



写在前面&笔者的个人理解
下一代自动驾驶技术期望依赖于智能感知、预测、规划和低级别控制之间的专门集成和交互。自动驾驶算法性能的上限一直存在巨大的瓶颈,学术界和业界一致认为,克服瓶颈的关键在于以数据为中心的自动驾驶技术。AD仿真、闭环模型训练和AD大数据引擎近期已经获得了一些宝贵的经验。然而,对于如何构建高效的以数据为中心的AD技术来实现AD算法的自进化和更好的AD大数据积累,缺乏系统的知识和深刻的理解。为了填补这一研究空白,这里将密切关注最新的数据驱动自动驾驶技术,重点是自动驾驶数据集的全面分类,主要包括里程碑、关键特征、数据采集设置等。此外我们从产业前沿对现有的基准闭环AD大数据pipeline进行了系统的回顾,包括闭环框架的过程、关键技术和实证研究。最后讨论了未来的发展方向、潜在应用、局限性和关注点,以引起学术界和工业界的共同努力,推动自动驾驶的进一步发展。
总结来说,主要贡献如下:
- 介绍了第一个按里程碑代、模块化任务、传感器套件和关键功能分类的自动驾驶数据集综合分类法;
- 基于深度学习和生成人工智能模型,对最先进的闭环数据驱动自动驾驶pipeline和相关关键技术进行系统回顾;
- 给出了闭环大数据驱动pipeline在自动驾驶工业应用中如何工作的实证研究;
- 讨论了当前pipeline和解决方案的优缺点,以及以数据为中心的自动驾驶未来的研究方向。
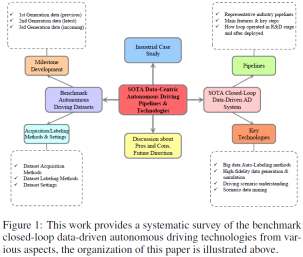
SOTA自动驾驶数据集:分类和发展
自动驾驶数据集的演变反映了该领域的技术进步和日益增长的雄心。20世纪末的早期进展院的AVT研究和加州大学伯克利分校的PATH计划,为基本的传感器数据奠定了基础,但受到时代技术水平的限制。在过去的二十年里,在传感器技术、计算能力和复杂的机器学习算法的进步的推动下,出现了重大的飞跃。2014年,美国汽车工程师学会(SAE)向公众公布了一个系统化的六级(L0-L5)自动驾驶系统,该系统得到了自动驾驶研发进展的广泛认可。在深度学习的推动下,基于计算机视觉的方法已经主导了智能感知。深度强化学习及其变体为智能规划和决策提供了至关重要的改进。最近,大型语言模型(LLM)和视觉语言模型(VLM)展示了它们强大的场景理解、驾驶行为推理和预测以及智能决策能力,为自动驾驶的未来发展开辟了新的可能性。
自动驾驶数据集的里程碑式发展
图2按照时间顺序展示了开源自动驾驶数据集的里程碑式开发。显著的进步导致主流数据集被分为三代,其特点是数据集的复杂性、数量、场景多样性和标注粒度都有了显著的飞跃,将该领域推向了技术成熟的新前沿。具体而言,横轴表示开发时间轴。每行的侧头包括数据集名称、传感器模态、合适的任务、数据收集地点和相关挑战。为了进一步比较不同世代的数据集,我们使用不同颜色的条形图来可视化感知和预测/规划数据集规模。早期阶段,即2012年开始的第一代,由KITTI和Cityscapes牵头,为感知任务提供了高分辨率图像,是视觉算法基准进度的基础。推进到第二代,NuScenes、Waymo、Argoverse 1等数据集引入了一种多传感器方法,将车载摄像头、高精地图(HD Map)、激光雷达、雷达、GPS、IMU、轨迹、周围物体的数据集成在一起,这对于全面的驾驶环境建模和决策过程至关重要。最近,NuPlan、Argoverse 2和Lyft L5显著提高了影响标准,提供了前所未有的数据规模,并培育了一个有利于尖端研究的生态系统。这些数据集以其庞大的规模和多模态传感器集成为特点,在开发感知、预测和规划任务的算法方面发挥了重要作用,为先进的End2End或混合自动驾驶模型铺平了道路。2024年,我们迎来了第三代自动驾驶数据集。在VLM、LLM和其他第三代人工智能技术的支持下,第三代数据集强调了行业致力于应对自动驾驶日益复杂的挑战,如数据长尾分布问题、分布外检测、角点案例分析等。

