



写在前面&个人理解
近年来,自动驾驶技术中以视觉为中心的3D感知迅速取得进展。尽管各种3D感知模型在结构和概念上有许多相似之处,但在特征表示、数据格式和目标方面仍存在一些差异,这给统一高效的3D感知框架设计带来了挑战。因此,研究人员正努力寻找解决方案,以便更好地整合不同模型之间的差异,从而构建更加完善和高效的3D感知系统。这种努力有望为自动驾驶领域带来更为可靠和先进的技术,使其在复杂环境下具备更强
特别是BEV下的检测任务和Occupancy任务,想做好联合训练,还是很难的,不稳定和效果不可控让很多应用头大。UniVision是一个简单高效的框架,它统一了以视觉为中心的3D感知中的两个主要任务,即占用预测和目标检测。核心点是一个用于互补2D-3D feature transformation的显式-隐式视图变换模块,UniVision提出了一个局部全局特征提取和融合模块,用于高效和自适应的体素和BEV特征提取、增强和交互。
在数据增强部分,UniVision还提出了一种联合占用检测数据增强策略和渐进式loss weight调整策略,以提高多任务框架训练的效率和稳定性。在四个公共基准上对不同的感知任务进行了广泛的实验,包括无场景激光雷达分割、无场景检测、OpenOccupancy和Occ3D。UniVision在每个基准上分别以+1.5 mIoU、+1.8 NDS、+1.5 mIoU和+1.8 mIoU的增益实现了SOTA。UniVision框架可以作为统一的以视觉为中心的3D感知任务的高性能基线。
如果对BEV和Occupancy任务不熟悉的同学,也欢迎大家进一步学习我们的BEV感知教程和Occupancy占用网络教程,了解更多技术细节!
当前3D感知领域的状态
3D感知是自动驾驶系统的首要任务,其目的是利用一系列传感器(如激光雷达、雷达和相机)获得的数据来全面了解驾驶场景,用于后续的规划和决策。过去,由于来自点云数据的精确3D信息,3D感知领域一直由基于激光雷达的模型主导。然而,基于激光雷达的系统成本高昂,容易受到恶劣天气的影响,而且部署起来不方便。相比之下,基于视觉的系统具有许多优点,如低成本、易于部署和良好的可扩展性。因此,以视觉为中心的三维感知引起了研究者的广泛关注。
最近,通过特征表示变换、时间融合和监督信号设计,基于视觉的3D检测得到了显著改进,不断缩小了与基于激光雷达的模型的差距。除此之外,近年来基于视觉的占用任务得到了快速发展。与使用3D box来表示一些目标不同,占用率可以更全面地描述驾驶场景的几何和语义,并且不太局限于目标的形状和类别。
尽管检测方法和占用方法在结构和概念上有很多相似之处,但同时处理这两项任务并探索它们之间的相互关系并没有得到很好的研究。 占用模型和检测模型通常提取不同的特征表示。 占用预测任务需要在不同的空间位置上进行详尽的语义和几何判断,因此体素表示被广泛用于保存细粒度的3D信息。在检测任务中,BEV表示是优选的,因为大多数对象处于相同的水平水平面上,具有较小的重叠。
与BEV表示相比,体素表示是精细的,但效率较低。此外,许多高级算子主要针对2D特征进行设计和优化,使其与3D体素表示的集成不那么简单。BEV表示更具时间效率和内存效率,但对于密集空间预测来说,它是次优的,因为它在高度维度上丢失了结构信息。除了特征表示,不同的感知任务在数据格式和目标方面也有所不同。因此,确保训练多任务3D感知框架的统一性和效率是一个巨大的挑战。
UniVision网络结构

