
Linux内存管理:如何实现虚拟内存和物理内存的转换和分配

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-02-10 17:24:261360浏览
在Linux系统中,内存管理是操作系统最重要的部分之一。它负责将有限的物理内存分配给多个进程,并提供虚拟内存的抽象,使得每个进程都有自己的地址空间,并能够保护和共享内存。本文将介绍Linux内存管理的原理和方法,包括虚拟内存、物理内存、逻辑内存、线性内存等概念,以及Linux内存管理的基本模型、系统调用、实现方式等。
本文以32位机器为准,串讲一些内存管理的知识点。
1. 虚拟地址、物理地址、逻辑地址、线性地址
虚拟地址又叫线性地址。linux没有采用分段机制,所以逻辑地址和虚拟地址(线性地址)(在用户态,内核态逻辑地址专指下文说的线性偏移前的地址)是一个概念。物理地址自不必提。内核的虚拟地址和物理地址,大部分只差一个线性偏移量。用户空间的虚拟地址和物理地址则采用了多级页表进行映射,但仍称之为线性地址。
2. DMA/HIGH_MEM/NROMAL 分区
在x86结构中,Linux内核虚拟地址空间划分0~3G为用户空间,3~4G为内核空间(注意,内核可以使用的线性地址只有1G)。内核虚拟空间(3G~4G)又划分为三种类型的区:
ZONE_DMA 3G之后起始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~1G
由于内核的虚拟和物理地址只差一个偏移量:物理地址 = 逻辑地址 – 0xC0000000。所以如果1G内核空间完全用来线性映射,显然物理内存也只能访问到1G区间,这显然是不合理的。HIGHMEM就是为了解决这个问题,专门开辟的一块不必线性映射,可以灵活定制映射,以便访问1G以上物理内存的区域。从网上扣来一图,
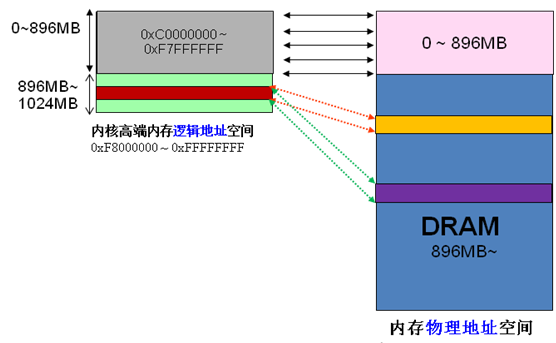
高端内存的划分,又如下图,
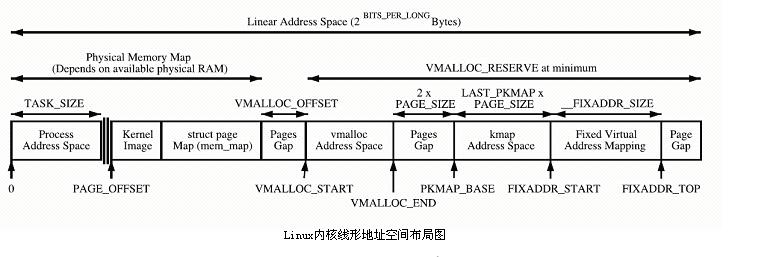
内核直接映射空间 PAGE_OFFSET~VMALLOC_START,kmalloc和__get_free_page()分配的是这里的页面。二者是借助slab分配器,直接分配物理页再转换为逻辑地址(物理地址连续)。适合分配小段内存。此区域 包含了内核镜像、物理页框表mem_map等资源。
内核动态映射空间 VMALLOC_START~VMALLOC_END,被vmalloc用到,可表示的空间大。
内核永久映射空间 PKMAP_BASE ~ FIXADDR_START,kmap
内核临时映射空间 FIXADDR_START~FIXADDR_TOP,kmap_atomic
3.伙伴算法和slab分配器
伙伴Buddy算法解决了外部碎片问题.内核在每个zone区管理着可用的页面,按2的幂级(order)大小排成链表队列,存放在free_area数组。
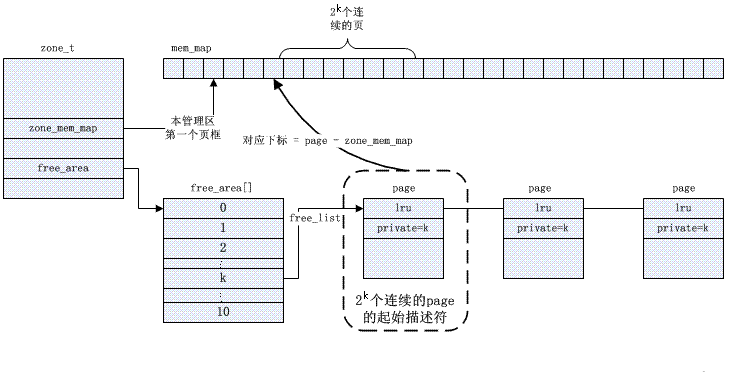
具体buddy管理基于位图,其分配回收页面的算法描述如下,
buddy算法举例描述:
假设我们的系统内存只有***16******个页面*****RAM*。因为RAM只有16个页面,我们只需用四个级别(orders)的伙伴位图(因为最大连续内存大小为******16******个页面***),如下图所示。
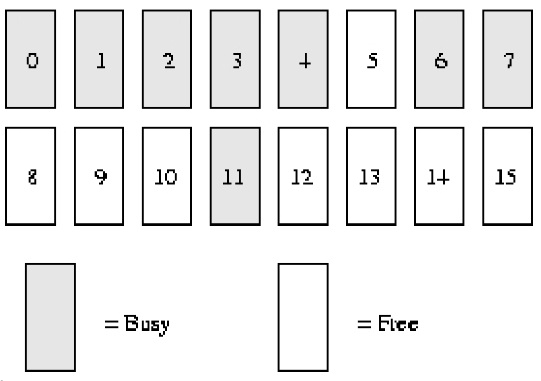

order(0)bimap有8个bit位(***页面最多******16******个页面,所以******16/2***)
order(1)bimap有4个bit位(***order******(******0******)******bimap******有******8******个******bit******位***,所以8/2);
也就是order(1)第一块由***两个页框****page1* ***与******page2*****组成与*order(1)第2块由两个页框****page3* ***与******page4******组成,这两个块之间有一个******bit****位*
order(2)bimap有2个bit位(***order******(******1******)******bimap******有******4******个******bit******位***,所以4/2)
order(3)bimap有1个bit位(***order******(******2******)******bimap******有******4******个******bit******位***,所以2/2)
在order(0),第一个bit表示开始***的******2******个页面***,第二个bit表示接下来的2个页面,以此类推。因为页面4已分配,而页面5空闲,故第三个bit为1。
同样在order(1)中,bit3是1的原因是一个伙伴完全空闲(页面8和9),和它对应的伙伴(页面10和11)却并非如此,故以后回收页面时,可以合并。
分配过程
***当我们需要******order******(******1******)的空闲页面块时,***则执行以下步骤:
1、初始空闲链表为:
order(0): 5, 10
order(1): 8 [8,9]