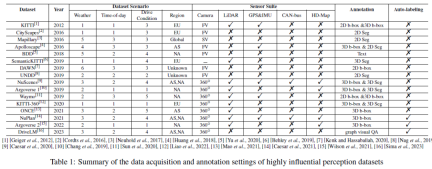
数据集采集、设置和关键功能
表1总结了具有高度影响力的感知数据集的数据采集和标注设置,包括驾驶场景、传感器套件和标注,我们报告了数据集场景下天气/时间/驾驶条件类别的总数,其中天气通常包括晴天/多云/雾天/下雨/雪/其他(极端条件);一天中的时间通常包括上午、下午和晚上;驾驶条件通常包括城市街道、主干道、小街、农村地区、高速公路、隧道、停车场等。场景越多样化,数据集就越强大。我们还报告了数据集收集的区域,表示为as(亚洲)、EU(欧洲)、NA(北美)、SA(南美)、AU(澳大利亚)、AF(非洲)。值得注意的是,Mapillary是通过AS/EU/NA/SA/AF/AF收集的,DAWN是从谷歌和必应图像搜索引擎收集的。对于传感器套件,我们研究了相机、激光雷达、GPS和IMU等。表1中的FV和SV分别是前视图相机和街景相机的缩写。360°全景摄像头设置,通常由多个前视图摄像头、罕见视图摄像头和侧视图摄像头组成。我们可以观察到,随着AD技术的发展,数据集中包含的传感器类型和数量正在增加,数据模式也越来越多样化。关于数据集标注,早期的数据集通常采用手动标注方法,而最近的NuPlan、Argoverse 2和DriveLM对AD大数据采用了自动标注技术。我们认为,从传统的手动标注到自动标注的转变是未来以数据为中心的自动驾驶的一大趋势。
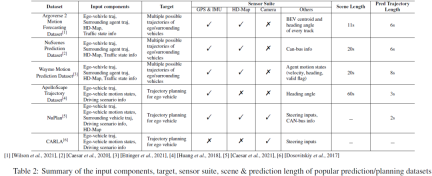
对于预测和规划任务,我们在表2中总结了主流数据集的输入/输出分量、传感器套件、场景长度和预测长度。对于运动预测/预测任务,输入组件通常包括自车历史轨迹、周围代理历史轨迹、高精地图和交通状态信息(即交通信号状态、道路ID、停车标志等)。目标输出是自车和/或周围主体在短时间内的几个最可能的轨迹(例如前5或前10轨迹)。运动预测任务通常采用滑动时间窗口设置,将整个场景划分为几个较短的时间窗口。例如,NuScenes采用过去2秒的GT据和高精地图来预测下一个6秒的轨迹,而Argoverse 2采用历史5秒的地面真相和高精地图预测未来6秒的轨道。NuPlan、CARLA和ApoloScape是最受欢迎的规划任务数据集。输入组件包括自我/周围车辆历史轨迹、自我车辆运动状态和驾驶场景表示。虽然NuPlan和ApoloScape是在现实世界中获得的,但CARLA是一个模拟数据集。CARLA包含在不同城镇的模拟驾驶过程中拍摄的道路图像。每个道路图像都带有一个转向角,它表示保持车辆正常行驶所需的调整。规划的预测长度可以根据不同算法的要求而变化。
闭环数据驱动的自动驾驶系统
我们现在正从以前的软件和算法定义的自动驾驶时代转向新的鼓舞人心的大数据驱动和智能模型协同自动驾驶时代。闭环数据驱动系统旨在弥合AD算法训练与其现实世界应用/部署之间的差距。与传统的开环方法不同,在传统开环方法中,模型是在从人类客户驾驶或道路测试中收集的数据集上被动训练的,闭环系统与真实环境动态交互。这种方法解决了分布变化的挑战——从静态数据集学习的行为可能无法转化为真实世界驾驶场景的动态性质。闭环系统允许AV从互动中学习并适应新的情况,通过行动和反馈的迭代循环进行改进。
