


最近遇到业务的一个类似文件系统的存储需求,对于如何在mysql中存储一颗树进行了一些讨论,分享一下,看看有没有更优的解决方案。
一、现有情况
首先,先假设有这么一颗树,一共9个节点,1是root节点,一共深3层。(当然实际业务不会这么简单)

原有的表结构如下:
| id | parents_id | name | full_path |
| 1 | 0 | a | /a |
| 2 | 1 | b | /a/b |
| 3 | 1 | c | /a/c |
| 4 | 1 | d | /a/d |
| 5 | 4 | e | /a/d/e |
| 6 | 4 | f | /a/d/f |
| 7 | 5 | g | /a/d/e/g |
| 8 | 5 | h | /a/d/e/h |
| 9 | 5 | i | /a/d/e/i |
需要满足的几个基本需求为:
1、从上到下逐层展开目录层级
2、知道某一个目录反查其全路径
3、rename某一个路径的名字
4、将某一个目录挪到其他目录下
现有的表结构可以满足以上的需求:
1、select id from table where parents_id=$id;(可以查出所有直接子节点)2、select full_path from table where id=$id;(通过全路径字段获取)3、update table set name=$newname where id=$id;(将需要修改的id的name字段修改)4、update table set parents_id=$new_parents_id,full_path=$new_full_path where id=$id;(修改父子关系到新的关系上)
但是现有的表结构会遇到的问题就是,第3和第4个需求,其并不是只更新一行即可,由于有full_path的存在,所有被修改的节点,其下面的所有节点的full_path都需要修改。这就无形之间增加了很多写操作,如果这颗树比较深,比如有100层,那么修改第3层的数据,那么就意味着其下面97层的所有数据都需要被修改,这个产生的写操作就有些恐怖了。
以列子所示,如果4的name被修改,都会影响4,5,6,7,8,9一共6行数据的更新,这个写逻辑放大的有点厉害。
update table set name=x,full_path='/a/x' where id=4;update table set full_path='/a/x/e' where id=5;update table set full_path='/a/x/f' where id=6;update table set full_path='/a/x/e/g' where id=7;update table set full_path='/a/x/e/h' where id=8;update table set full_path='/a/x/e/i' where id=9;
那么如何解决这个问题呢?
二、优化方案
1、去除full_path字段
上面所述问题最严重的就是写逻辑放大的问题,采用去除full_path字段后,6条update就变成1条update的了。
这个优化看起来完美解决写逻辑放大问题,但是引入了另一个问题,那就是需求2的满足费劲了。
原有SQL是:
select full_path from table where id=$id;
但是去除full_path字段之后,变为:
select parents_id from table where id =$id;select parents_id from table where id = $parents_id;
以示例来说,如果要得到9的全路径,那么就需要如下SQL
select parents_id,name from table where id = 9;select parents_id,name from table where id = 5;select parents_id,name from table where id = 4;select parents_id,name from table where id = 1;
当最后判断到parents_id=0的时候结束,然后将所有name聚合在一起。
如果所有操作都需要前端实现,那么就需要前端和DB交互4次,这期间消耗的链接成本会极大的延长总体的响应时间,基本是不可接收的。
如果要采用这种方案,目前看来只有使用存储过程,将所有计算都在本地完成之后在返回给端,保证一次请求,一次返回,这样才最效率,但是mysql的存储过程个人不太建议使用,风险较大。
2、产品规范
我们的问题会发生在树的层级特别多的情况下,那么可以通过产品规范来进行限制,比如最深只能有4层,这样就将问题遏制在发生之前了。(当然,有些时候这种最有效的优化方案是最不可能实现的,产品不会那么容易妥协)
3、增加cache
问题既然是写逻辑放大,那么如果我们将优化思路从降低写入次数,改为提高写入性能呢?
我们引入redis这种nosql存储,将id和full_path存放在redis中,每次更新数据库之后在更新redis,redis的写入性能远高于mysql,这样问题也可以得到解决。
只不过由于更新不是同步的,采用异步更新之后,数据会最终一致,但是在某一个特殊时间点可能会存在不一致。
并且由于存储架构变化,需要代码方面做出一定的妥协,无论是读操作还是写操作。
4、整体改变存储结构
以上方案都是在不大改现有表结构的基础上做出的,那么有没有可能修改表结构之后情况会不一样呢?