order(2): 12 [12,13,14,15]
order(3):
2、从上面空闲链表中,我们可以看出,order(1)链表上,有*一个空闲的页面块,把它分配给用户,并从该链表中删除。*
3、当我们再需要一个order(1)的块时,同样我们从order(1)空闲链表上开始扫描。
4、若在***order******(******1******)上没有空闲页面块***,那么我们就到更高的级别(order)上找,order(2)。
5、此时(***order******(******1*****)上没有空闲页面块*)有一个空闲页面块,该块是从页面12开始。该页面块被分割成两个稍微小一些order(1)的页面块,[12,13]和[14,15]。[14,15]页面块加到order******(******1*****)空闲链表中*,同时[12******,******13]****页面块返回给用户。*
6、最终空闲链表为:
order(0): 5, 10
order(1): 14 [14,15]
order(2):
order(3):
回收过程
***当我们回收页面******11******(******order 0****)时,则执行以下步骤:*
***1******、******找到在******order******(******0******)伙伴位图中代表页面******11******的位****,计算使用下面公示:*
*index =* *page_idx >> (order + 1)*
*= 11 >> (0 + 1)*
*= 5*
2、检查上面一步计算位图中相应bit的值。若该bit值为1,则和我们临近的,有一个空闲伙伴。Bit5的值为1(注意是从bit0开始的,Bit5即为第6bit),因为它的伙伴页面10是空闲的。
3、现在我们重新设置该bit的值为0,因为此时两个伙伴(页面10和页面11)完全空闲。
4、我们将页面10,从order(0)空闲链表中摘除。
5、此时,我们对2个空闲页面(页面10和11,order(1))进行进一步操作。
6、新的空闲页面是从页面10开始的,于是我们在order(1)的伙伴位图中找到它的索引,看是否有空闲的伙伴,以进一步进行合并操作。使用第一步中的计算公司,我们得到bit 2(第3位)。
7、Bit 2(order(1)位图)同样也是1,因为它的伙伴页面块(页面8和9)是空闲的。
8、重新设置bit2(order(1)位图)的值,然后在order(1)链表中删除该空闲页面块。
9、现在我们合并成了4页面大小(从页面8开始)的空闲块,从而进入另外的级别。在order(2)中找到伙伴位图对应的bit值,是bit1,且值为1,需进一步合并(原因同上)。
10、从oder(2)链表中摘除空闲页面块(从页面12开始),进而将该页面块和前面合并得到的页面块进一步合并。现在我们得到从页面8开始,大小为8个页面的空闲页面块。
11、我们进入另外一个级别,order(3)。它的位索引为0,它的值同样为0。这意味着对应的伙伴不是全部空闲的,所以没有再进一步合并的可能。我们仅设置该bit为1,然后将合并得到的空闲页面块放入order(3)空闲链表中。
12、最终我们得到大小为8个页面的空闲块,

buddy避免内部碎片的努力
物理内存的碎片化一直是Linux操作系统的弱点之一,尽管已经有人提出了很多解决方法,但是没有哪个方法能够彻底的解决,memory buddy分配就是解决方法之一。 我们知道磁盘文件也有碎片化问题,但是磁盘文件的碎片化只会减慢系统的读写速度,并不会导致功能性错误,而且我们还可以在不影响磁盘功能的前提的下,进行磁盘碎片整理。而物理内存碎片则截然不同,物理内存和操作系统结合的太过于紧密,以至于我们很难在运行时,进行物理内存的搬移(这一点上,磁盘碎片要容易的多;实际上mel gorman已经提交了内存紧缩的patch,只是还没有被主线内核接收)。 因此解决的方向主要放在预防碎片上。在2.6.24内核开发期间,防止碎片的内核功能加入了主线内核。在了解反碎片的基本原理前,先对内存页面做个归类:
1. 不可移动页面 unmoveable:在内存中位置必须固定,无法移动到其他地方,核心内核分配的大部分页面都属于这一类。
2. 可回收页面 reclaimable:不能直接移动,但是可以回收,因为还可以从某些源重建页面,比如映射文件的数据属于这种类别,kswapd会按照一定的规则,周期性的回收这类页面。
3. 可移动页面 movable:可以随意的移动。属于用户空间应用程序的页属于此类页面,它们是通过页表映射的,因此我们只需要更新页表项,并把数据复制到新位置就可以了,当然要注意,一个页面可能被多个进程共享,对应着多个页表项。
防止碎片的方法就是把这三类page放在不同的链表上,避免不同类型页面相互干扰。考虑这样的情形,一个不可移动的页面位于可移动页面中间,那么我们移动或者回收这些页面后,这个不可移动的页面阻碍着我们获得更大的连续物理空闲空间。
另外,每个zone区都有一个自己的失活净页面队列,与此对应的是两个跨zone的全局队列,失活脏页队列 和 活跃队列。这些队列都是通过page结构的lru指针链入的。
思考:失活队列的意义是什么(见
slab分配器:解决内部碎片问题
内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab 缓存分配器通过对类似大小(远小于1page)的对象进行缓存而提供这种功能,从而避免了常见的内部碎片问题。此处暂贴一图,关于其原理,常见参考文献3。很显然,slab机制是基于buddy算法的,前者是对后者的细化。