然而,由于几个关键问题,构建现实世界中以数据为中心的闭环AD系统仍然具有挑战性:第一个问题与AD数据收集有关。在现实世界的数据采集中,大多数数据样本是常见/正常驾驶场景,而弯道和异常驾驶场景的数据几乎无法采集。其次,需要进一步努力探索准确高效的AD数据自动标注方法。第三,为了缓解AD模型在城市环境中某些场景中表现不佳的问题,应该强调场景数据挖掘和场景理解。
SOTA闭环自动驾驶pipeline
自动驾驶行业正在积极构建集成的大数据平台,以应对大量AD数据积累带来的挑战。这可以被恰当地称为数据驱动自动驾驶时代的新基础设施。在我们对顶级AD公司/研究机构开发的数据驱动闭环系统的调查中,我们发现了几个共性:
- 这些pipeline通常遵循一个工作流循环,包括:(I)数据采集,(II)数据存储,(III)数据选择和预处理,(IV)数据标注,(V)AD模型训练,(VI)模拟/测试验证,以及(VII)真实世界部署。
- 系统内闭环的设计,现有的解决方案要么选择单独设置的“数据闭环”和“模型闭环”,要么分别设置不同阶段的周期:“研发阶段闭环”、“部署阶段闭环”。
- 之外,该行业还强调了真实世界AD数据集的长期分布问题以及处理角落案例时的挑战。特斯拉和英伟达是这一领域的行业先驱,其数据系统架构为该领域的发展提供了重要参考。
NVIDIA MagLev AV平台图3(左))遵循“收集→ 选择→ 标签→ 驯龙”作为程序,它是一个可复制的工作流程,可以实现SDC的主动学习,并在循环中进行智能标注。MagLev主要包括两条闭环pipeline。第一个循环是以自动驾驶数据为中心,从数据摄入和智能选择开始,通过标注和标注,然后是模型搜索和训练。然后对经过训练的模型进行评估、调试,并最终部署到现实世界中。第二个闭环是平台的基础设施支持系统,包括数据中心骨干和硬件基础设施。此循环包括安全的数据处理、可扩展的DNN和系统KPI、用于跟踪和调试的仪表板。它支持AV开发的全周期,确保在开发过程中不断改进和整合真实世界的数据和模拟反馈。
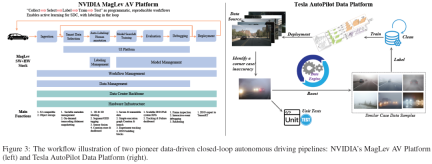
特斯拉自动驾驶数据平台(图3(右))是另一个具有代表性的AD平台,它强调使用大数据驱动的闭环pipeline来显著提高自动驾驶模型的性能。pipeline从源数据收集开始,通常来自特斯拉的车队学习、事件触发车端数据收集和阴影模式。收集到的数据将由数据平台算法或人类专家进行存储、管理和检查。无论何时发现角落案例/不准确性,数据引擎都将从现有数据库中检索并匹配与角落案例/不准确事件高度相似的数据样本。同时,将开发单元测试,以复制场景并严格测试系统的响应。之后,检索到的数据样本将由自动标注算法或人类专家进行标注。然后,标注良好的数据将反馈给AD数据库,数据库将被更新以生成用于AD感知/预测/规划/控制模型的新版本的训练数据集。经过模型训练、验证、仿真和真实世界测试,具有更高性能的新AD模型将发布并部署。
基于Generative AI的高保真AD数据生成与仿真
从真实世界采集的大多数AD数据样本都是常见/正常驾驶场景,其中我们在数据库中已经有大量类似的样本。然而,要从真实世界的采集中收集某种类型的AD数据样本,我们需要驾驶指数级的长时间,这在工业应用中是不可行的。因此,高保真自动驾驶数据生成和仿真方法引起了学术界的极大关注。CARLA是一款用于自动驾驶研究的开源模拟器,能够在用户指定的各种设置下生成自动驾驶数据。CARLA的优势在于其灵活性,允许用户创建不同的道路条件、交通场景和天气动态,这有助于全面的模型训练和测试。然而,作为模拟器,其主要缺点在于领域差距。CARLA生成的AD数据无法完全模拟真实世界的物理和视觉效果;真实驾驶环境的动态和复杂特征也没有被表现出来。
