
生成速度快SDXL一倍,9GB GPU也能运行,Stable Cascade来搞性价比了

- WBOY转载
- 2024-02-16 18:45:25838浏览
硬件要求越来越低,生成速度越来越快。
Stability AI 作为文本到图像的先驱,不仅引领潮流,也不断在模型质量上取得新突破。这次,它实现了性价比的突破。
就在前几天,Stability AI 又有新动作了:Stable Cascade 的研究预览版被推出。这款文本到图像模型进行了创新,它引入了一个三阶段方法,为质量、灵活性、微调和效率设定了新的基准,重点是进一步消除硬件障碍。此外,Stability AI 发布了训练和推理代码,允许进一步自定义模型及其输出。该模型可在 diffusers 库中进行推理。该模型以非商业许可发布,仅允许非商业使用。

原文链接:https://stability.ai/news/introducing-stable-cascade
代码地址:https://github.com/Stability-AI/StableCascade
体验地址:https://huggingface.co/spaces/multimodalart/stable-cascade
一如既往简单操作就能够生成目标图像:输入对图像的文字描述即可。

图源:https://twitter.com/multimodalart/status/1757391981074903446
Stable Cascade 的生成速度极快。X 平台用户 @GozukaraFurkan 发文表示它只需要大约 9GB 的 GPU 内存,且速度依旧能保持得较好。

图源:https://twitter.com/skirano/status/1757479638324883753
网友在生成过程中发现新模型在构图和细节方面有明显的提升,文字生成有了很大的进步:生成较短的单词 / 词组正确率比较高,长句也有一定概率可以完成(限英文),文字与画面的融合也非常好。

图源:https://twitter.com/ZHOZHO672070/status/1757779330443215065

图源:https://twitter.com/tyyleai/status/1757883017329054104
用户 @AIWarper 尝试了一些不同的艺术家风格测试。

prompt:Nightmare on Elm Street。艺术家风格参考如下:左上为 Makoto Shinkai,左下为 Tomer Hanuka,右上为 Raphael Kirchner,右下为 Takato Yamamoto。
不过,生成人物面部时可以发现,人物的皮肤细节并不太好,有种「十级磨皮」的感觉。