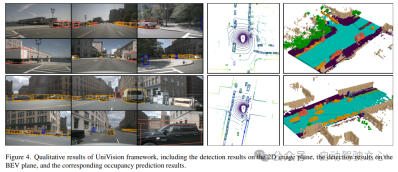
UniVision框架的总体结构如图1所示。该框架接收来自N个周围相机的多视角图像作为输入,并通过图像特征提取网络提取图像特征。接着,利用Ex-Im视图变换模块将2D图像特征升级为3D体素特征,该模块结合了深度引导的显式特征提升和查询引导的隐式特征采样。体素特征经过局部全局特征提取和融合block处理,以分别提取局部上下文感知的体素特征和全局上下文感知的BEV特征。随后,通过交叉表示特征交互模块对用于不同下游感知任务的体素特征和BEV特征进行信息交换。在训练阶段,UniVision框架采用联合Occ-Det数据增强和逐步调整loss权重的策略,以有效地进行训练。
1)Ex-Im View Transform
深度导向显式特征提升。这里遵循LSS方法:
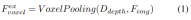
2)查询引导的隐式特征采样。然而,在表示3D信息方面存在一些缺陷。的精度与估计的深度分布的精度高度相关。此外,LSS生成的点分布不均匀。点在相机附近密集,在距离上稀疏。因此,我们进一步使用查询引导的特征采样来补偿的上述缺点。
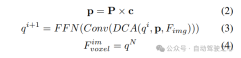
与从LSS生成的点相比,体素查询在3D空间中均匀分布,并且它们是从所有训练样本的统计特性中学习的,这与LSS中使用的深度先验信息无关。因此,和相互补充,将它们连接起来作为视图变换模块的输出特征:
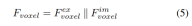
2)局部全局特征提取与融合
给定输入体素特征,首先将特征叠加在Z轴上,并使用卷积层来减少通道,以获得BEV特征:
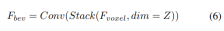
然后,模型分成两个平行的分支进行特征提取和增强。局部特征提取+全局特征提取,以及最后的交叉表示特征交互!如图1(b)中所示。
3)损失函数与检测头
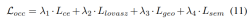
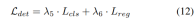