最近,世界模型以其更先进的内在概念和更有前景的性能,已被用于高保真度AD数据生成。世界模型可以被定义为一个人工智能系统,它构建其感知的环境的内部表示,并使用学习到的表示来模拟环境中的数据或事件。一般世界模型的目标是表示和模拟各种情况和互动,就像成熟的人类在现实世界中遇到的一样。在自动驾驶领域,GAIA-1和DriveDreamer是基于世界模型的数据生成的代表作。GAIA-1是一个生成型人工智能模型,通过将原始图像/视频以及文本和动作提示作为输入,实现图像/视频到图像/视频的生成。GAIA-1的输入模态被编码成统一的令牌序列。这些标注由世界模型内的自回归变换器处理,以预测后续的图像标注。然后,视频解码器将这些标注重建为具有增强的时间分辨率的连贯视频输出,从而实现动态和上下文丰富的视觉内容生成。DriveDreamer在其架构中创新地采用了扩散模型,专注于捕捉现实世界驾驶环境的复杂性。它的两阶段训练pipeline首先使模型能够学习结构化的交通约束,然后预测未来的状态,确保为自动驾驶应用程序量身定制的强大的环境理解。
自动驾驶数据集的自动标注方法
高质量的数据标注成功和可靠性是必不可少的。到目前为止,数据标注pipeline可以分为三种类型,从传统的手工标注到半自动标注,再到最先进的全自动标注方法,如图4所示AD数据标注通常被视为特定于任务/模型。工作流程从仔细准备标注任务和原始数据集的需求开始。然后,下一步是使用人工专家、自动标注算法或End2End大型模型生成初始标注结果。之后,标注质量将由人工专家或自动质量检查算法根据预定义的要求进行检查。如果本轮标注结果未能通过质量检查,它们将再次发送回标注循环并重复此标注作业,直到它们满足预定义的要求。最后,我们可以获得现成的标注AD数据集。

自动标注方法是闭环自动驾驶大数据平台缓解人工标注劳动密集、提高AD数据闭环循环效率、降低相关成本的关键。经典的自动标记任务包括场景分类和理解。最近,随着BEV方法的普及,AD数据标注的行业标准也在不断提高,自动标注任务也变得更加复杂。在当今工业前沿的场景中,3D动态目标自动标注和3D静态场景自动标注是两种常用的高级自动标注任务。
场景分类和理解是自动驾驶大数据平台的基础,系统将视频帧分类为预定义的场景,如驾驶场所(街道、高速公路、城市立交桥、主干道等)和场景天气(晴天、雨天、雪天、雾天、雷雨天等)。基于CNN的方法通常用于场景分类,包括预训练+微调CNN模型、多视图和多层CNN模型,以及用于改进场景表示的各种基于CNN的模型。场景理解超越了单纯的分类。它涉及解释场景中的动态元素,如周围的车辆代理、行人和红绿灯。除了基于图像的场景理解外,基于激光雷达的数据源,如SemanticKITTI,也因其提供的细粒度几何信息而被广泛采用。
三维动态物体自动标注和三维静态场景自动标注的出现是为了满足广泛采用的纯电动汽车感知技术的要求。Waymo提出了一种基于激光雷达点云序列数据的3D自动标记流水线,该流水线使用3D检测器逐帧定位目标。然后,通过多目标跟踪器链接跨帧的已识别目标的边界框。为每个目标提取目标轨迹数据(每个帧处的对应点云+3D边界框),并使用分治架构进行以目标为中心的自动标记,以生成最终细化的3D边界框作为标签。优步提出的Auto4D pipeline首次探索了时空尺度下的AD感知标记。在自动驾驶领域中,空间尺度内的3D目标边界框标记以及时间尺度内的1D对应时间戳标记被称为4D标记。Auto4D pipeline从连续的激光雷达点云开始,以建立初始物体轨迹。该轨迹由目标大小分支进行细化,该分支使用目标观测值对目标大小进行编码和解码。同时,运动路径分支对路径观测和运动进行编码,允许路径解码器以恒定的目标大小细化轨迹。
