
苹果公司采用自回归语言模型进行图像模型的预训练

- 王林转载
- 2024-01-29 09:18:271057浏览
1、背景
在GPT等大模型出现后,语言模型这种Transformer+自回归建模的方式,也就是预测next token的预训练任务,取得了非常大的成功。那么,这种自回归建模方式能不能在视觉模型上取得比较好的效果呢?今天介绍的这篇文章,就是Apple近期发表的基于Transformer+自回归预训练的方式训练视觉模型的文章,下面给大家展开介绍一下这篇工作。
 图片
图片
论文标题:Scalable Pre-training of Large Autoregressive Image Models
下载地址:https://arxiv.org/pdf/2401.08541v1.pdf
开源代码:https://github.com/apple/ml-aim
2、模型结构
模型结构基于Transformer,并采用语言模型中的next token prediction作为优化目标。主要修改有三个方面。首先,与ViT不同,本文采用GPT的单向attention,即每个位置的元素只与前面的元素计算attention。其次,我们引入了更多的上下文信息,以提高模型的语言理解能力。最后,我们优化了模型的参数设置,以进一步提升性能。通过这些改进,我们的模型在语言任务上取得了显著的性能提升。
 图片
图片
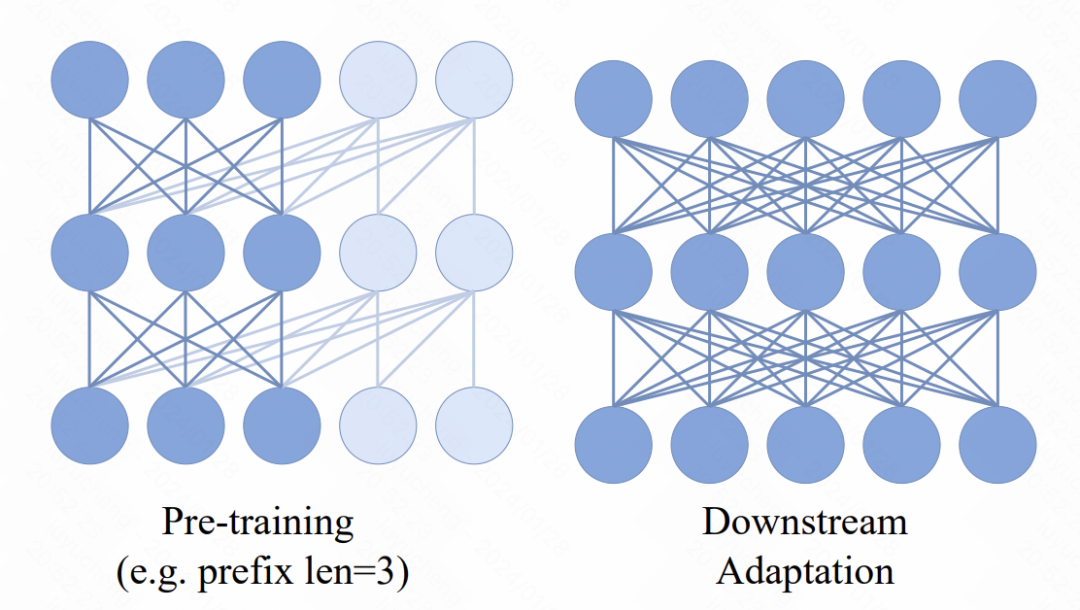
在Transformer模型中,引入了一个新的机制,即在输入序列前面加入了多个prefix token。这些token采用了双向attention机制。这一变化的主要目的是为了增强预训练和下游应用之间的一致性。在下游任务中,类似于ViT的双向attention方法被广泛使用。通过在预训练过程中引入prefix双向attention,模型可以更好地适应各种下游任务的需求。这样的改进可以提高模型的性能和泛化能力。
 图片
图片