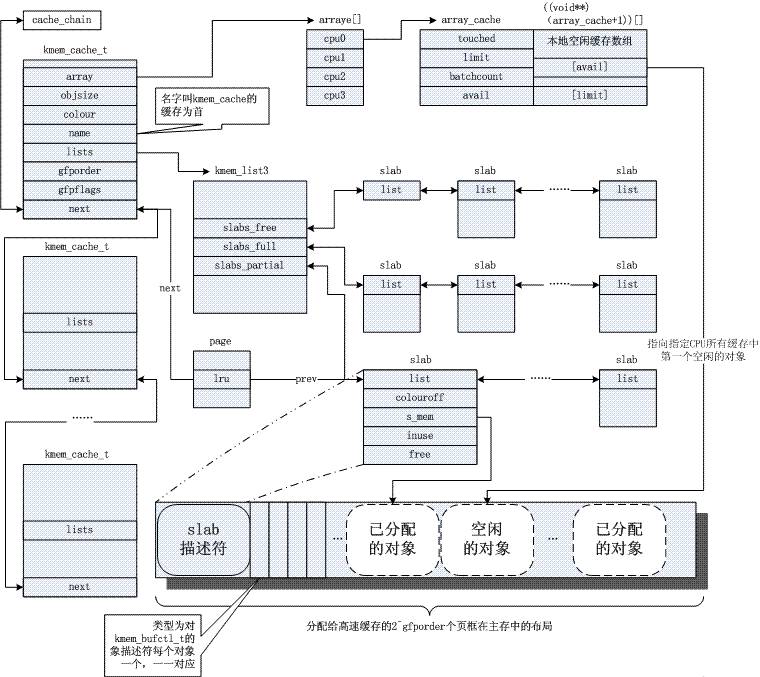
4.页面回收/侧重机制
关于页面的使用
在之前的一些文章中,我们了解到linux内核会在很多情况下分配页面。
1、内核代码可能调用alloc_pages之类的函数,从管理物理页面的伙伴系统(管理区zone上的free_area空闲链表)上直接分配页面(见《linux内核内存管理浅析》)。比如:驱动程序可能用这种方式来分配缓存;创建进程时,内核也是通过这种方式分配连续的两个页面,作为进程的thread_info结构和内核栈;等等。从伙伴系统分配页面是最基本的页面分配方式,其他的内存分配都是基于这种方式的;
2、内核中的很多对象都是用slab机制来管理的(见《linux slub分配器浅析》)。slab就相当于对象池,它将页面“格式化”成“对象”,存放在池中供人使用。当slab中的对象不足时,slab机制会自动从伙伴系统中分配页面,并“格式化”成新的对象;
3、磁盘高速缓存(见《linux内核文件读写浅析》)。读写文件时,页面被从伙伴系统分配并用于磁盘高速缓存,然后磁盘上的文件数据被载入到对应的磁盘高速缓存页面中;
4、内存映射。这里所谓的内存映射实际上是指将内存页面映射到用户空间,供用户进程使用。进程的task_struct->mm结构中的每一个vma就代表着一个映射,而映射的真正实现则是在用户程序访问到对应的内存地址之后,由缺页异常引起的页面被分配和页表被更新(见《linux内核内存管理浅析》);
页面回收简述
有页面分配,就会有页面回收。页面回收的方法大体上可分为两种:
一是主动释放。就像用户程序通过free函数释放曾经通过malloc函数分配的内存一样,页面的使用者明确知道页面什么时候要被使用,什么时候又不再需要了。
上面提到的前两种分配方式,一般都是由内核程序主动释放的。对于直接从伙伴系统分配的页面,这是由使用者使用free_pages之类的函数主动释放的,页面释放后被直接放归伙伴系统;从slab中分配的对象(使用kmem_cache_alloc函数),也是由使用者主动释放的(使用kmem_cache_free函数)。
另一种页面回收方式是通过linux内核提供的页框回收算法(PFRA)进行回收。页面的使用者一般将页面当作某种缓存,以提高系统的运行效率。缓存一直存在固然好,但是如果缓存没有了也不会造成什么错误,仅仅是效率受影响而已。页面的使用者不明确知道这些缓存页面什么时候最好被保留,什么时候最好被回收,这些都交由PFRA来关心。
简单来说,PFRA要做的事就是回收这些可以被回收的页面。为了避免系统陷入页面紧缺的困境,PFRA会在内核线程中周期性地被调用运行。或者由于系统已经页面紧缺,试图分配页面的内核执行流程因为得不到需要的页面,而同步地调用PFRA。
上面提到的后两种分配方式,一般是由PFRA来进行回收的(或者由类似删除文件、进程退出、这样的过程来同步回收)。
PFRA回收一般页面
而对于上面提到的前两种页面分配方式(直接分配页面和通过slab分配对象),也有可能需要通过PFRA来回收。
页面的使用者可以向PFRA注册回调函数(使用register_shrink函数)。然后由PFRA在适当的时机来调用这些回调函数,以触发对相应页面或对象的回收。
其中较为典型的是对dentry的回收。dentry是由slab分配的,用于表示虚拟文件系统目录结构的对象。在dentry的引用记数被减为0的时候,dentry并不是直接被释放,而是被放到一个LRU链表中缓存起来,便于后续的使用。(见《linux内核虚拟文件系统浅析》。)
而这个LRU链表中的dentry最终是需要被回收的,于是虚拟文件系统在初始化时,调用register_shrinker注册了回收函数shrink_dcache_memory。
系统中所有文件系统的超级块对象被存放在一个链表中,shrink_dcache_memory函数扫描这个链表,获取每个超级块的未被使用dentry的LRU,然后从中回收一些最老的dentry。随着dentry的释放,对应的inode将被减引用,也可能引起inode被释放。
inode被释放后也是放在一个未使用链表中,虚拟文件系统在初始化时还调用register_shrinker注册了回调函数shrink_icache_memory,用来回收这些未使用的inode,从而inode中关联的磁盘高速缓存也将被释放。
另外,随着系统的运行,slab中可能会存在很多的空闲对象(比如在对某一对象的使用高峰过后)。PFRA中的cache_reap函数就用于回收这些多余的空闲对象,如果某些空闲的对象正好能够还原成一个页面,则这个页面可以被释放回伙伴系统;
cache_reap函数要做的事情说起来很简单。系统中所有存放对象池的kmem_cache结构连成一个链表,cache_reap函数扫描其中的每一个对象池,然后寻找可以回收的页面,并将其回收。(当然,实际的过程要更复杂一点。)
关于内存映射
前面说到,磁盘高速缓存和内存映射一般由PFRA来进行回收。PFRA对这两者的回收是很类似的,实际上,磁盘高速缓存很可能就被映射到了用户空间。下面简单对内存映射做一些介绍:
内存映射分为文件映射和匿名映射。
文件映射是指代表这个映射的vma对应到一个文件中的某个区域。这种映射方式相对较少被用户态程序显式地使用,用户态程序一般习惯于open一个文件、然后read/write去读写文件。
