
击败OpenAI,权重、数据、代码全开源,能完美复现的嵌入模型Nomic Embed来了

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-02-04 09:54:151217浏览
一周前,OpenAI给用户送出福利。他们解决了GPT-4变懒的问题,并推出了5个新模型,其中包括text-embedding-3-small嵌入模型,它更小巧高效。
嵌入是用来表示自然语言、代码等内容中的概念的数字序列。它们帮助机器学习模型和其他算法更好地理解内容之间的关联,也更容易执行聚类或检索等任务。在 NLP 领域,嵌入起着非常重要的作用。
不过,OpenAI 的嵌入模型并不是免费给大家使用的,比如 text-embedding-3-small 的收费价格是每 1k tokens 0.00002 美元。
现在,比 text-embedding-3-small 更好的嵌入模型来了,并且还不收费。
Nomic AI,一家AI初创公司,近日发布了首个开源、开放数据、开放权重、开放训练代码的嵌入模型——Nomic Embed。该模型具有完全可复现和可审核的特点,其上下文长度为8192。在短上下文和长上下文的基准测试中,Nomic Embed击败了OpenAI的text-embeding-3-small和text-embedding-ada-002模型。这一成就标志着Nomic AI在嵌入模型领域的重要进展。

文本嵌入是现代NLP应用程序中的一个关键组成部分,用于提供检索增强生成(RAG)功能,为LLM和语义搜索提供支持。该技术通过将句子或文档的语义信息编码为低维向量,并将其应用于下游应用程序,如数据可视化、分类和信息检索的聚类,以实现更高效的处理。 目前,OpenAI的text-embedding-ada-002是最受欢迎的长上下文文本嵌入模型之一,它支持高达8192个上下文长度。然而,遗憾的是,Ada是闭源的,并且无法对其训练数据进行审计,这使得其可信度受到一定的限制。尽管如此,该模型仍然被广泛使用,并在许多NLP任务中表现出色。 未来,我们希望能够开发更加透明和可审计的文本嵌入模型,以提高其可信度和可靠性。这将有助于推动NLP领域的发展,并为各类应用程序提供更加高效和准确的文本处理能力。
性能最佳的开源长上下文文本嵌入模型,如E5-Mistral和jina-embeddings-v2-base-en,可能存在一些限制。一方面,由于模型大小较大,可能不适合用于通用用途。另一方面,这些模型可能无法超越OpenAI对应模型的性能水平。因此,在选择适合特定任务的模型时,需要考虑这些因素。
