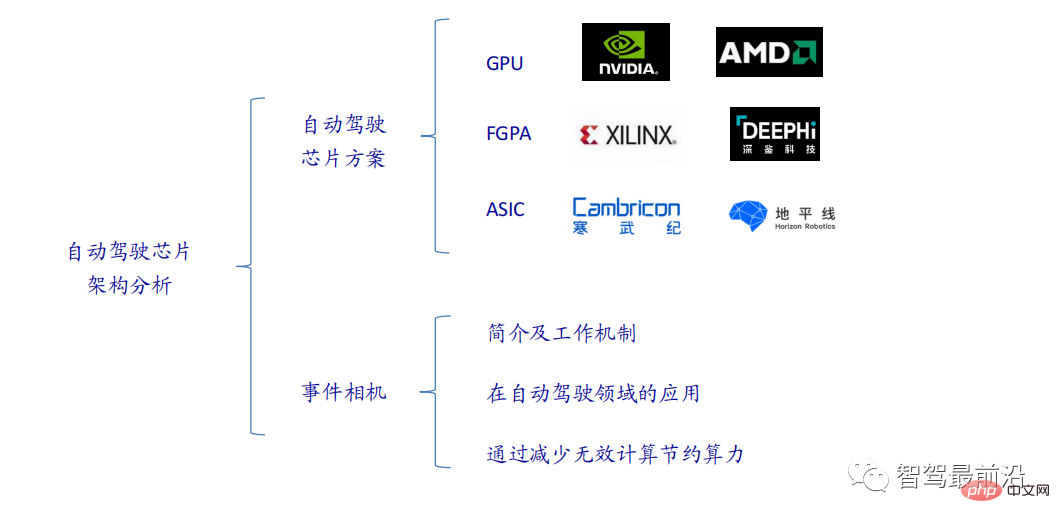 一文通览自动驾驶三大主流芯片架构Apr 12, 2023 pm 12:07 PM
一文通览自动驾驶三大主流芯片架构Apr 12, 2023 pm 12:07 PM当前主流的AI芯片主要分为三类,GPU、FPGA、ASIC。GPU、FPGA均是前期较为成熟的芯片架构,属于通用型芯片。ASIC属于为AI特定场景定制的芯片。行业内已经确认CPU不适用于AI计算,但是在AI应用领域也是必不可少。 GPU方案GPU与CPU的架构对比CPU遵循的是冯·诺依曼架构,其核心是存储程序/数据、串行顺序执行。因此CPU的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以CPU在进行大规模并行计算
 "B站UP主成功打造全球首个基于红石的神经网络在社交媒体引起轰动,得到Yann LeCun的点赞赞赏"May 07, 2023 pm 10:58 PM
"B站UP主成功打造全球首个基于红石的神经网络在社交媒体引起轰动,得到Yann LeCun的点赞赞赏"May 07, 2023 pm 10:58 PM在我的世界(Minecraft)中,红石是一种非常重要的物品。它是游戏中的一种独特材料,开关、红石火把和红石块等能对导线或物体提供类似电流的能量。红石电路可以为你建造用于控制或激活其他机械的结构,其本身既可以被设计为用于响应玩家的手动激活,也可以反复输出信号或者响应非玩家引发的变化,如生物移动、物品掉落、植物生长、日夜更替等等。因此,在我的世界中,红石能够控制的机械类别极其多,小到简单机械如自动门、光开关和频闪电源,大到占地巨大的电梯、自动农场、小游戏平台甚至游戏内建的计算机。近日,B站UP主@
 扛住强风的无人机?加州理工用12分钟飞行数据教会无人机御风飞行Apr 09, 2023 pm 11:51 PM
扛住强风的无人机?加州理工用12分钟飞行数据教会无人机御风飞行Apr 09, 2023 pm 11:51 PM当风大到可以把伞吹坏的程度,无人机却稳稳当当,就像这样:御风飞行是空中飞行的一部分,从大的层面来讲,当飞行员驾驶飞机着陆时,风速可能会给他们带来挑战;从小的层面来讲,阵风也会影响无人机的飞行。目前来看,无人机要么在受控条件下飞行,无风;要么由人类使用遥控器操作。无人机被研究者控制在开阔的天空中编队飞行,但这些飞行通常是在理想的条件和环境下进行的。然而,要想让无人机自主执行必要但日常的任务,例如运送包裹,无人机必须能够实时适应风况。为了让无人机在风中飞行时具有更好的机动性,来自加州理工学院的一组工
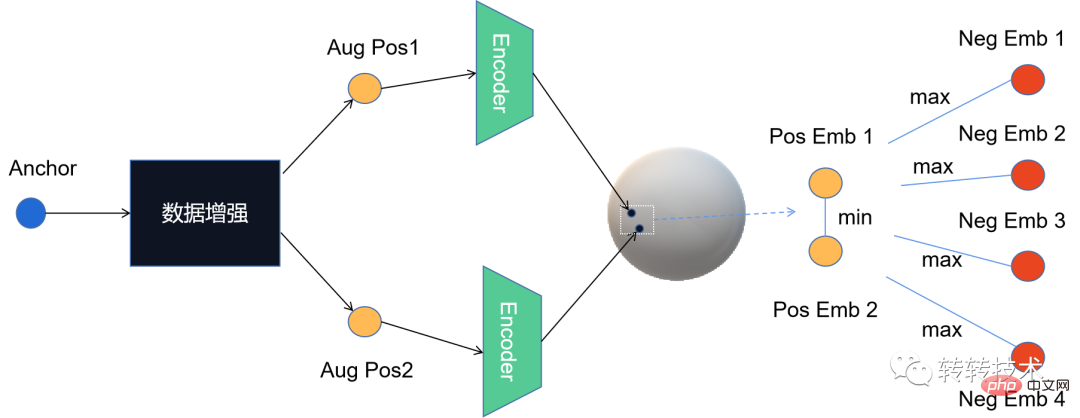 对比学习算法在转转的实践Apr 11, 2023 pm 09:25 PM