而实际上,用户程序也可以使用mmap系统调用将一个文件的某个部分映射到内存上(对应到一个vma),然后以访存的方式去读写文件。尽管用户程序较少这样使用,但是用户进程中却充斥着这样的映射:进程正在执行的可执行代码(包括可执行文件、lib库文件)就是以这样的方式被映射的。
在《linux内核文件读写浅析》一文中,我们并没有讨论关于文件映射的实现。实际上,文件映射是将文件的磁盘高速缓存中的页面直接映射到了用户空间(可见,文件映射的页面是磁盘高速缓存页面的子集),用户可以0拷贝地对其进行读写。而使用read/write的话,则会在用户空间的内存和磁盘高速缓存间发生一次拷贝。
匿名映射相对于文件映射,代表这个映射的vma没有对应到文件。对于用户空间普通的内存分配(堆空间、栈空间),都属于匿名映射。
显然,多个进程可能通过各自的文件映射来映射到同一个文件上(比如大多数进程都映射了libc库的so文件);那匿名映射呢?实际上,多个进程也可能通过各自的匿名映射来映射到同一段物理内存上,这种情况是由于fork之后父子进程共享原来的物理内存(copy-on-write)而引起的。
文件映射又分为共享映射和私有映射。私有映射时,如果进程对映射的地址空间进行写操作,则映射对应的磁盘高速缓存并不会直接被写。而是将原有内容复制一份,然后再写这个复制品,并且当前进程的对应页面映射将切换到这个复制品上去(写时复制)。也就是说,写操作是只有自己可见的。而对于共享映射,写操作则会影响到磁盘高速缓存,是大家都可见的。
哪些页面****该回收
至于回收,磁盘高速缓存的页面(包括文件映射的页面)都是可以被丢弃并回收的。但是如果页面是脏页面,则丢弃之前必须将其写回磁盘。
而匿名映射的页面则都是不可以丢弃的,因为页面里面存有用户程序正在使用的数据,丢弃之后数据就没法还原了。相比之下,磁盘高速缓存页面中的数据本身是保存在磁盘上的,可以复现。
于是,要想回收匿名映射的页面,只好先把页面上的数据转储到磁盘,这就是页面交换(swap)。显然,页面交换的代价相对更高一些。
匿名映射的页面可以被交换到磁盘上的交换文件或交换分区上(分区即是设备,设备即也是文件。所以下文统称为交换文件)。
于是,除非页面被保留或被上锁(页面标记PG_reserved/PG_locked被置位。某些情况下,内核需要暂时性地将页面保留,避免被回收),所有的磁盘高速缓存页面都可回收,所有的匿名映射页面都可交换。
尽管可以回收的页面很多,但是显然PFRA应当尽可能少地去回收/交换(因为这些页面要从磁盘恢复,需要很大的代价)。所以,PFRA仅当必要时才回收/交换一部分很少被使用的页面,每次回收的页面数是一个经验值:32。
于是,所有这些磁盘高速缓存页面和匿名映射页面都被放到了一组LRU里面。(实际上,每个zone就有一组这样的LRU,页面都被放到自己对应的zone的LRU中。)
一组LRU由几对链表组成,有磁盘高速缓存页面(包括文件映射页面)的链表、匿名映射页面的链表、等。一对链表实际上是active和inactive两个链表,前者是最近使用过的页面、后者是最近未使用的页面。
进行页面回收的时候,PFRA要做两件事情,一是将active链表中最近最少使用的页面移动到inactive链表、二是尝试将inactive链表中最近最少使用的页面回收。
确定最近最少使用
现在就有一个问题了,怎么确定active/inactive链表中哪些页面是最近最少使用的呢?
一种方法是排序,当页面被访问时,将其移动到链表的尾部(假设回收从头部开始)。但是这就意味着页面在链表中的位置可能频繁移动,并且移动之前还必须先上锁(可能有多个CPU在同时访问),这样做对效率影响很大。
linux内核采用的是标记加顺序的办法。当页面在active和inactive两个链表之间移动时,总是将其放到链表的尾部(同上,假设回收从头部开始)。
页面没有在链表间移动时,并不会调整它们的顺序。而是通过访问标记来表示页面是否刚被访问过。如果inactive链表中已设置访问标记的页面再被访问,则将其移动到active链表中,并且清除访问标记。(实际上,为了避免访问冲突,页面并不会直接从inactive链表移动到active链表,而是有一个pagevec中间结构用作缓冲,以避免锁链表。)
页面的访问标记有两种情况,一是放在page->flags中的PG_referenced标记,在页面被访问时该标记置位。对于磁盘高速缓存中(未被映射)的页面,用户进程通过read、write之类的系统调用去访问它们,系统调用代码中会将对应页面的PG_referenced标记置位。
而对于内存映射的页面,用户进程可以直接访问它们(不经过内核),所以这种情况下的访问标记不是由内核来设置的,而是由mmu。在将虚拟地址映射成物理地址后,mmu会在对应的页表项上置一个accessed标志位,表示页面被访问。(同样的道理,mmu会在被写的页面所对应的页表项上置一个dirty标志,表示页面是脏页面。)
页面的访问标记(包括上面两种标记)将在PFRA处理页面回收的过程中被清除,因为访问标记显然是应该有有效期的,而PFRA的运行周期就代表这个有效期。page->flags中的PG_referenced标记可以直接清除,而页表项中的accessed位则需要通过页面找到其对应的页表项后才能清除(见下文的“反向映射”)。
那么,回收过程又是怎样扫描LRU链表的呢?
