
优化SQL效率的研究

- 王林转载
- 2024-01-28 08:09:051146浏览
这是2016年8月份上海MOORACLE大会上陈宏义老师(老K)分享的一个案例,将一个merge SQL,通过改写成plsql的方式,大大提高了执行效率。 老虎刘在看到这个案例的时候,开始没有注意到执行计划里面显示的各表实际记录数,不认为plsql的改写方式比分析函数的写法更高效,还与陈老师有过几次邮件讨论,直到后来仔细查看了执行计划。
原SQL如下:merge into t_customer c using
(
select a.cstno, a.amount from t_trade a,
(select cstno,max(trade_date) trade_date from t_trade
group by cstno) b
where a.cstno = b.cstno and a.trade_date=b.trade_date
) m
on(c.cstno = m.cstno)
when matched then
update set c.amount = m.amount;
这个SQL是将用户交易明细表(t_trade )的最近的一笔消费额,更新到用户信息表(t_customer)的消费额字段,使用的是merge操作。
执行计划:

老虎刘注:
在没有掌握分析函数的写法前,SQL的红色部分是group by后取其他字段信息的一个较为常见的写法,也是这个SQL执行效率差的根本原因。
原SQL还有一个隐患,就是如果t_trade的某个cstno对应的最大trade_date有重复,那么这个SQL会报ORA-30926 错误无法执行。
如果不仔细看执行计划(两表的真实数据量信息),这种SQL的惯用优化方法是使用分析函数改写:
改写方法1:merge into t_customer c using
(
select a.cstno,a.amount from
(select trade_date,cstno,amount,
row_number()over(partition by cstno order by trade_date desc) RNO from t_trade)a
where RNO=1
) m
on(c.cstno = m.cstno)
when matched then
update set c.amount = m.amount;
这种改写方法会比原SQL效率提高很多,而且不存在某个cstno对应的max trade_date 重复时报错的问题。
但是陈老师没有使用分析函数的改写方法,而是根据两表数据量相差较大的特点,将SQL改写成一段更为高效的plsql:
改写方法2:declare
vamount number;
begin
for v in (select * from t_customer )
loop
select amount into vamount from
(select amount from t_trade where cstno=v.cstno order by trade_date desc)
where rownum
update t_customer set amount = vamount where cstno=v.cstno;
end loop
commit;
end;
/
根据原SQL的执行计划我们知道,t_customer表的记录数比较少,只有1000多条,而t_trade表有1000万条,比例为1:10000(不知道这是真实数据还是测试数据,只有1000多个用户,而且一个用户平均1万个消费明细,看起来不像真实数据)。
在这样一个两表数据相差较大的特殊情况下,plsql写法确实是比分析函数的写法要高效。这个改写非常巧妙。
我们再来分析一下这两种改写的优缺点:1、plsql的改写方式,适合在t_customer表比较小,而且t_customer 和 t_trade 两表的记录数比例比较大的情况下,执行效率才会比分析函数的改写高一些。在本例中,如果t_customer表的记录数是10万,那么分析函数的写法反而要比plsql的写法快上几十到上百倍。
3、plsql这种改写的前提是必须存在t_trade表cstno + trade_date 两字段的联合索引。而分析函数的改写就不需要任何索引的支持。
4、对于t_trade这种千万记录级别的表,使用分析函数的写法可以通过开启并行来提速;plsql的改写,如果要提高效率,需要先将t_customer表按cstno分组,用多个session并发执行。
我们再来看看,陈老师的这段plsql,是不是可以用单个sql来实现,我做了一个尝试,SQL代码如下:
merge into t_customer c using
(
select tc.cstno,
(select amount
from t_trade td1
where td1.cstno=tc.cstno and td1.trade_date = (select max(trade_date) from t_trade td2 where tc.cstno = td2.cstno) and rownum=1 ) as amount
from t_customer tc
) m
on(c.cstno = m.cstno)
when matched then
update set c.amount = m.amount;
执行计划大致如下:
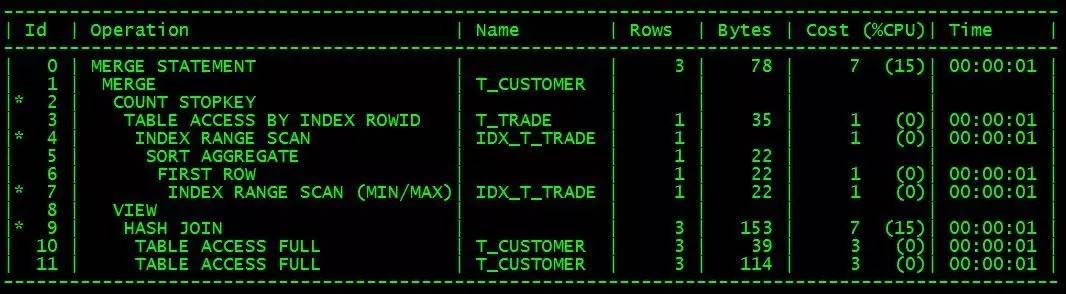
这种写法也是需要t_trade表存在cstno+trade_date 联合索引(IDX_T_TRADE),而且T_customer 表的数据量远低于T_trade。
根据执行计划,这个sql的执行效率应该比plsql写法的效率不相上下。
总结:SQL优化,除了要避免低效的SQL写法,主要还是要看表的数据量与数据分布情况,plsql的改写方法,在少数比较特殊的情况下会体现出较高的效率,在某些数据分布的情况下,效率可能还不如原SQL。但是,优化思路非常值得借鉴。
而分析函数的改写方式,则不论数据如何分布,都会比原SQL要高效,通用性更强。
对于本例改写前的SQL,应该还有很多开发人员和DBA在使用,在了解了分析函数的使用方法后,原SQL的低效写法就应该被彻底抛弃了。
最后的plsql改写成单SQL,逻辑看起来比较复杂难懂,一般不会用到这样的改写,大家了解一下就好了。
还是那句话,优化无定式,优化器是死的,人脑是活的,只有掌握了原理,才能让SQL执行效率越来越高。
以上是优化SQL效率的研究的详细内容。更多信息请关注PHP中文网其他相关文章!