对比学习算法在转转的实践Apr 11, 2023 pm 09:25 PM1 什么是对比学习1.1 对比学习的定义1.2 对比学习的原理1.3 经典对比学习算法系列2 对比学习的应用3 对比学习在转转的实践3.1 CL在推荐召回的实践3.2 CL在转转的未来规划1 什么是对比学习1.1 对比学习的定义对比学习(Contrastive Learning, CL)是近年来 AI 领域的热门研究方向,吸引了众多研究学者的关注,其所属的自监督学习方式,更是在 ICLR 2020 被 Bengio 和 LeCun 等大佬点名称为 AI 的未来,后陆续登陆 NIPS, ACL,
 Michael Bronstein从代数拓扑学取经,提出了一种新的图神经网络计算结构!Apr 09, 2023 pm 10:11 PM
Michael Bronstein从代数拓扑学取经,提出了一种新的图神经网络计算结构!Apr 09, 2023 pm 10:11 PM本文由Cristian Bodnar 和Fabrizio Frasca 合著,以 C. Bodnar 、F. Frasca 等人发表于2021 ICML《Weisfeiler and Lehman Go Topological: 信息传递简单网络》和2021 NeurIPS 《Weisfeiler and Lehman Go Cellular: CW 网络》论文为参考。本文仅是通过微分几何学和代数拓扑学的视角讨论图神经网络系列的部分内容。从计算机网络到大型强子对撞机中的粒子相互作用,图可以用来模
 用AI寻找大屠杀后失散的亲人!谷歌工程师研发人脸识别程序,可识别超70万张二战时期老照片Apr 08, 2023 pm 04:21 PM
用AI寻找大屠杀后失散的亲人!谷歌工程师研发人脸识别程序,可识别超70万张二战时期老照片Apr 08, 2023 pm 04:21 PMAI面部识别领域又开辟新业务了?这次,是鉴别二战时期老照片里的人脸图像。近日,来自谷歌的一名软件工程师Daniel Patt 研发了一项名为N2N(Numbers to Names)的 AI人脸识别技术,它可识别二战前欧洲和大屠杀时期的照片,并将他们与现代的人们联系起来。用AI寻找失散多年的亲人2016年,帕特在参观华沙波兰裔犹太人纪念馆时,萌生了一个想法。这一张张陌生的脸庞,会不会与自己存在血缘的联系?他的祖父母/外祖父母中有三位是来自波兰的大屠杀幸存者,他想帮助祖母找到被纳粹杀害的家人的照
 微软提出自动化神经网络训练剪枝框架OTO,一站式获得高性能轻量化模型Apr 04, 2023 pm 12:50 PM
微软提出自动化神经网络训练剪枝框架OTO,一站式获得高性能轻量化模型Apr 04, 2023 pm 12:50 PMOTO 是业内首个自动化、一站式、用户友好且通用的神经网络训练与结构压缩框架。 在人工智能时代,如何部署和维护神经网络是产品化的关键问题考虑到节省运算成本,同时尽可能小地损失模型性能,压缩神经网络成为了 DNN 产品化的关键之一。DNN 压缩通常来说有三种方式,剪枝,知识蒸馏和量化。剪枝旨在识别并去除冗余结构,给 DNN 瘦身的同时尽可能地保持模型性能,是最为通用且有效的压缩方法。三种方法通常来讲可以相辅相成,共同作用来达到最佳的压缩效果。然而现存的剪枝方法大都只针对特定模型,特定任务,且需要很


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