由于存在多组LRU(系统中有多个zone,每个zone又有多组LRU),如果PFRA每次回收都扫描所有的LRU找出其中最值得回收的若干个页面的话,回收算法的效率显然不够理想。
linux内核PFRA使用的扫描方法是:定义一个扫描优先级,通过这个优先级换算出在每个LRU上应该扫描的页面数。整个回收算法以最低的优先级开始,先扫描每个LRU中最近最少使用的几个页面,然后试图回收它们。如果一遍扫描下来,已经回收了足够数量的页面,则本次回收过程结束。否则,增大优先级,再重新扫描,直到足够数量的页面被回收。而如果始终不能回收足够数量的页面,则优先级将增加到最大,也就是所有页面将被扫描。这时,就算回收的页面数量还是不足,回收过程都会结束。
每次扫描一个LRU时,都从active链表和inactive链表获取当前优先级对应数目的页面,然后再对这些页面做处理:如果页面不能被回收(如被保留或被上锁),则放回对应链表头部(同上,假设回收从头部开始);否则如果页面的访问标记置位,则清除该标记,并将页面放回对应链表尾部(同上,假设回收从头部开始);否则页面将从active链表被移动到inactive链表、或从inactive链表被回收。
被扫描到的页面根据访问标记是否置位来决定其去留。那么这个访问标记是如何设置的呢?有两个途径,一是用户通过read/write之类的系统调用访问文件时,内核操作磁盘高速缓存中的页面,会设置这些页面的访问标记(设置在page结构中);二是进程直接访问已映射的页面时,mmu会自动给对应的页表项加上访问标记(设置在页表的pte中)。关于访问标记的判断就基于这两个信息。(给定一个页面,可能有多个pte引用到它。如何知道这些pte是否被设置了访问标记呢?那就需要通过反向映射找到这些pte。下面会讲到。)
PFRA不倾向于从active链表回收匿名映射的页面,因为用户进程使用的内存一般相对较少,且回收的话需要进行交换,代价较大。所以在内存剩余较多、匿名映射所占比例较少的情况下,都不会去回收匿名映射对应的active链表中的页面。(而如果页面已经被放到inactive链表中,就不再去管那么多了。)
反向映射
像这样,在PFRA处理页面回收的过程中,LRU的inactive链表中的某些页面可能就要被回收了。
如果页面没有被映射,直接回收到伙伴系统即可(对于脏页,先写回、再回收)。否则,还有一件麻烦的事情要处理。因为用户进程的某个页表项正引用着这个页面呢,在回收页面之前,还必须给引用它的页表项一个交待。
于是,问题就来了,内核怎么知道这个页面被哪些页表项所引用呢?为了做到这一点,内核建立了从页面到页表项的反向映射。
通过反向映射可以找到一个被映射的页面对应的vma,通过vma->vm_mm->pgd就能找到对应的页表。然后通过page->index得到页面的虚拟地址。再通过虚拟地址从页表中找到对应的页表项。(前面说到的获取页表项中的accessed标记,就是通过反向映射实现的。)
页面对应的page结构中,page->mapping如果最低位置位,则这是一个匿名映射页面,page->mapping指向一个anon_vma结构;否则是文件映射页面,page->mapping文件对应的address_space结构。(显然,anon_vma结构和address_space结构在分配时,地址必须要对齐,至少保证最低位为0。)
对于匿名映射的页面,anon_vma结构作为一个链表头,将映射这个页面的所有vma通过vma->anon_vma_node链表指针连接起来。每当一个页面被(匿名)映射到一个用户空间时,对应的vma就被加入这个链表。
对于文件映射的页面,address_space结构除了维护了一棵用于存放磁盘高速缓存页面的radix树,还为该文件映射到的所有vma维护了一棵优先搜索树。因为这些被文件映射到的vma并不一定都是映射整个文件,很可能只映射了文件的一部分。所以,这棵优先搜索树除了索引到所有被映射的vma,还要能知道文件的哪些区域是映射到哪些vma上的。每当一个页面被(文件)映射到一个用户空间时,对应的vma就被加入这个优先搜索树。于是,给定磁盘高速缓存上的一个页面,就能通过page->index得到页面在文件中的位置,就能通过优先搜索树找出这个页面映射到的所有vma。
上面两步中,神奇的page->index做了两件事,得到页面的虚拟地址、得到页面在文件磁盘高速缓存中的位置。
vma->vm_start记录了vma的首虚拟地址,vma->vm_pgoff记录了该vma在对应的映射文件(或共享内存)中的偏移,而page->index记录了页面在文件(或共享内存)中的偏移。
通过vma->vm_pgoff和page->index能得到页面在vma中的偏移,加上vma->vm_start就能得到页面的虚拟地址;而通过page->index就能得到页面在文件磁盘高速缓存中的位置。
页面换入换出
在找到了引用待回收页面的页表项后,对于文件映射,可以直接把引用该页面的页表项清空。等用户再访问这个地址的时候触发缺页异常,异常处理代码再重新分配一个页面,并去磁盘里面把对应的数据读出来就行了(说不定,页面在对应的磁盘高速缓存里面已经有了,因为其他进程先访问过)。这就跟页面映射以后,第一次被访问的情形一样;