Nomic-embed 的发布改变了这一点。该模型的参数量只有 137M ,非常便于部署,5 天就训练好了。

论文地址:https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf
论文题目:Nomic Embed: Training a Reproducible Long Context Text Embedder
项目地址:https://github.com/nomic-ai/contrastors
如何构建 nomic-embed
现有文本编码器的主要缺点之一是受到序列长度限制,仅限于 512 个 token。为了训练更长序列的模型,首先要做的就是调整 BERT,使其能够适应长序列长度,该研究的目标序列长度为 8192。
训练上下文长度为 2048 的 BERT
该研究遵循多阶段对比学习 pipeline 来训练 nomic-embed。首先该研究进行 BERT 初始化,由于 bert-base 只能处理最多 512 个 token 的上下文长度,因此该研究决定训练自己的 2048 个 token 上下文长度的 BERT——nomic-bert-2048。
受 MosaicBERT 的启发,研究团队对 BERT 的训练流程进行了一些修改,包括:
- 使用旋转位置嵌入来允许上下文长度外推;
- 使用 SwiGLU 激活,因为它已被证明可以提高模型性能;
- 将 dropout 设置为 0。
并进行了以下训练优化:
- 使用Deepspeed 和FlashAttention 进行训练;
- 以BF16 精度进行训练;
- 将词表(vocab)大小增加到64 的倍数;
- 训练的批大小为4096;
- 在掩码语言建模过程中,掩码率为30%,而不是15%;
- 不使用下一句预测目标。
训练时,该研究以最大序列长度 2048 来训练所有阶段,并在推理时采用动态 NTK 插值来扩展到 8192 序列长度。
实验
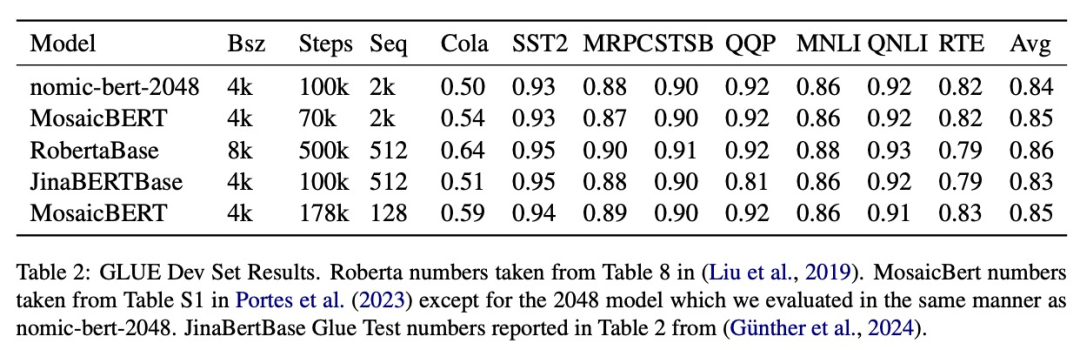
该研究在标准 GLUE 基准上评估了 nomic-bert-2048 的质量,发现它的性能与其他 BERT 模型相当,但具有显着更长的上下文长度优势。
nomic-embed 的对比训练
