


近日,作为美国前十的科技博客,Latent Space对于刚刚过去的NeurIPS 2023大会进行了精选回顾总结。
在NeurIPS会议中,共有3586篇论文被接受,其中6篇获奖。虽然这些获奖论文备受关注,但其他论文同样具备出色的质量和潜力。实际上,这些论文甚至可能预示着AI领域的下一个重大突破。
那就让我们来一起看看吧!

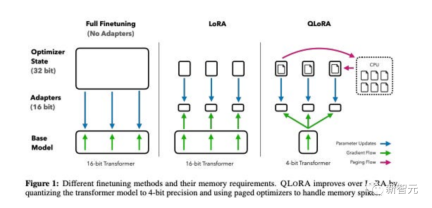
论文题目:QLoRA: Efficient Finetuning of Quantized LLMs

论文地址:https://openreview.net/pdf?id=OUIFPHEgJU
这篇论文提出了QLoRA,这是LoRA的一种更省内存但速度较慢的版本,它使用了几种优化技巧来节省内存。
总体而言,QLoRA使得在对大型语言模型进行微调时可以使用更少的GPU内存。
他们对一个新模型进行了微调,命名为Guanaco,仅用一个GPU进行了为期24小时的训练,结果在Vicuna基准测试中表现优于之前的模型。
与此同时,研究人员还开发了其他方法,如4-bit LoRA量化,其效果相似。
论文题目:DataComp: In search of the next generation of multimodal datasets

论文地址:https://openreview.net/pdf?id=dVaWCDMBof
多模态数据集在最近的突破中扮演着关键角色,如CLIP、Stable Diffusion和GPT-4,但与模型架构或训练算法相比,它们的设计并没有得到同等的研究关注。
为了解决这一机器学习生态系统中的不足,研究人员引入了DataComp,这是一个围绕Common Crawl的新候选池中的128亿个图文对进行数据集实验的测试平台。
使用者可以通过DataComp进行实验,设计新的过滤技术或精心策划新的数据源,并通过运行标准化的CLIP训练代码,以及在38个下游测试集上测试生成的模型,来评估他们的新数据集。
结果显示,最佳基准DataComp-1B,允许从头开始训练一个CLIP ViT-L/14模型,其在ImageNet上的零样本准确度达到了79.2%,比OpenAI的CLIP ViT-L/14模型高出3.7个百分点,以此证明DataComp工作流程可以产生更好的训练集。
论文题目:Visual Instruction Tuning

论文地址:https://www.php.cn/link/c0db7643410e1a667d5e01868827a9af
在这篇论文中,研究人员提出了首次尝试使用仅依赖语言的GPT-4生成多模态语言-图像指令跟随数据的方法。
通过在这种生成的数据上进行指令调整,引入了LLaVA:Large Language and Vision Assistant,这是一个端到端训练的大型多模态模型,连接了一个视觉编码器和LLM,用于通用的视觉和语言理解。
早期实验证明LLaVA展示了令人印象深刻的多模态聊天能力,有时展现出多模态GPT-4在未见过的图像/指令上的行为,并在合成的多模态指令跟随数据集上与GPT-4相比取得了85.1%的相对分数。
在对科学问答进行微调时,LLaVA和GPT-4的协同作用实现了92.53%的新的最先进准确性。

论文题目:Tree of Thoughts: Deliberate Problem Solving with Large Language Models

论文地址:https://arxiv.org/pdf/2305.10601.pdf
语言模型越来越多地被用于广泛的任务中进行一般性问题解决,但在推理过程中仍受限于标记级别、从左到右的决策过程。这意味着它们在需要探索、战略前瞻或初始决策起关键作用的任务中可能表现不佳。
为了克服这些挑战,研究人员引入了一种新的语言模型推理框架,Tree of Thoughts(ToT),它在促使语言模型方面推广了流行的Chain of Thought方法,并允许在一致的文本单元(思想)上进行探索,这些单元作为解决问题的中间步骤。
ToT使语言模型能够通过考虑多条不同的推理路径和自我评估选择来做出刻意的决策,以决定下一步行动,并在必要时展望或回溯以做出全局性的选择。
实验证明,ToT显著提高了语言模型在需要非平凡规划或搜索的三个新任务上的问题解决能力:24点游戏、创意写作和迷你填字游戏。例如,在24点游戏中,虽然使用Chain of Thought提示的GPT-4只解决了4%的任务,但ToT实现了74%的成功率。
论文题目:Toolformer: Language Models Can Teach Themselves to Use Tools