对于匿名映射,先将页面写回到交换文件,然后还得在页表项中记录该页面在交换文件中的index。
页表项中有一个present位,如果该位被清除,则mmu认为页表项无效。在页表项无效的情况下,其他位不被mmu关心,可以用来存储其他信息。这里就用它们来存储页面在交换文件中的index了(实际上是交换文件号+交换文件内的索引号)。
将匿名映射的页面交换到交换文件的过程(换出过程)与将磁盘高速缓存中的脏页写回文件的过程很相似。
交换文件也有其对应的address_space结构,匿名映射的页面在换出时先被放到这个address_space对应磁盘高速缓存中,然后跟脏页写回一样,被写回到交换文件中。写回完成后,这个页面才被释放(记住,我们的目的是要释放这个页面)。
那么为什么不直接把页面写回到交换文件,而要经过磁盘高速缓存呢?因为,这个页面可能被映射了多次,不可能一次性把所有用户进程的页表中对应的页表项都修改好(修改成页面在交换文件中的索引),所以在页面被释放的过程中,页面被暂时放在磁盘高速缓存上。
而并不是所有页表项的修改过程都是能成功的(比如在修改之前页面又被访问了,于是现在又不需要回收这个页面了),所以页面放到磁盘高速缓存的时间也可能会很长。
同样,将匿名映射的页面从交换文件读出的过程(换入过程)也与将文件数据读出的过程很相似。
先去对应的磁盘高速缓存上看看页面在不在,不在的话再去交换文件里面读。文件里的数据也是被读到磁盘高速缓存中的,然后用户进程的页表中对应的页表项将被改写,直接指向这个页面。
这个页面可能不会马上从磁盘高速缓存中拿下来,因为如果还有其他用户进程也映射到这个页面(它们的对应页表项已经被修改成了交换文件的索引),他们也可以引用到这里。直到没有其他的页表项再引用这个交换文件索引时,页面才可以从磁盘高速缓存中被取下来。
最后的必杀
前面说到,PFRA可能扫描了所有的LRU还没办法回收需要的页面。同样,在slab、dentry cache、inode cache、等地方,可能也无法回收到页面。
这时,如果某段内核代码一定要获得页面呢(没有页面,系统可能就要崩溃了)?PFRA只好使出最后的必杀技——OOM(out of memory)。所谓的OOM就是寻找一个最不重要的进程,然后将其杀死。通过释放这个进程所占有的内存页面,以缓解系统压力。
5.内存管理架构
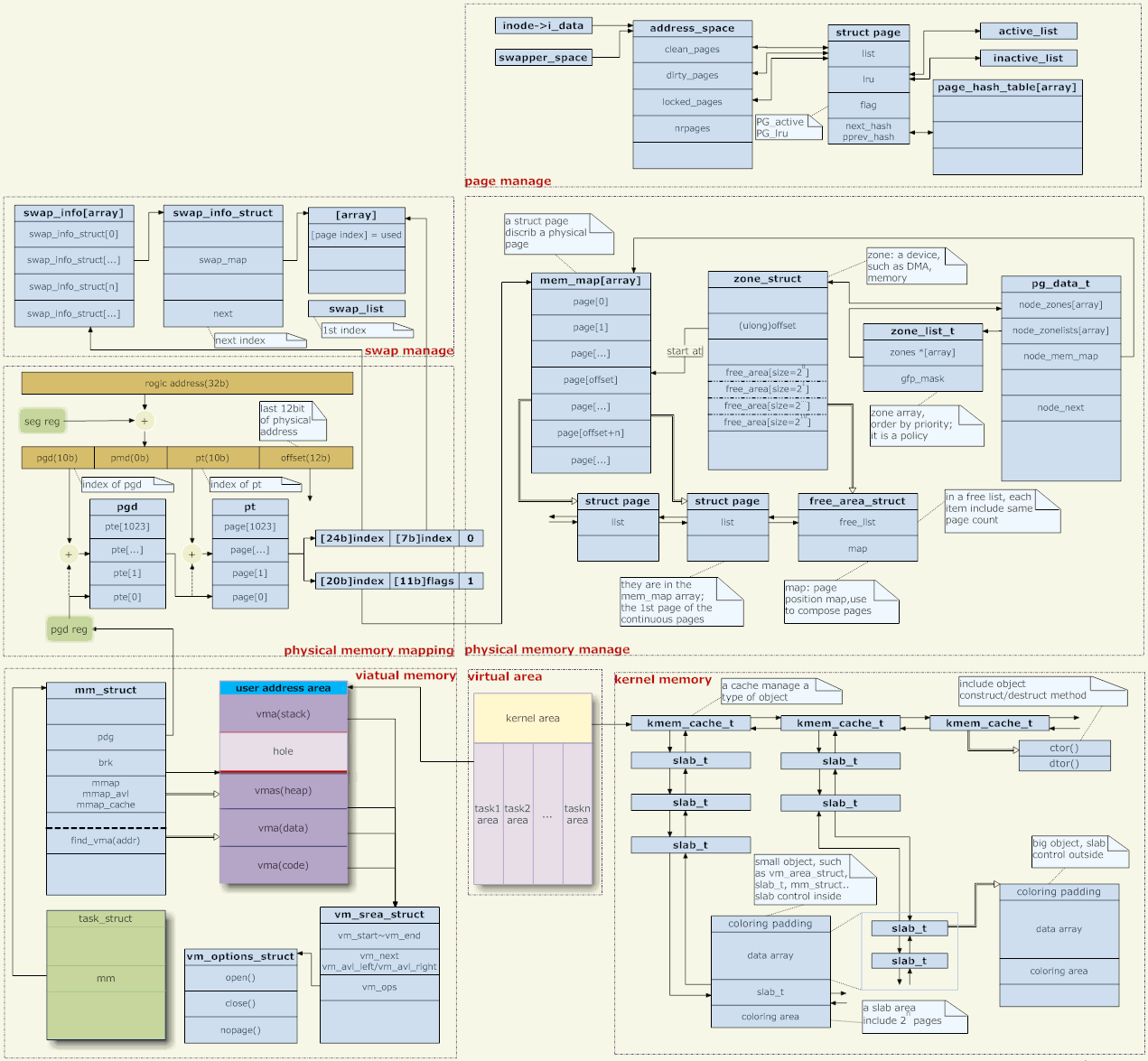
针对上图,说几句,
地址映射
linux内核使用页式内存管理,应用程序给出的内存地址是虚拟地址,它需要经过若干级页表一级一级的变换,才变成真正的物理地址。
想一下,地址映射还是一件很恐怖的事情。当访问一个由虚拟地址表示的内存空间时,需要先经过若干次的内存访问,得到每一级页表中用于转换的页表项(页表是存放在内存里面的),才能完成映射。也就是说,要实现一次内存访问,实际上内存被访问了N+1次(N=页表级数),并且还需要做N次加法运算。
所以,地址映射必须要有硬件支持,mmu(内存管理单元)就是这个硬件。并且需要有cache来保存页表,这个cache就是TLB(Translation lookaside buffer)。
尽管如此,地址映射还是有着不小的开销。假设cache的访存速度是内存的10倍,命中率是40%,页表有三级,那么平均一次虚拟地址访问大概就消耗了两次物理内存访问的时间。
于是,一些嵌入式硬件上可能会放弃使用mmu,这样的硬件能够运行VxWorks(一个很高效的嵌入式实时操作系统)、linux(linux也有禁用mmu的编译选项)、等系统。
但是使用mmu的优势也是很大的,最主要的是出于安全性考虑。各个进程都是相互独立的虚拟地址空间,互不干扰。而放弃地址映射之后,所有程序将运行在同一个地址空间。于是,在没有mmu的机器上,一个进程越界访存,可能引起其他进程莫名其妙的错误,甚至导致内核崩溃。
在地址映射这个问题上,内核只提供页表,实际的转换是由硬件去完成的。那么内核如何生成这些页表呢?这就有两方面的内容,虚拟地址空间的管理和物理内存的管理。(实际上只有用户态的地址映射才需要管理,内核态的地址映射是写死的。)
虚拟地址管理
每个进程对应一个task结构,它指向一个mm结构,这就是该进程的内存管理器。(对于线程来说,每个线程也都有一个task结构,但是它们都指向同一个mm,所以地址空间是共享的。)
mm->pgd指向容纳页表的内存,每个进程有自已的mm,每个mm有自己的页表。于是,进程调度时,页表被切换(一般会有一个CPU寄存器来保存页表的地址,比如X86下的CR3,页表切换就是改变该寄存器的值)。所以,各个进程的地址空间互不影响(因为页表都不一样了,当然无法访问到别人的地址空间上。但是共享内存除外,这是故意让不同的页表能够访问到相同的物理地址上)。
用户程序对内存的操作(分配、回收、映射、等)都是对mm的操作,具体来说是对mm上的vma(虚拟内存空间)的操作。这些vma代表着进程空间的各个区域,比如堆、栈、代码区、数据区、各种映射区、等等。
