
多个异构大模型的融合带来惊人效果

- PHPz转载
- 2024-01-29 09:12:281152浏览
随着LLaMA、Mistral等大语言模型的成功,许多公司开始创建自己的大语言模型。然而,从头训练新的模型成本高昂,且可能存在能力冗余。
近日,中山大学和腾讯 AI Lab 的研究人员提出了 FuseLLM,用于「融合多个异构大模型」。
与传统的模型集成和权重合并方法不同,FuseLLM提供了一种新的方式来融合多个异构大语言模型的知识。与同时部署多个大语言模型或要求合并模型结果不同,FuseLLM使用轻量级的持续训练方法,将各个模型的知识和能力转移到一个融合的大语言模型中。这种方法的独特之处在于它能够在推理时使用多个异构大语言模型,并将它们的知识外化到融合模型中。通过这种方式,FuseLLM有效地提高了模型的性能和效率。
该论文刚刚在 arXiv 上发布就引起了网友的大量关注和转发。

有人觉得在另一种语言上训练模型很有趣,我一直在思考这个问题。
目前该论文已被 ICLR 2024 接受。

- 论文标题:Knowledge Fusion of Large Language Models
- 论文地址:https://arxiv.org/abs/2401.10491
- 论文仓库:https://github.com/fanqiwan/FuseLLM
方法介绍
FuseLLM 的关键在于从概率分布表征的角度来探讨大语言模型的融合,对于同样的输入文本,作者认为由不同大语言模型生成的表征可以反映出它们在理解这些文本时的内在知识。因此,FuseLLM 首先利用多个源大语言模型生成表征,将它们的集体知识和各自优势外化,然后将生成的多个表征取长补短进行融合,最后经过轻量级的持续训练迁移到目标大语言模型。下图展示了 FuseLLM 方法的概述。
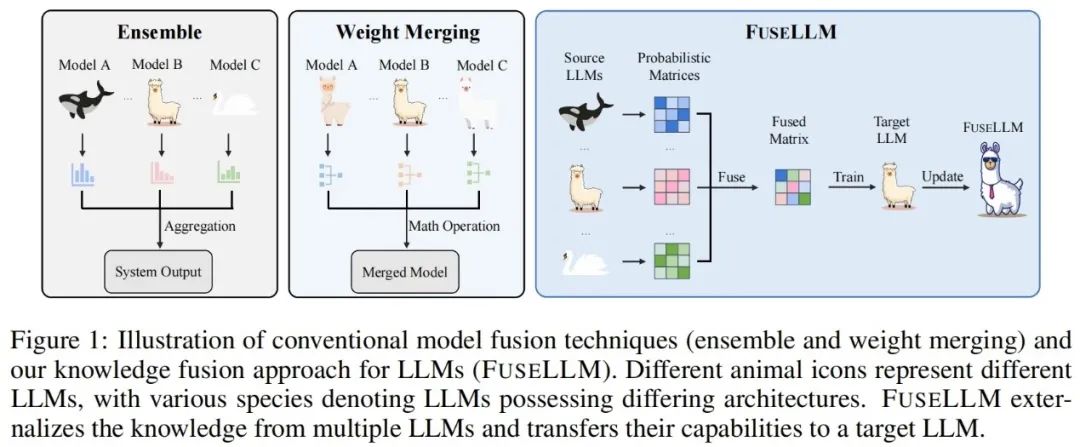
考虑到多个异构大语言模型的 tokenizer 以及词表存在差异,在融合多个表征时,如何对齐分词结果是一大关键: FuseLLM 在 token 级别的完全匹配之上,额外设计了基于最小编辑距离的词表级别对齐,最大程度地保留了表征中的可用信息。
为了在结合多个大语言模型的集体知识的同时保持其各自的优势,需要精心设计用于融合模型生成表征的策略。具体而言,FuseLLM 通过计算生成表征和标签文本之间交叉熵来评估不同大语言模型对这条文本的理解程度,然后引入了两种基于交叉熵的融合函数:
- MinCE: 输入多个大模型为当前文本生成的表征,输出交叉熵最小的表征;
- AvgCE: 输入多个大模型为当前文本生成的表征,输出基于交叉熵获得的权重加权平均的表征;
在持续训练阶段,FuseLLM 使用融合后的表征作为目标计算融合损失,同时也保留了语言模型损失。最终的损失函数为融合损失和语言模型损失之和。
实验结果
在实验部分,作者考虑了一个通用但具有挑战性的大语言模型融合场景,其中源模型在结构或能力上具备较小的共性。具体来说,其在 7B 规模上进行了实验,并选择了三个具有代表性的开源模型:Llama-2、OpenLLaMA,和 MPT 作为待融合的大模型。
作者在通用推理、常识推理、代码生成、文本生成、指令跟随等场景评估了 FuseLLM,发现其相较于所有源模型和继续训练基线模型取得了显着的性能提升。
通用推理& 常识推理
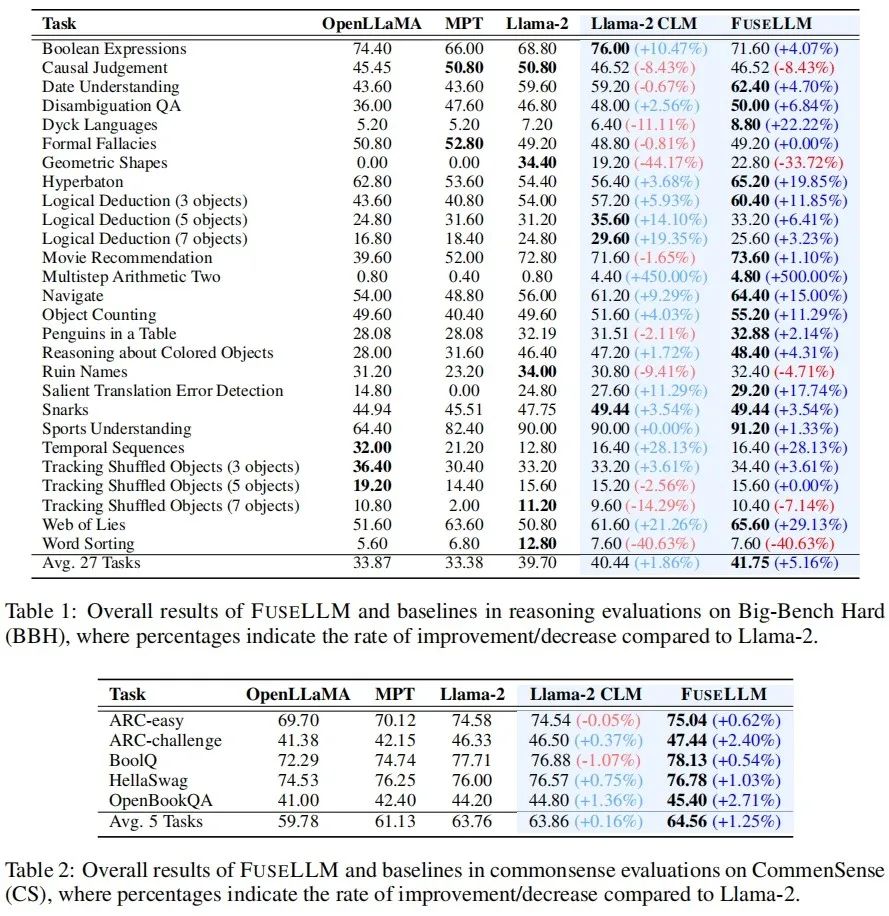
在测试通用推理能力的Big-Bench Hard Benchmark 上,经过持续训练后的Llama-2 CLM 相较于Llama-2 在27个任务上取得了平均1.86% 的提升,而FuseLLM 则相较于Llama-2 取得了5.16% 的提升,显着优于Llama-2 CLM,说明FuseLLM 能结合多个大语言模型的优势取得性能提升。
在测试常识推理能力的 Common Sense Benchmark 上,FuseLLM 超过了所有的源模型和基线模型,在所有任务上都取得了最佳的性能。
代码生成& 文本生成