论文地址:https://arxiv.org/pdf/2302.04761.pdf
语言模型表现出在从少量示例或文本指令中解决新任务方面的显著能力,尤其是在大规模情境下。然而,令人矛盾的是,它们在基本功能方面(如算术或事实查找),相较于更简单且规模较小的专门模型,却表现出困难。
在这篇论文中,研究人员展示了语言模型可以通过简单的API自学使用外部工具,并实现两者的最佳结合。
他们引入了Toolformer,这个模型经过训练能够决定调用哪些API、何时调用它们、传递什么参数以及如何最佳地将结果合并到未来的token预测中。
这是以自监督的方式完成的,每个API只需要少量演示即可。他们整合了各种工具,包括计算器、问答系统、搜索引擎、翻译系统和日历等。
Toolformer在与更大模型竞争的时候,在各种下游任务中取得了明显改善的零样本性能,而不会牺牲其核心语言建模能力。
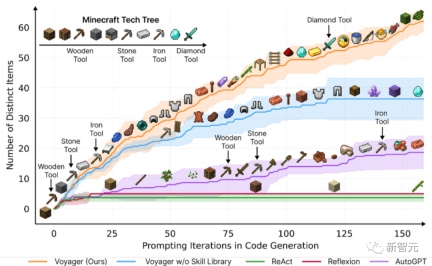
论文题目:Voyager: An Open-Ended Embodied Agent with Large Language Models

论文地址:https://arxiv.org/pdf/2305.16291.pdf
该论文介绍了Voyager,这是第一个由大型语言模型(LLM)驱动的,可以在Minecraft中连续探索世界、获取多样化技能并进行独立发现的learning agent。
Voyager包含三个关键组成部分:
自动课程,旨在最大程度地推动探索,
不断增长的可执行代码技能库,用于存储和检索复杂行为,
新的迭代提示机制,整合了环境反馈、执行错误和自我验证以改进程序。
Voyager通过黑盒查询与GPT-4进行交互,避免了对模型参数进行微调的需求。
根据实证研究,Voyager展现出强大的环境上下文中的终身学习能力,并在玩Minecraft方面表现出卓越的熟练度。
它获得了比先前技术水平高出3.3倍的独特物品,行进距离更长2.3倍,并且解锁关键技术树里程碑的速度比先前技术水平快15.3倍。
不过,虽然Voyager能够在新的Minecraft世界中利用学到的技能库从零开始解决新颖任务,但其他技术则难以泛化。
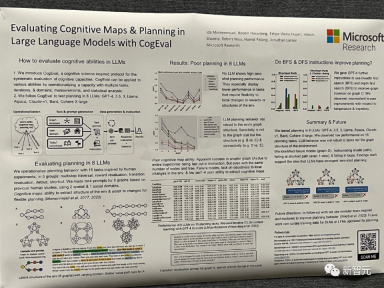
论文题目:Evaluating Cognitive Maps and Planning in Large Language Models with CogEval

论文地址:https://openreview.net/pdf?id=VtkGvGcGe3
该论文首先提出了CogEval,这是一个受认知科学启发的系统评估大型语言模型认知能力的协议。
其次,论文使用CogEval系统评估了八个LLMs(OpenAI GPT-4、GPT-3.5-turbo-175B、davinci-003-175B、Google Bard、Cohere-xlarge-52.4B、Anthropic Claude-1-52B、LLaMA-13B和Alpaca-7B)的认知地图和规划能力。任务提示基于人类实验,并且不在LLM训练集中存在。
研究发现,虽然LLMs在一些结构较简单的规划任务中显示出明显的能力,但一旦任务变得复杂,LLMs就会陷入盲区,包括对无效轨迹的幻觉和陷入循环。
这些发现不支持LLMs具有即插即用的规划能力的观点。可能是因为LLMs不理解规划问题背后的潜在关系结构,即认知地图,并在根据基础结构展开目标导向轨迹时出现问题。
论文题目:Mamba: Linear-Time Sequence Modeling with Selective State Spaces

论文地址:https://openreview.net/pdf?id=AL1fq05o7H
作者指出了目前许多次线性时间架构,如线性注意力、门控卷积和循环模型,以及结构化状态空间模型(SSMs),旨在解决Transformer在处理长序列时的计算效率低下问题。然而,这些模型在重要的语言等领域上并没有像注意力模型那样表现出色。作者认为这些
型的一个关键弱点是它们无法进行基于内容的推理,并进行了一些改进。
首先,简单地让 SSM 参数作为输入的函数,可以解决其离散模态的弱点,允许模型根据当前标记选择性地沿序列长度维度传播或忘记信息。
其次,尽管这种变化阻止了高效卷积的使用,但作者在循环模式下设计了一种硬件感知的并行算法。将这些选择性 SSM 集成到简化的端到端神经网络架构中,无需注意力机制,甚至不需要 MLP 模块 (Mamba)。
Mamba在推理速度上表现出色(比Transformers高5倍),并且在序列长度上呈线性缩放,在真实数据上的性能提高了,达到了百万长度序列。
作为一种通用的序列模型骨干,Mamba在语言、音频和基因组学等多个领域取得了最先进的性能。在语言建模方面,Mamba-1.4B模型在预训练和下游评估中均优于相同大小的Transformers模型,与其两倍大小的Transformers模型相匹敌。