用户程序对内存的操作并不会直接影响到页表,更不会直接影响到物理内存的分配。比如malloc成功,仅仅是改变了某个vma,页表不会变,物理内存的分配也不会变。
假设用户分配了内存,然后访问这块内存。由于页表里面并没有记录相关的映射,CPU产生一次缺页异常。内核捕捉异常,检查产生异常的地址是不是存在于一个合法的vma中。如果不是,则给进程一个”段错误”,让其崩溃;如果是,则分配一个物理页,并为之建立映射。
物理内存管理
那么物理内存是如何分配的呢?
首先,linux支持NUMA(非均质存储结构),物理内存管理的第一个层次就是介质的管理。pg_data_t结构就描述了介质。一般而言,我们的内存管理介质只有内存,并且它是均匀的,所以可以简单地认为系统中只有一个pg_data_t对象。
每一种介质下面有若干个zone。一般是三个,DMA、NORMAL和HIGH。
DMA:因为有些硬件系统的DMA总线比系统总线窄,所以只有一部分地址空间能够用作DMA,这部分地址被管理在DMA区域(这属于是高级货了);
HIGH:高端内存。在32位系统中,地址空间是4G,其中内核规定3~4G的范围是内核空间,0~3G是用户空间(每个用户进程都有这么大的虚拟空间)(图:中下)。前面提到过内核的地址映射是写死的,就是指这3~4G的对应的页表是写死的,它映射到了物理地址的0~1G上。(实际上没有映射1G,只映射了896M。剩下的空间留下来映射大于1G的物理地址,而这一部分显然不是写死的)。所以,大于896M的物理地址是没有写死的页表来对应的,内核不能直接访问它们(必须要建立映射),称它们为高端内存(当然,如果机器内存不足896M,就不存在高端内存。如果是64位机器,也不存在高端内存,因为地址空间很大很大,属于内核的空间也不止1G了);
NORMAL:不属于DMA或HIGH的内存就叫NORMAL。
在zone之上的zone_list代表了分配策略,即内存分配时的zone优先级。一种内存分配往往不是只能在一个zone里进行分配的,比如分配一个页给内核使用时,最优先是从NORMAL里面分配,不行的话就分配DMA里面的好了(HIGH就不行,因为还没建立映射),这就是一种分配策略。
每个内存介质维护了一个mem_map,为介质中的每一个物理页面建立了一个page结构与之对应,以便管理物理内存。
每个zone记录着它在mem_map上的起始位置。并且通过free_area串连着这个zone上空闲的page。物理内存的分配就是从这里来的,从 free_area上把page摘下,就算是分配了。(内核的内存分配与用户进程不同,用户使用内存会被内核监督,使用不当就”段错误”;而内核则无人监督,只能靠自觉,不是自己从free_area摘下的page就不要乱用。)
[建立地址映射]
内核需要物理内存时,很多情况是整页分配的,这在上面的mem_map中摘一个page下来就好了。比如前面说到的内核捕捉缺页异常,然后需要分配一个page以建立映射。
说到这里,会有一个疑问,内核在分配page、建立地址映射的过程中,使用的是虚拟地址还是物理地址呢?首先,内核代码所访问的地址都是虚拟地址,因为CPU指令接收的就是虚拟地址(地址映射对于CPU指令是透明的)。但是,建立地址映射时,内核在页表里面填写的内容却是物理地址,因为地址映射的目标就是要得到物理地址。
那么,内核怎么得到这个物理地址呢?其实,上面也提到了,mem_map中的page就是根据物理内存来建立的,每一个page就对应了一个物理页。
于是我们可以说,虚拟地址的映射是靠这里page结构来完成的,是它们给出了最终的物理地址。然而,page结构显然是通过虚拟地址来管理的(前面已经说过,CPU指令接收的就是虚拟地址)。那么,page结构实现了别人的虚拟地址映射,谁又来实现page结构自己的虚拟地址映射呢?没人能够实现。
这就引出了前面提到的一个问题,内核空间的页表项是写死的。在内核初始化时,内核的地址空间就已经把地址映射写死了。page结构显然存在于内核空间,所以它的地址映射问题已经通过“写死”解决了。
由于内核空间的页表项是写死的,又引出另一个问题,NORMAL(或DMA)区域的内存可能被同时映射到内核空间和用户空间。被映射到内核空间是显然的,因为这个映射已经写死了。而这些页面也可能被映射到用户空间的,在前面提到的缺页异常的场景里面就有这样的可能。映射到用户空间的页面应该优先从HIGH区域获取,因为这些内存被内核访问起来很不方便,拿给用户空间再合适不过了。但是HIGH区域可能会耗尽,或者可能因为设备上物理内存不足导致系统里面根本就没有HIGH区域,所以,将NORMAL区域映射给用户空间是必然存在的。
但是NORMAL区域的内存被同时映射到内核空间和用户空间并没有问题,因为如果某个页面正在被内核使用,对应的page应该已经从free_area被摘下,于是缺页异常处理代码中不会再将该页映射到用户空间。反过来也一样,被映射到用户空间的page自然已经从free_area被摘下,内核不会再去使用这个页面。
内核空间管理
除了对内存整页的使用,有些时候,内核也需要像用户程序使用malloc一样,分配一块任意大小的空间。这个功能是由slab系统来实现的。