在模型最终输出MLP层的优化方面,原先的预训练方法通常会丢弃掉MLP层,并在下游任务中使用一个全新的MLP。这是为了避免预训练的MLP过于偏向预训练任务,导致下游任务的效果下降。然而,在本文中,作者提出了一种新的方法。他们对每个patch都使用一个独立的MLP,同时也采用了各个patch的表征与attention融合的方式来代替传统的pooling操作。这样一来,预训练的MLP head在下游任务中的可用性得到了提升。通过这种方法,作者能够更好地保留图像整体的信息,并且避免了过度依赖预训练任务的问题。这对于提高模型的泛化能力和适应性非常有帮助。
在优化目标上,文中尝试了两种方法,第一种是直接拟合patch像素,用MSE进行预测。第二种是提前对图像patch进行tokenize,转换成分类任务,用交叉熵损失。不过在文中后续的消融实验中发现,第二种方法虽然也可以让模型正常训练,但是效果并不如基于像素粒度MSE的效果更好。
3、实验结果
文中的实验部分详细分析了这种基于自回归的图像模型的效果,以及各个部分对于效果的影响。
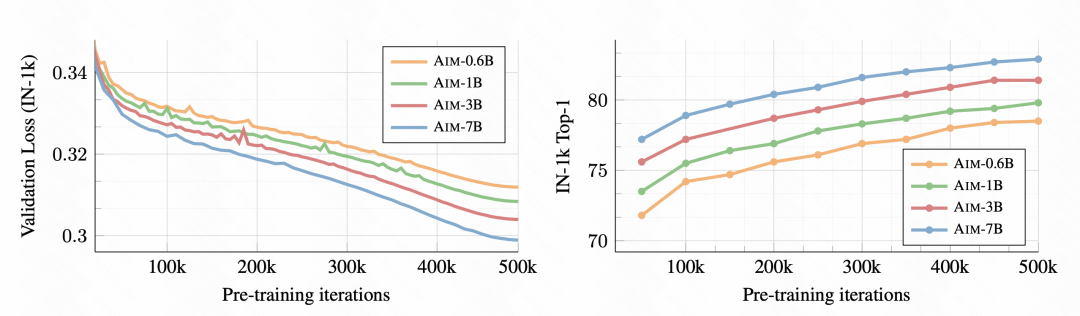
首先,随着训练的进行,下游的图像分类任务效果越来越好了,说明这种预训练方式确实能学到良好的图像表征信息。
 图片
图片
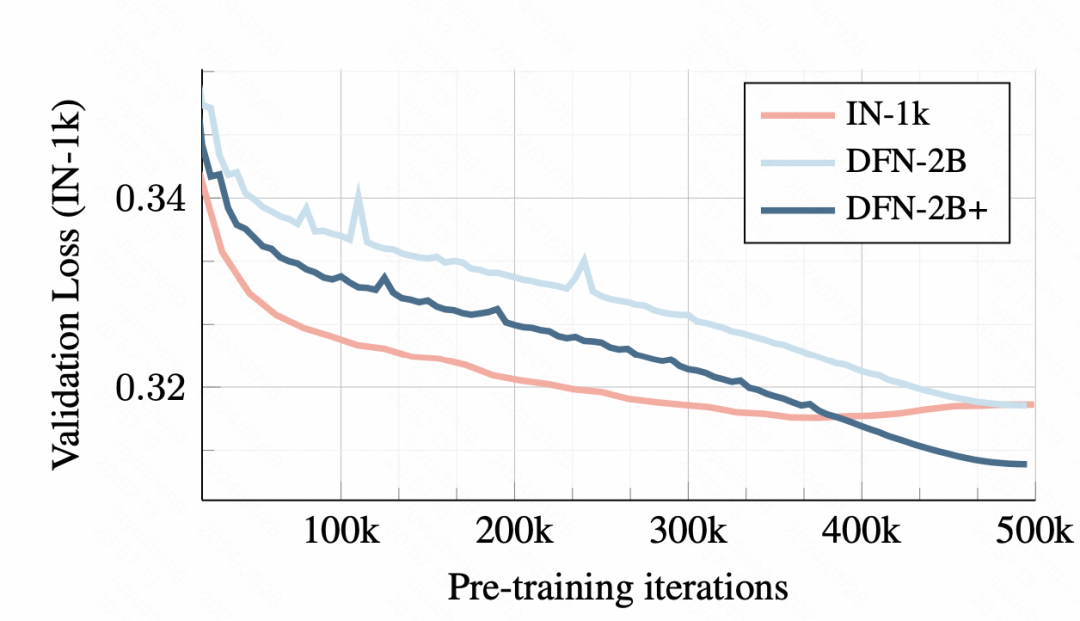
在训练数据上,使用小数据集的训练会导致overfitting,而使用DFN-2B虽然最开始验证集loss较大,但是没有明显的过拟合问题。
 图片
图片
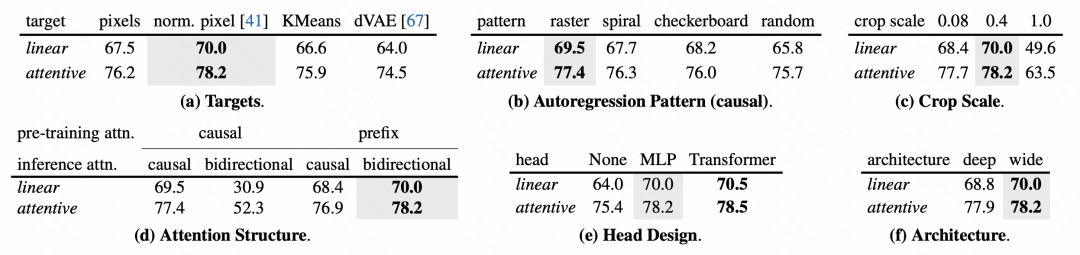
对于模型各个模块的设计方式,文中也进行了详细的消融实验分析。
 图片
图片
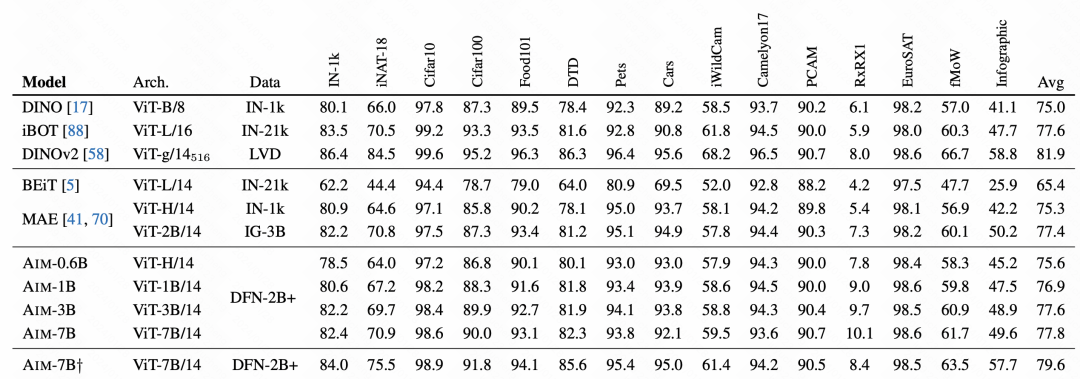
在最终的效果对比上,AIM取得了非常不错的效果,这也验证了这种自回归的预训练方式在图像上也是可用的,可能会成为后续图像大模型预训练的一种主要方式。
 图片
图片
以上是苹果公司采用自回归语言模型进行图像模型的预训练的详细内容。更多信息请关注PHP中文网其他相关文章!