虽然这些论文在2023年没有获得奖项,但比如Mamba,作为一种能够革新语言模型架构的技术模型,评估其影响还为时过早。
明年NeurIPS会如何走向,2024的人工智能和神经信息系统领域又会如何发展,虽然目前众说纷纭,但又有谁能打包票呢?让我们拭目以待。
以上是回顾NeurIPS 2023: 清华ToT推动大型模型成为焦点的详细内容。更多信息请关注PHP中文网其他相关文章!

 解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM
解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM译者 | 布加迪审校 | 孙淑娟目前,没有用于构建和管理机器学习(ML)应用程序的标准实践。机器学习项目组织得不好,缺乏可重复性,而且从长远来看容易彻底失败。因此,我们需要一套流程来帮助自己在整个机器学习生命周期中保持质量、可持续性、稳健性和成本管理。图1. 机器学习开发生命周期流程使用质量保证方法开发机器学习应用程序的跨行业标准流程(CRISP-ML(Q))是CRISP-DM的升级版,以确保机器学习产品的质量。CRISP-ML(Q)有六个单独的阶段:1. 业务和数据理解2. 数据准备3. 模型
 人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM
人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM人工智能(AI)在流行文化和政治分析中经常以两种极端的形式出现。它要么代表着人类智慧与科技实力相结合的未来主义乌托邦的关键,要么是迈向反乌托邦式机器崛起的第一步。学者、企业家、甚至活动家在应用人工智能应对气候变化时都采用了同样的二元思维。科技行业对人工智能在创建一个新的技术乌托邦中所扮演的角色的单一关注,掩盖了人工智能可能加剧环境退化的方式,通常是直接伤害边缘人群的方式。为了在应对气候变化的过程中充分利用人工智能技术,同时承认其大量消耗能源,引领人工智能潮流的科技公司需要探索人工智能对环境影响的
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM
条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM条形统计图用“直条”呈现数据。条形统计图是用一个单位长度表示一定的数量,根据数量的多少画成长短不同的直条,然后把这些直条按一定的顺序排列起来;从条形统计图中很容易看出各种数量的多少。条形统计图分为:单式条形统计图和复式条形统计图,前者只表示1个项目的数据,后者可以同时表示多个项目的数据。
 自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PM
自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PMarXiv论文“Sim-to-Real Domain Adaptation for Lane Detection and Classification in Autonomous Driving“,2022年5月,加拿大滑铁卢大学的工作。虽然自主驾驶的监督检测和分类框架需要大型标注数据集,但光照真实模拟环境生成的合成数据推动的无监督域适应(UDA,Unsupervised Domain Adaptation)方法则是低成本、耗时更少的解决方案。本文提出对抗性鉴别和生成(adversarial d
 数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM
数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM数据通信中的信道传输速率单位是bps,它表示“位/秒”或“比特/秒”,即数据传输速率在数值上等于每秒钟传输构成数据代码的二进制比特数,也称“比特率”。比特率表示单位时间内传送比特的数目,用于衡量数字信息的传送速度;根据每帧图像存储时所占的比特数和传输比特率,可以计算数字图像信息传输的速度。
 数据分析方法有哪几种Dec 15, 2020 am 09:48 AM
数据分析方法有哪几种Dec 15, 2020 am 09:48 AM数据分析方法有4种,分别是:1、趋势分析,趋势分析一般用于核心指标的长期跟踪;2、象限分析,可依据数据的不同,将各个比较主体划分到四个象限中;3、对比分析,分为横向对比和纵向对比;4、交叉分析,主要作用就是从多个维度细分数据。
 聊一聊Python 实现数据的序列化操作Apr 12, 2023 am 09:31 AM
聊一聊Python 实现数据的序列化操作Apr 12, 2023 am 09:31 AM在日常开发中,对数据进行序列化和反序列化是常见的数据操作,Python提供了两个模块方便开发者实现数据的序列化操作,即 json 模块和 pickle 模块。这两个模块主要区别如下:json 是一个文本序列化格式,而 pickle 是一个二进制序列化格式;json 是我们可以直观阅读的,而 pickle 不可以;json 是可互操作的,在 Python 系统之外广泛使用,而 pickle 则是 Python 专用的;默认情况下,json 只能表示 Python 内置类型的子集,不能表示自定义的


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SublimeText3汉化版
中文版,非常好用

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