slab相当于为内核中常用的一些结构体对象建立了对象池,比如对应task结构的池、对应mm结构的池、等等。
而slab也维护有通用的对象池,比如”32字节大小”的对象池、”64字节大小”的对象池、等等。内核中常用的kmalloc函数(类似于用户态的malloc)就是在这些通用的对象池中实现分配的。
slab除了对象实际使用的内存空间外,还有其对应的控制结构。有两种组织方式,如果对象较大,则控制结构使用专门的页面来保存;如果对象较小,控制结构与对象空间使用相同的页面。
除了slab,linux 2.6还引入了mempool(内存池)。其意图是:某些对象我们不希望它会因为内存不足而分配失败,于是我们预先分配若干个,放在mempool中存起来。正常情况下,分配对象时是不会去动mempool里面的资源的,照常通过slab去分配。到系统内存紧缺,已经无法通过slab分配内存时,才会使用 mempool中的内容。
页面换入换出(图:右上)
页面换入换出又是一个很复杂的系统。内存页面被换出到磁盘,与磁盘文件被映射到内存,是很相似的两个过程(内存页被换出到磁盘的动机,就是今后还要从磁盘将其载回内存)。所以swap复用了文件子系统的一些机制。
页面换入换出是一件很费CPU和IO的事情,但是由于内存昂贵这一历史原因,我们只好拿磁盘来扩展内存。但是现在内存越来越便宜了,我们可以轻松安装数G的内存,然后将swap系统关闭。于是swap的实现实在让人难有探索的欲望,在这里就不赘述了。(另见:《linux内核页面回收浅析》)
[用户空间内存管理]
malloc是libc的库函数,用户程序一般通过它(或类似函数)来分配内存空间。
libc对内存的分配有两种途径,一是调整堆的大小,二是mmap一个新的虚拟内存区域(堆也是一个vma)。
在内核中,堆是一个一端固定、一端可伸缩的vma(图:左中)。可伸缩的一端通过系统调用brk来调整。libc管理着堆的空间,用户调用malloc分配内存时,libc尽量从现有的堆中去分配。如果堆空间不够,则通过brk增大堆空间。
当用户将已分配的空间free时,libc可能会通过brk减小堆空间。但是堆空间增大容易减小却难,考虑这样一种情况,用户空间连续分配了10块内存,前9块已经free。这时,未free的第10块哪怕只有1字节大,libc也不能够去减小堆的大小。因为堆只有一端可伸缩,并且中间不能掏空。而第10块内存就死死地占据着堆可伸缩的那一端,堆的大小没法减小,相关资源也没法归还内核。
当用户malloc一块很大的内存时,libc会通过mmap系统调用映射一个新的vma。因为对于堆的大小调整和空间管理还是比较麻烦的,重新建一个vma会更方便(上面提到的free的问题也是原因之一)。
那么为什么不总是在malloc的时候去mmap一个新的vma呢?第一,对于小空间的分配与回收,被libc管理的堆空间已经能够满足需要,不必每次都去进行系统调用。并且vma是以page为单位的,最小就是分配一个页;第二,太多的vma会降低系统性能。缺页异常、vma的新建与销毁、堆空间的大小调整、等等情况下,都需要对vma进行操作,需要在当前进程的所有vma中找到需要被操作的那个(或那些)vma。vma数目太多,必然导致性能下降。(在进程的vma较少时,内核采用链表来管理vma;vma较多时,改用红黑树来管理。)
[用户的栈]
与堆一样,栈也是一个vma(图:左中),这个vma是一端固定、一端可伸(注意,不能缩)的。这个vma比较特殊,没有类似brk的系统调用让这个vma伸展,它是自动伸展的。
当用户访问的虚拟地址越过这个vma时,内核会在处理缺页异常的时候将自动将这个vma增大。内核会检查当时的栈寄存器(如:ESP),访问的虚拟地址不能超过ESP加n(n为CPU压栈指令一次性压栈的最大字节数)。也就是说,内核是以ESP为基准来检查访问是否越界。
但是,ESP的值是可以由用户态程序自由读写的,用户程序如果调整ESP,将栈划得很大很大怎么办呢?内核中有一套关于进程限制的配置,其中就有栈大小的配置,栈只能这么大,再大就出错。
对于一个进程来说,栈一般是可以被伸展得比较大(如:8MB)。然而对于线程呢?
首先线程的栈是怎么回事?前面说过,线程的mm是共享其父进程的。虽然栈是mm中的一个vma,但是线程不能与其父进程共用这个vma(两个运行实体显然不用共用一个栈)。于是,在线程创建时,线程库通过mmap新建了一个vma,以此作为线程的栈(大于一般为:2M)。
可见,线程的栈在某种意义上并不是真正栈,它是一个固定的区域,并且容量很有限。
通过本文,你应该对Linux内存管理有了一个基本的了解,它是一种实现虚拟内存和物理内存的转换和分配的有效方式,可以适应Linux系统的多样化需求。当然,内存管理也不是一成不变的,它需要根据具体的硬件平台和内核版本进行定制和修改。总之,内存管理是Linux系统中不可或缺的一个组件,值得你深入学习和掌握。
以上是Linux内存管理:如何实现虚拟内存和物理内存的转换和分配的详细内容。更多信息请关注PHP中文网其他相关文章!