3D静态场景自动标记可被视为HDMap生成,其中车道、道路边界、人行横道、红绿灯和驾驶场景中的其他相关元素应进行标注。在这一主题下,有几项有吸引力的研究工作:基于视觉的方法,如MVMap,NeMO;基于激光雷达的方法,如VMA;预训练3D场景重建方法,如OccBEV,OccNet/ADPT,ALO。VMA是最近提出的一项用于3D静态场景自动标记的工作。VMA框架利用众包、多行程聚合的激光雷达点云来重建静态场景,并将其分割成单元进行处理。基于MapTR的单元标注器通过查询和解码将原始输入编码为特征图,生成语义类型的点序列。VMA的输出是矢量化地图,将通过闭环标注和人工验证对其进行细化,从而为自动驾驶提供满意的高精地图。
实证研究
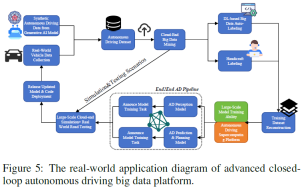
我们提供了一个实证研究,以更好地说明本文中提到的先进的闭环AD数据平台。整个过程图如图5所示。在这种情况下,研究人员的目标是开发一个基于Generative AI和各种基于深度学习的算法的AD大数据闭环pipeline,从而在自动驾驶算法研发阶段和OTA升级阶段(在现实世界部署后)实现数据闭环。具体而言,生成人工智能模型用于(1)基于工程师提供的文本提示生成特定场景的高保真度AD数据。(2) AD大数据自动标注,有效准备地面实况标签。
图中显示了两个闭环。其中较大的一个阶段是自动驾驶算法研发阶段,该阶段从生成人工智能模型的合成自动驾驶数据和从真实世界驾驶中获取的数据样本的数据收集开始。这两种数据源被集成为一个自动驾驶数据集,在云端进行挖掘,以获得有价值的见解。之后,数据集进入了双重标记路径:基于深度学习的自动标记或手动手工标记,确保了标注的速度和精度。然后,标记的数据被用于在高容量自动驾驶超级计算平台上训练模型。这些模型经过模拟和真实世界的道路测试,以评估其功效,从而发布自动驾驶模型并进行后续部署。较小的一个是针对真实世界部署后的OTA升级阶段,该阶段涉及大规模云端模拟和真实世界测试,以收集AD算法的不准确/角落情况。所识别的不准确性/角点情况用于通知模型测试和更新的下一次迭代。例如,假设我们发现我们的AD算法在隧道驾驶场景中表现不佳。已识别的隧道驾驶弯道情况将立即向环路公布,并在下一次迭代中更新。生成型人工智能模型将以隧道驾驶场景相关描述作为文本提示,生成大规模的隧道驾驶数据样本。生成的数据和原始数据集将被输入模拟、测试和模型更新。这些过程的迭代性质对于优化模型以适应具有挑战性的环境和新数据,保持自动驾驶功能的高精度和可靠性至关重要。
讨论
第三代及以后的新型自动驾驶数据集。尽管LLM/VLM等基础模型在语言理解和计算机视觉方面取得了成功,但将其直接应用于自动驾驶仍然具有挑战性。原因有两个方面:一方面,这些LLM/VLM必须具有全面集成和理解多源AD大数据(如FOV图像/视频、激光雷达云点、高清地图、GPS/IMU数据等)的能力,这比理解我们在日常生活中看到的图像更难。另一方面,自动驾驶领域现有的数据规模和质量与其他领域(如金融和医疗)不可比,难以支持更大容量LLM/VLM的训练和优化。由于法规、隐私问题和成本的原因,目前自动驾驶大数据的规模和质量有限。我们相信,在各方的共同努力下,下一代AD大数据在规模和质量上都会有显著提升。