在测试代码生成能力的MultiPL-E Benchmark 上,FuseLLM 在10 个任务中,有9 个超过了Llama-2,取得了平均6.36% 的性能提升。而 FuseLLM 没有超过 MPT 和 OpenLLaMA 的原因可能是由于使用 Llama-2 作为目标大语言模型,其代码生成能力较弱,且持续训练语料中的代码数据比例较低,仅占约 7.59%。
在多个测量知识问答(TrivialQA)、阅读理解(DROP)、内容分析(LAMBADA)、机器翻译(IWSLT2017)和定理应用(SciBench)的文本生成Benchmark 上,FuseLLM 也在所有任务中超过了所有源模型,并在80% 的任务中超过了Llama-2 CLM。
指令跟随

由于FuseLLM 仅需提取多个源模型的表征进行融合,然后对目标模型持续训练,因此其也能适用于指令微调大语言模型的融合。在评估指令跟随能力的 Vicuna Benchmark 上,FuseLLM 同样取得了出色表现,超过了所有源模型和 CLM。
FuseLLM vs. 知识蒸馏& 模型集成& 权重合并
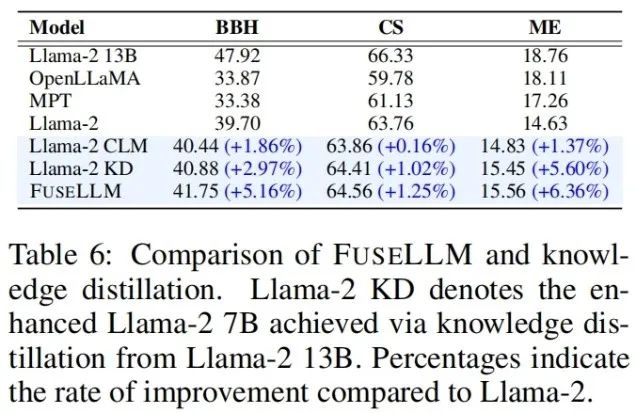
考虑到知识蒸馏也是一种利用表征提升大语言模型性能的方法,作者将FuseLLM 和用Llama- 2 13B 蒸馏的Llama-2 KD 进行了比较。结果表明,FuseLLM 通过融合三个具有不同架构的 7B 模型,超过了从单个 13B 模型蒸馏的效果。

为了将FuseLLM 与现有融合方法进行比较(例如模型集成和权重合并),作者模拟了多个源模型来自相同结构的底座模型,但在不同的语料库上持续训练的场景,并测试了各种方法在不同测试基准上的困惑度。可以看到虽然所有的融合技术都可以结合多个源模型的优势,但 FuseLLM 能达到最低的平均困惑度,表明 FuseLLM 具备能比模型集成和权重合并方法更有效地结合源模型集体知识的潜力。
最后,尽管社区目前已经关注大模型的融合,但目前的做法大多基于权重合并,无法扩展到不同结构、不同规模的模型融合场景。虽然FuseLLM 只是一项初步的异构模型融合研究,但考虑到目前技术社区存在大量不同的结构和规模的语言、视觉、音频和多模态大模型,未来这些异构模型的融合会迸发出怎样惊人地表现呢?让我们拭目以待!
以上是多个异构大模型的融合带来惊人效果的详细内容。更多信息请关注PHP中文网其他相关文章!