该研究使用 nomic-bert-2048 初始化 nomic-embed 的训练。对比数据集由约 2.35 亿文本对组成,并在收集过程中使用 Nomic Atlas 广泛验证了其质量。
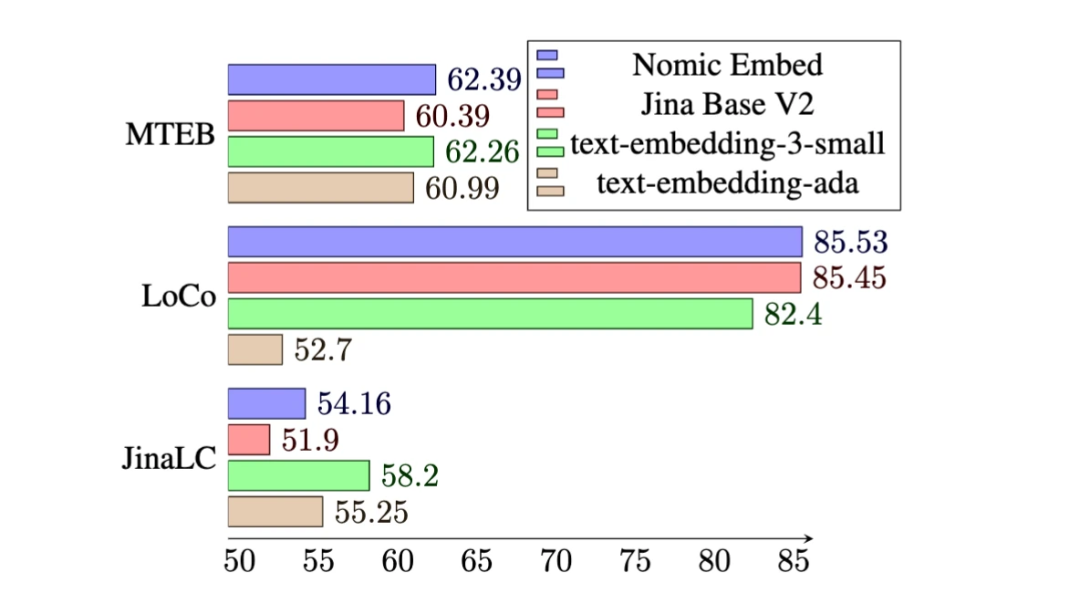
在 MTEB 基准上,nomic-embed 的性能优于 text-embedding-ada-002 和 jina-embeddings-v2-base-en。
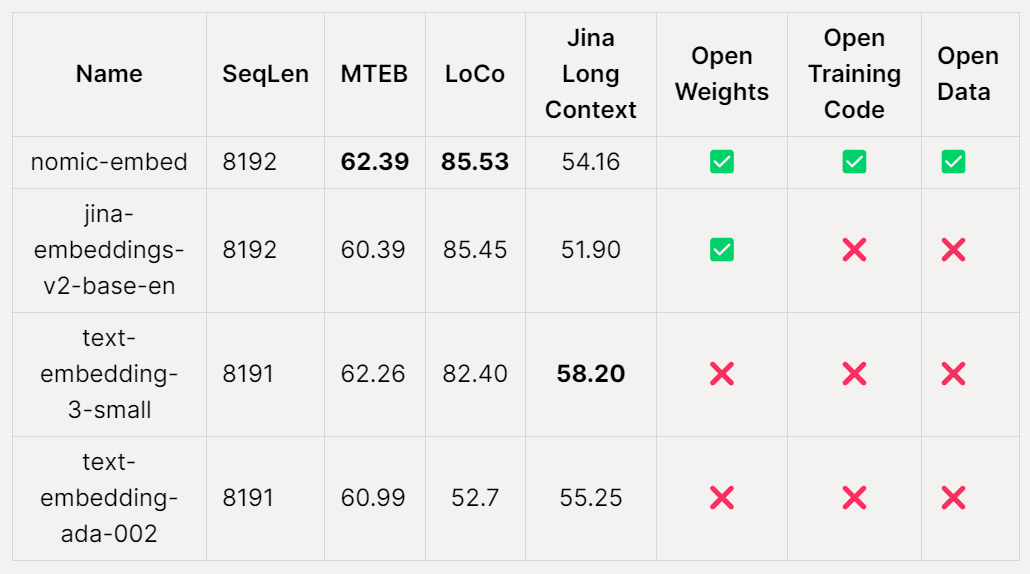
然而,MTEB 不能评估长上下文任务。因此,该研究在最近发布的 LoCo 基准以及 Jina Long Context 基准上评估了 nomic-embed。
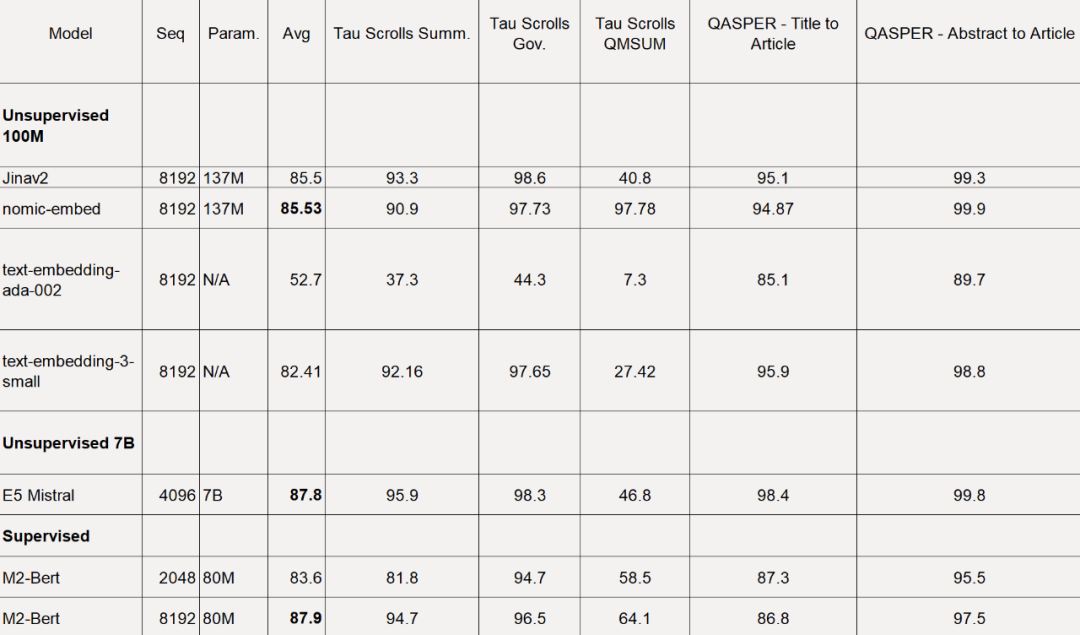
对于 LoCo 基准,该研究按照参数类别以及评估是在监督或无监督设置中执行的分别进行评估。
如下表所示,Nomic Embed 是性能最佳的 100M 参数无监督模型。值得注意的是,Nomic Embed 可与7B 参数类别中表现最好的模型以及专门针对LoCo 基准在监督环境中训练的模型媲美:
在Jina Long Context 基准上,Nomic Embed 的总体表现也优于jina-embeddings-v2-base-en,但Nomic Embed 在此基准测试中的表现并不优于OpenAI ada-002 或text-embedding-3-small:
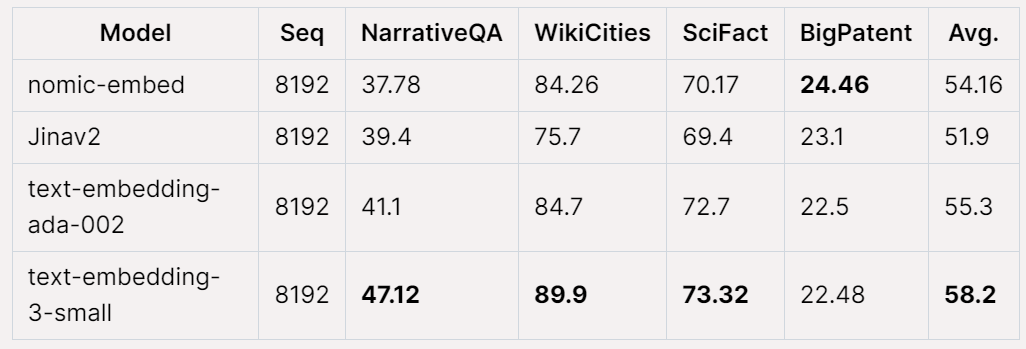
总体而言,Nomic Embed 在2/3 基准测试中优于OpenAI Ada-002 和text-embedding-3-small。
该研究表示,使用Nomic Embed 的最佳选择是Nomic Embedding API,获得API 的途径如下所示:

最后是数据访问:为了访问完整数据,该研究向用户提供了Cloudflare R2 (类似AWS S3 的对象存储服务)访问密钥。要获得访问权限,用户需要先创建 Nomic Atlas 帐户并按照 contrastors 存储库中的说明进行操作。
contrastors 地址:https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
以上是击败OpenAI,权重、数据、代码全开源,能完美复现的嵌入模型Nomic Embed来了的详细内容。更多信息请关注PHP中文网其他相关文章!