自动驾驶算法的硬件支持。当前的硬件平台已经取得了重大进展,特别是随着GPU和TPU等专门处理器的出现,这些处理器提供了对深度学习任务至关重要的大量并行计算能力。车载和云基础设施中的高性能计算资源对于实时处理车辆传感器生成的大量数据流至关重要。尽管取得了这些进步,但在处理自动驾驶算法日益复杂的问题时,在可扩展性、能效和处理速度方面仍然存在局限性。VLM/LLM引导的用户-车辆交互是一个非常有前景的应用案例。基于该应用程序可以收集用户特定的行为大数据。然而,VLM/LLM在车端的设备将要求高标准的硬件计算资源,并且交互式应用程序预计具有低延迟。因此,未来可能会有一些重量轻的大型自动驾驶车型,或者LLM/VLM的压缩技术将得到进一步研究。
基于用户行为数据的个性化自动驾驶推荐。智能汽车,已经从简单的交通工具发展到智能终端场景的最新应用扩展。因此,人们对配备先进自动驾驶功能的车辆的期望是,它们能够从历史驾驶数据记录中学习驾驶员的行为偏好,如驾驶风格和行驶路线偏好。这将使智能汽车在未来帮助驾驶员进行车辆控制、驾驶决策和路线规划时能够更好地与用户喜爱的车辆保持一致。我们将上述概念称为个性化自动驾驶推荐算法。推荐系统已广泛应用于电子商务、在线购物、送餐、社交媒体和直播平台。然而,在自动驾驶领域,个性化推荐仍处于起步阶段。我们相信,在不久的将来,将设计一个更合适的数据系统和数据采集机制,在用户允许并遵守相关规定的情况下,收集用户驾驶行为偏好的大数据,从而为用户实现定制的自动驾驶推荐系统。
数据安全和值得信赖的自动驾驶。海量的自动驾驶大数据对数据安全和用户隐私保护提出了重大挑战。随着互联自动驾驶汽车(CAV)和车联网(IoV)技术的发展,车辆的连接越来越紧密,从驾驶习惯到频繁路线的详细用户数据的收集引发了人们对个人信息潜在滥用的担忧。我们建议在收集的数据类型、保留策略和第三方共享方面具有透明度的必要性。它强调了用户同意和控制的重要性,包括尊重“不跟踪”请求和提供删除个人数据的选项。对于自动驾驶行业来说,在促进创新的同时保护这些数据需要严格遵守这些准则,确保用户信任并遵守不断发展的隐私立法。
除了数据安全和隐私,另一个问题是如何实现值得信赖的自动驾驶。随着AD技术的巨大发展,智能算法和生成人工智能模型(如LLM、VLM)将在执行越来越复杂的驾驶决策和任务时“充当驱动因素”。在这个领域下,一个自然的问题出现了:人类能信任自动驾驶模型吗?在我们看来,值得信赖的关键在于自动驾驶模型的可解释性。他们应该能够向人类驾驶员解释做出决定的原因,而不仅仅是执行驾驶动作。LLM/VLM有望通过实时提供高级推理和可理解的解释来增强可信赖的自动驾驶。
结论
这项调查首次系统回顾了自动驾驶中以数据为中心的进化,包括大数据系统、数据挖掘和闭环技术。在这项调查中,我们首先制定了按里程碑代分类的数据集分类法,回顾了AD数据集在整个历史时间线上的发展,介绍了数据集的获取、设置和关键功能。此外,我们从学术和工业两个角度阐述了闭环数据驱动的自动驾驶系统。详细讨论了以数据为中心的闭环系统中的工作流pipeline、流程和关键技术。通过实证研究,展示了以数据为中心的闭环AD平台在算法研发和OTA升级方面的利用率和优势。最后,对现有数据驱动自动驾驶技术的优缺点以及未来的研究方向进行了全面的讨论。重点是第三代之后的新数据集、硬件支持、个性化AD推荐、可解释的自动驾驶。我们还表达了对Generative AI模型、数据安全和自动驾驶未来发展中值得信赖的担忧。

原文链接:https://mp.weixin.qq.com/s/YEjWSvKk6f-TDAR91Ow2rA
以上是数据为王!如何通过数据一步步构建高效的自动驾驶算法?的详细内容。更多信息请关注PHP中文网其他相关文章!