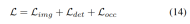
渐进式loss weight调整策略。在实践中,发现直接结合上述损失往往会导致训练过程失败,网络无法收敛。在训练的早期阶段,体素特征Fvoxel是随机分布的,并且占用头和检测头中的监督比收敛中的其他损失贡献更小。同时,检测任务中的分类损失Lcls等损失项目非常大,并且在训练过程中占主导地位,使得模型难以优化。为了克服这一问题,提出了渐进式损失权重调整策略来动态调整损失权重。具体而言,将控制参数δ添加到非图像级损失(即占用损失和检测损失)中,以调整不同训练周期中的损失权重。控制权重δ在开始时被设置为较小的值Vmin,并在N个训练时期中逐渐增加到Vmax:
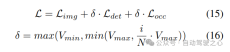
4)联合Occ-Det空间数据增强
在3D检测任务中,除了常见的图像级数据增强之外,空间级数据增强在提高模型性能方面也是有效的。然而,在占用任务中应用空间级别增强并不简单。当我们将数据扩充(如随机缩放和旋转)应用于离散占用标签时,很难确定生成的体素语义。因此,现有的方法只应用简单的空间扩充,如占用任务中的随机翻转。
为了解决这个问题,UniVision提出了一种联合Occ-Det空间数据增强,以允许在框架中同时增强3D检测任务和占用任务。由于3D box标签是连续值,并且可以直接计算增强的3D box进行训练,因此遵循BEVDet中的增强方法进行检测。尽管占用标签是离散的并且难以操作,但体素特征可以被视为连续的,并且可以通过采样和插值等操作来处理。因此建议对体素特征进行变换,而不是直接对占用标签进行操作以进行数据扩充。
具体来说,首先对空间数据增强进行采样,并计算相应的3D变换矩阵。对于占有标签及其voxel indices ,我们计算了它们的三维坐标。然后,将应用于,并对其进行归一化,以获得增强体素特征中的 voxel indices :
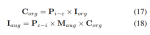
实验结果对比
使用了多个数据集进行验证,NuScenes LiDAR Segmentation、NuScenes 3D Object Detection、OpenOccupancy和Occ3D。
NuScenes LiDAR Segmentation:根据最近的OccFormer和TPVFormer,使用相机图像作为激光雷达分割任务的输入,并且激光雷达数据仅用于提供用于查询输出特征的3D位置。使用mIoU作为评估度量。
NuScenes 3D Object Detection:对于检测任务,使用nuScenes的官方度量,即nuScene检测分数(NDS),它是平均mAP和几个度量的加权和,包括平均平移误差(ATE)、平均尺度误差(ASE)、平均方向误差(AOE)、平均速度误差(AVE)和平均属性误差(AAE)。
OpenOccupancy:OpenOccupancy基准基于nuScenes数据集,提供512×512×40分辨率的语义占用标签。标记的类与激光雷达分割任务中的类相同,使用mIoU作为评估度量!
Occ3D:Occ3D基准基于nuScenes数据集,提供200×200×16分辨率的语义占用标签。Occ3D进一步提供了用于训练和评估的可见mask。标记的类与激光雷达分割任务中的类相同,使用mIoU作为评估度量!
1)Nuscenes激光雷达分割
表1显示了nuScenes LiDAR分割基准的结果。UniVision显著超过了最先进的基于视觉的方法OccFormer 1.5% mIoU,并在排行榜上创下了基于视觉的模型的新纪录。值得注意的是,UniVision还优于一些基于激光雷达的模型,如PolarNe和DB-UNet。
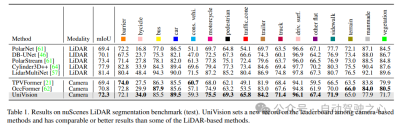
2)NuScenes 3D目标检测任务
如表2所示,当使用相同的训练设置进行公平比较时,UniVision显示出优于其他方法。与512×1408图像分辨率的BEVDepth相比,UniVision在mAP和NDS方面分别获得2.4%和1.1%的增益。当放大模型并将UniVision与时间输入相结合时,它进一步以显著的优势优于基于SOTA的时序检测器。UniVision通过较小的输入分辨率实现了这一点,并且它不使用CBGS。
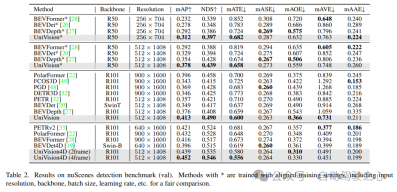
3)OpenOccupancy结果对比
OpenOccupancy基准测试的结果如表3所示。UniVision在mIoU方面分别显著超过了最近的基于视觉的占用方法,包括MonoScene、TPVFormer和C-CONet,分别为7.3%、6.5%和1.5%。此外,UniVision超越了一些基于激光雷达的方法,如LMSCNet和JS3C-Net。
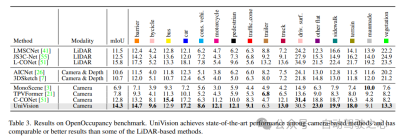
4)Occ3D实验结果
表4列出了Occ3D基准测试的结果。在不同的输入图像分辨率下,UniVision在mIoU方面显著优于最近的基于视觉的方法,分别超过2.7%和1.8%。值得注意的是,BEVFormer和BEVDet-stereo加载预先训练的权重,并在推理中使用时间输入,而UniVision没有使用它们,但仍然实现了更好的性能。
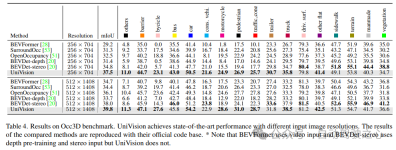
5)组件在检测任务中的有效性
在表5中显示了检测任务的消融研究。当将基于BEV的全局特征提取分支插入基线模型时,性能提高了1.7%mAP和3.0%NDS。当将基于体素的占用任务作为辅助任务添加到检测器时,该模型的mAP增益提高了1.6%。当从体素特征中明确引入交叉表示交互时,该模型实现了最佳性能,与基线相比,mAP和NDS分别提高了3.5%和4.2%;
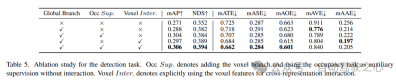
6)占用任务中组件的有效性
在表6中显示了占用任务的消融研究。基于体素的局部特征提取网络为基线模型带来了1.96%mIoU增益的改进。当检测任务被引入作为辅助监督信号时,模型性能提高了0.4%mIoU。
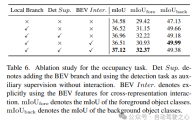
7)其它
表5和表6显示,在UniVision框架中,检测任务和占用任务都是相辅相成的。对于检测任务,占用监督可以提高mAP和mATE度量,这表明体素语义学习有效地提高了检测器对目标几何的感知,即中心度和尺度。对于占用任务,检测监督显著提高了前景类别(即检测类别)的性能,从而实现了整体改进。
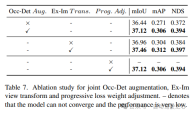
在表7中展示了联合Occ-Det空间增强、Ex-Im视图转换模块和渐进loss weight调整策略的有效性。通过所提出的空间增强和所提出的视图变换模块,它在mIoU、mAP和NDS度量上显示了检测任务和占用任务的显著改进。loss weight调整策略能够有效地训练多任务框架。如果没有这一点,统一框架的训练就无法收敛,性能也很低。
参考
论文链接:https://arxiv.org/pdf/2401.06994.pdf
论文名称:UniVision: A Unified Framework for Vision-Centric 3D Perception
以上是逆天UniVision:BEV检测和Occ联合统一框架,双SOTA!的详细内容。更多信息请关注PHP中文网其他相关文章!