图源:https://twitter.com/vitor_dlucca/status/1757511080287355093
技术细节
Stable Cascade 与 Stable Diffusion 模型系列不同, 它建立在由三个不同模型组成的管道上:阶段 A、B 和 C。这种架构可以对图像进行分层压缩,利用高度压缩的潜在空间实现较为出色的输出。这几个部分是如何组合在一起的呢?
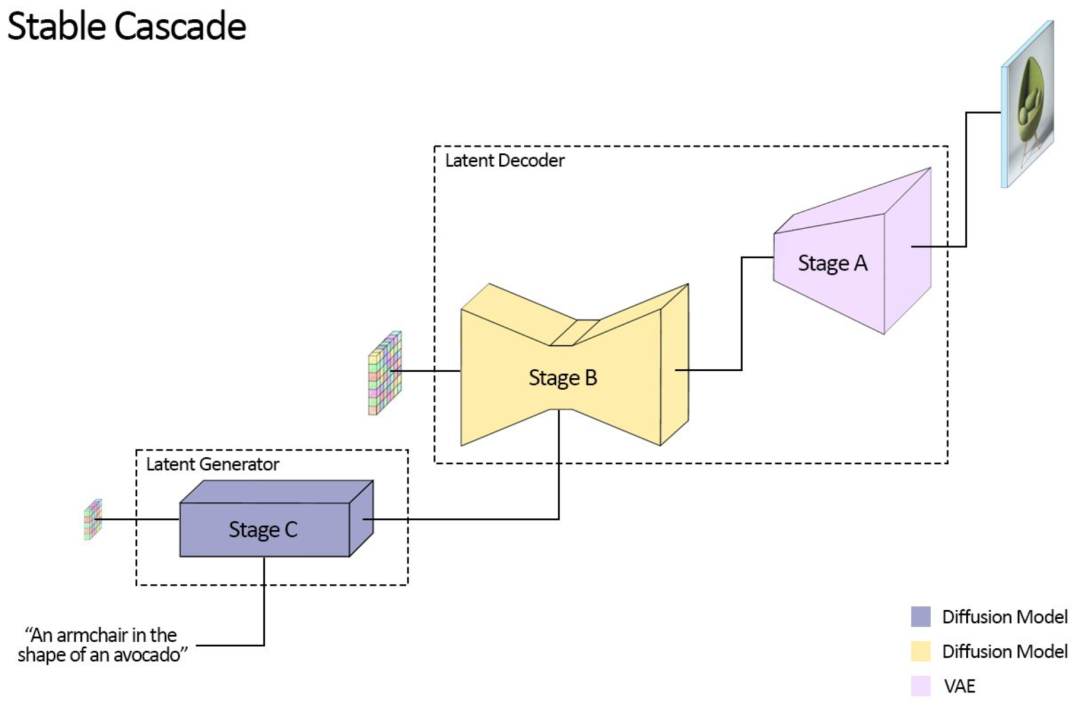
潜像生成器阶段(C 阶段)将用户输入转换为紧凑的 24x24 潜在表征,然后传递给潜在解码器阶段(阶段 A 和 B),用于压缩图像,这类似于 Stable Diffusion 中 VAE 的工作,但能够实现更高的压缩。
通过将文本条件生成(阶段 C)与解码到高分辨率像素空间(阶段 A 和 B)解耦,我们就可以在阶段 C 上完成额外的训练或微调,包括 ControlNets 和 LoRA,与训练类似大小的 Stable Diffusion 模型相比,这成本可以缩减至其的十六分之一。阶段 A 和 B 可以选择性地进行微调以实现额外的控制,但这将类似于微调 Stable Diffusion 模型中的 VAE。在大多数情况下,这样做的收益微乎其微。因此,对于大多数用途,Stability AI 官方建议仅训练阶段 C 并使用阶段 A 和 B 的原始状态。
阶段 C 和 B 将发布两种不同的模型:阶段 C 的 1B 和 3.6B 参数模型,阶段 B 的 700M 和 1.5B 参数模型。推荐使用 3.6B 参数的模型作为阶段 C,因为该模型具有最高质量的输出。不过,对于那希望有最低硬件要求的用户,可以使用 1B 参数版本。对于阶段 B,发布的两者都能取得很好的结果,但 1.5B 参数的版本在重建细节方面表现更佳。得益于 Stable Cascade 的模块化方法,推理所需的预期 VRAM 要求可以保持在约 20GB。这可通过使用较小的变体进一步降低,需要注意的是,这也可能会降低最终输出质量。
比较
在评估中,Stable Cascade 与几乎所有模型比较中在 prompt 对齐和美学质量方面表现最佳。下图显示了使用混合的 parti-prompts 和美学提示进行人类评估的结果:
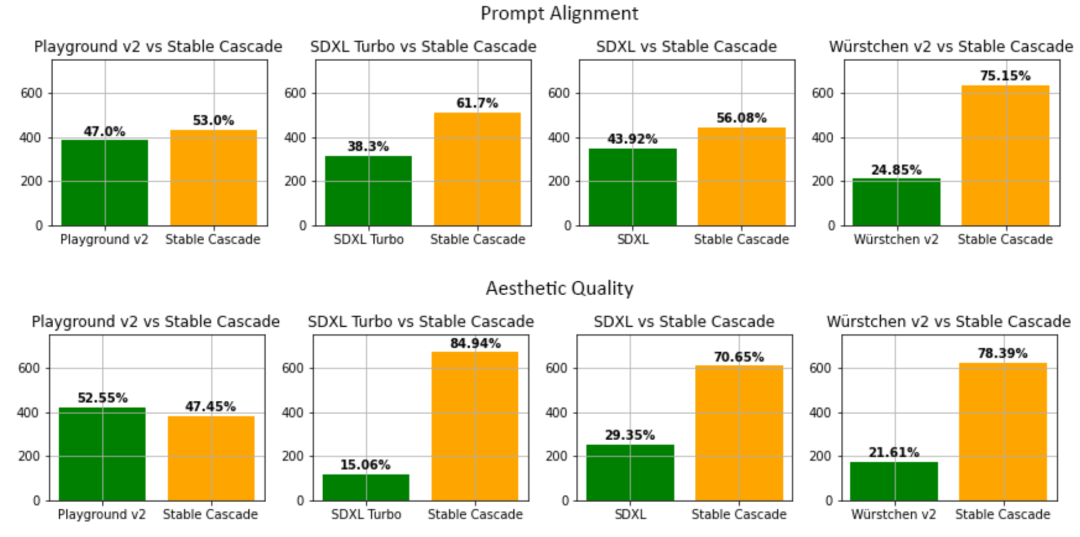
Stable Cascade(30 个推理步骤)与 Playground v2(50 个推理步骤)、SDXL(50 个推理步骤)、SDXL Turbo(1 个推理步骤)和 Würstchen v2(30 个推理步骤)进行了比较
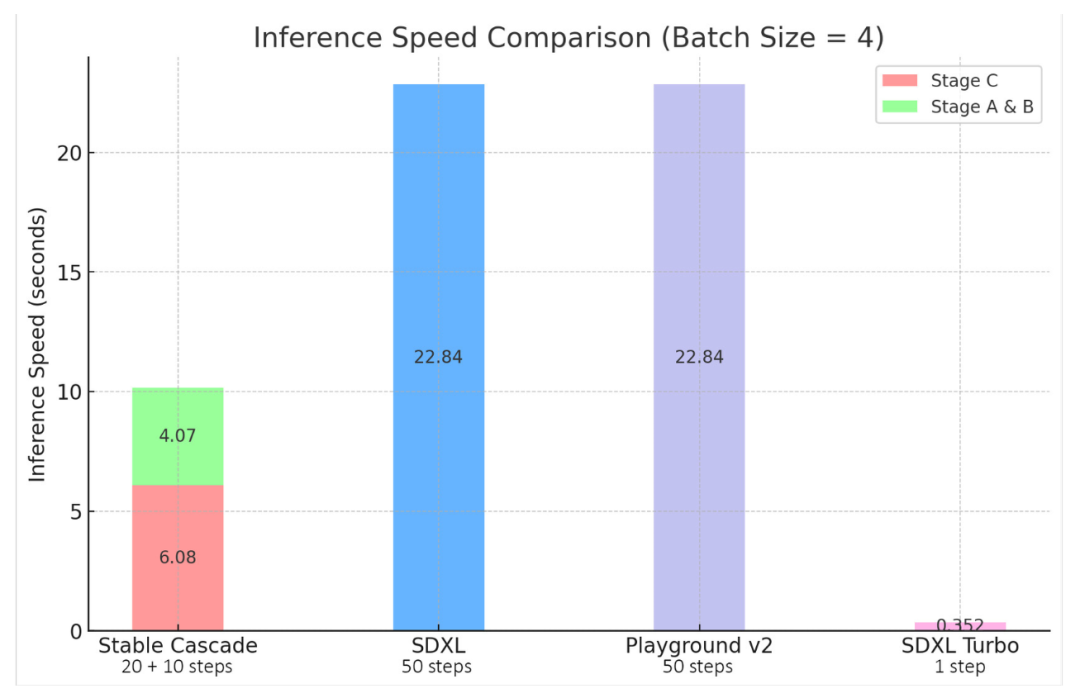
Stable Cascade、SDXL、Playground v2 和 SDXL Turbo 之间的推理速度差异
Stable Cascade 对效率的重视通过其架构和更高的压缩潜在空间得到了证明。尽管最大的模型比 Stable Diffusion XL 多出 1.4B 参数,但它仍然具有更快的推理时间。
附加功能
除了标准的文本到图像生成外,Stable Cascade 还可以生成图像变体和图像到图像的生成。
图像变体通过使用 CLIP 从给定图像中提取图像嵌入,然后将其返回给模型。下图是示例输出。左侧图像显示原始图像,而其右侧的四个是生成的变体。

图像到图像通过简单地向给定图像添加噪声,然后以此为起点生成图像。下面是对左侧图像添加噪声,然后以此为起点进行生成的示例。

训练、微调、ControlNet 和 LoRA 的代码
随着 Stable Cascade 的发布,Stability AI 将发布用于训练、微调、ControlNet 和 LoRA 的所有代码,以降低进一步试验此架构的要求。以下将与模型一起发布的一些 ControlNets:
修补 / 扩图:输入一张图片,并配上一个遮罩,以配合文字提示。然后,模型将根据提供的文本提示填充图像的遮罩部分。

Canny Edge:根据输入模型的现有图像的边缘生成新图像。根据 Stability AI 测试,它还可以扩展草图。

顶部为输入模型的草图,底部为输出结果
2 倍超分辨率:将图像的分辨率提升至其边长的 2 倍,例如将 1024 x 1024 的图像转化为 2048 x 2048 的输出,也可以用于由阶段 C 生成的潜在表示。

这样的性价比,你喜欢吗?
以上是生成速度快SDXL一倍,9GB GPU也能运行,Stable Cascade来搞性价比了的详细内容。更多信息请关注PHP中文网其他相关文章!