 从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM
从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM1 前言在发布DALL·E的15个月后,OpenAI在今年春天带了续作DALL·E 2,以其更加惊艳的效果和丰富的可玩性迅速占领了各大AI社区的头条。近年来,随着生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion models)的出现,深度学习已向世人展现其强大的图像生成能力;加上GPT-3、BERT等NLP模型的成功,人类正逐步打破文本和图像的信息界限。在DALL·E 2中,只需输入简单的文本(prompt),它就可以生成多张1024*1024的高清图像。这些图像甚至
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM
普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM“Making large models smaller”这是很多语言模型研究人员的学术追求,针对大模型昂贵的环境和训练成本,陈丹琦在智源大会青源学术年会上做了题为“Making large models smaller”的特邀报告。报告中重点提及了基于记忆增强的TRIME算法和基于粗细粒度联合剪枝和逐层蒸馏的CofiPruning算法。前者能够在不改变模型结构的基础上兼顾语言模型困惑度和检索速度方面的优势;而后者可以在保证下游任务准确度的同时实现更快的处理速度,具有更小的模型结构。陈丹琦 普
 解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM
解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?近期一些工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。基于此,来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer——Next-ViT。从延迟 / 准确性权衡的角度看,
 Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM
Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM3月27号,Stability AI的创始人兼首席执行官Emad Mostaque在一条推文中宣布,Stable Diffusion XL 现已可用于公开测试。以下是一些事项:“XL”不是这个新的AI模型的官方名称。一旦发布稳定性AI公司的官方公告,名称将会更改。与先前版本相比,图像质量有所提高与先前版本相比,图像生成速度大大加快。示例图像让我们看看新旧AI模型在结果上的差异。Prompt: Luxury sports car with aerodynamic curves, shot in a
 什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM
什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM译者 | 李睿审校 | 孙淑娟近年来, Transformer 机器学习模型已经成为深度学习和深度神经网络技术进步的主要亮点之一。它主要用于自然语言处理中的高级应用。谷歌正在使用它来增强其搜索引擎结果。OpenAI 使用 Transformer 创建了著名的 GPT-2和 GPT-3模型。自从2017年首次亮相以来,Transformer 架构不断发展并扩展到多种不同的变体,从语言任务扩展到其他领域。它们已被用于时间序列预测。它们是 DeepMind 的蛋白质结构预测模型 AlphaFold
 五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM
五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM人工智能就是一个「拼财力」的行业,如果没有高性能计算设备,别说开发基础模型,就连微调模型都做不到。但如果只靠拼硬件,单靠当前计算性能的发展速度,迟早有一天无法满足日益膨胀的需求,所以还需要配套的软件来协调统筹计算能力,这时候就需要用到「智能计算」技术。最近,来自之江实验室、中国工程院、国防科技大学、浙江大学等多达十二个国内外研究机构共同发表了一篇论文,首次对智能计算领域进行了全面的调研,涵盖了理论基础、智能与计算的技术融合、重要应用、挑战和未来前景。论文链接:https://spj.scien
 AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM
AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM说起2010年南非世界杯的最大网红,一定非「章鱼保罗」莫属!这只位于德国海洋生物中心的神奇章鱼,不仅成功预测了德国队全部七场比赛的结果,还顺利地选出了最终的总冠军西班牙队。不幸的是,保罗已经永远地离开了我们,但它的「遗产」却在人们预测足球比赛结果的尝试中持续存在。在艾伦图灵研究所(The Alan Turing Institute),随着2022年卡塔尔世界杯的持续进行,三位研究员Nick Barlow、Jack Roberts和Ryan Chan决定用一种AI算法预测今年的冠军归属。预测模型图


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