 Kaggle Grandmasters使用的顶级Python图书馆Apr 17, 2025 am 10:03 AM
Kaggle Grandmasters使用的顶级Python图书馆Apr 17, 2025 am 10:03 AM解锁Kaggle Grandmasters的秘密:顶级Python图书馆揭示了 Kaggle是数据科学竞赛的主要平台,拥有精选的精英表演者:Kaggle Grandmasters。 这些人一贯提供Innova
 AI PC会改变您的工作场所的10种方法-Analytics VidhyaApr 17, 2025 am 09:59 AM
AI PC会改变您的工作场所的10种方法-Analytics VidhyaApr 17, 2025 am 09:59 AM工作的未来:AI PC将如何彻底改变工作场所 人工智能(AI)集成到个人计算机(AI PC)中代表了工作场所技术的重大飞跃。 AI PC,定义为AI的融合
 如何在Excel中冷冻窗格?Apr 17, 2025 am 09:56 AM
如何在Excel中冷冻窗格?Apr 17, 2025 am 09:56 AMExcel冻结窗格功能详解:高效处理大型数据集 Microsoft Excel是组织和分析数据的优秀工具之一,而“冻结窗格”功能更是其一大亮点。此功能允许您固定特定行或列,使其在浏览其余电子表格时保持可见,从而简化数据监控和比较。本文将深入探讨Excel冻结窗格功能的使用方法,并提供一些实用技巧和示例。 功能概述 Excel的冻结窗格功能可在滚动浏览大型数据集时,保持特定行或列可见,方便数据监控和比较。 提升导航效率,保持标题可见,简化大型电子表格中的数据比较。 提供通过“视图”选项卡和“冻
 NEO4J与亚马逊海王星:数据工程中的图形数据库Apr 17, 2025 am 09:52 AM
NEO4J与亚马逊海王星:数据工程中的图形数据库Apr 17, 2025 am 09:52 AM导航互连数据的复杂性:Neo4J与亚马逊海王星 在当今数据丰富的世界中,有效管理复杂的互连信息至关重要。尽管传统数据库仍然相关,但他们经常与HI斗争
 META SAM 2:建筑,应用和局限性-Analytics VidhyaApr 17, 2025 am 09:40 AM
META SAM 2:建筑,应用和局限性-Analytics VidhyaApr 17, 2025 am 09:40 AMMeta的细分段的任何模型2(SAM-2):实时图像和视频细分方面的巨大飞跃 Meta再次通过SAM-2推动了人工智能的界限,SAM-2是计算机视觉的开创性进步
 人工智能工作流程和消费者体验的数据策略Apr 17, 2025 am 09:39 AM
人工智能工作流程和消费者体验的数据策略Apr 17, 2025 am 09:39 AM通过AI增强数字消费者体验:一种数据驱动的方法 数字景观具有激烈的竞争力。 本文探讨了人工智能(AI)如何显着改善数字平台上的消费者体验。我们会考试
 稳定扩散中的位置编码是什么? - 分析VidhyaApr 17, 2025 am 09:34 AM
稳定扩散中的位置编码是什么? - 分析VidhyaApr 17, 2025 am 09:34 AM稳定的扩散:在文本到图像中揭示位置编码的力量 想象一下,从简单的文本描述中产生令人叹为观止的高分辨率图像。 这是稳定扩散的力量,一种尖端的文本对图像模型


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

记事本++7.3.1
好用且免费的代码编辑器

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

WebStorm Mac版
好用的JavaScript开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