我们对所示例子的存储结构引入层级的概念,去除full_path,看看是否可以解决问题。
新的表结构如下:
id_name(id和name映射关系)
| id | name |
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
| 6 | f |
| 7 | g |
| 8 | h |
| 9 | i |
relation(父子关系)
| id | chailds | depth |
| 1 | 1 | 0 |
| 1 | 2 | 1 |
| 1 | 3 | 1 |
| 1 | 4 | 1 |
| 1 | 5 | 2 |
| 1 | 6 | 2 |
| 1 | 7 | 3 |
| 1 | 8 | 3 |
| 1 | 9 | 3 |
| 2 | 2 | 0 |
| 3 | 3 | 0 |
| 4 | 4 | 0 |
| 4 | 5 | 1 |
| 4 | 7 | 2 |
| 4 | 8 | 2 |
| 4 | 9 | 2 |
| 5 | 5 | 0 |
| 5 | 7 | 1 |
| 5 | 8 | 1 |
| 5 | 9 | 1 |
| 6 | 6 | 0 |
| 7 | 7 | 0 |
| 8 | 8 | 0 |
| 9 | 9 | 0 |
这两张新表第一张不用解释了,第二张id字段存放节点id,chailds字段存放其所有子节点(并不是直接chaild,而是不论层级都存放),depth字段存放其子节点和本节点的层级关系。
我们看下这么设计是否可以满足最初的4个需求:
需求1:逐层展开目录
select id,depth from table2 where id=$id;select name from table1 where id=$id;
由于每个id都存放了其所有的子节点,所以如果查询4的所有下属目录,直接select id,depth from table2 where id = 4;一条SQL即可获得所有结果,只要前端在处理一下即可。
| id | chailds | depth |
| 4 | 4 | 0 |
| 4 | 5 | 1 |
| 4 | 6 | 1 |
| 4 | 7 | 2 |
| 4 | 8 | 2 |
| 4 | 9 | 2 |
需求2:根据某一个目录获知其全路径
select id,depth from table2 where chailds = $id;
由于每个id都存放了所有子节点,所以反差也是一条sql的事情。比如查询9的全路径,那么select id,depth from table2 where chailds=9;得到的结果应该是
| id | chailds | depth |
| 9 | 9 | 0 |
| 5 | 9 | 1 |
| 4 | 9 | 2 |
| 1 | 9 | 3 |
通过上述结果,前端进行计算处理就可以得到9的全路径了,并且是一条sql获得,不需要前端和db多次交互,也不需要引入存储过程。
需求3:更改目录名称
update table1 set name = $new_name where id = $id ;
这个最简单了,只需要更改映射表即可。
需求4:更改节点的父子关系
select id from table2 where id=$id and depth > 0;delete from table2 where id = $sql1_id;select id from table2 where id = $new_father_id;inset into table2 values ($sql2_id,$id,$depth+1);
这个需求目前看来最麻烦,我们以示例所示,如果将5挪到3下面需要经过哪些操作?
I:先查出来5都属于哪些节点的子节点。
select id from table 2 where id=5 and depth > 0;
id |
chailds | depth |
| 1 | 5 | 2 |
| 4 | 5 | 1 |
II:删除这些记录。
delete from table2 where id=1 and chailds=5;
delete from table2 where id=4 and chailds=5;
III:查出新父节点是哪些节点的子节点。
select id,depth from table where chailds=3 and depth > 0 ;
| id | chailds | depth |
| 1 | 3 | 1 |
IIII:
根据III的结果插入新的关系。
insert into table2 values (1,5,2);
由于新父节点只是1的子节点,故只需要在增加5和1个关系既可,同时由于3是5的新父节点,那么5和1的深度关系应该比3的关系“+1”。
而所有5下面的节点都不需要更改,因为这么设计所有节点都是自己子节点的root,所以只要修改5的关系即可。
但是这个解决方案明显可以看出来,需要存储的关系比原有情况多了很多倍,尤其是关系层级深的情况下。
三、总结
方案1:解决写逻辑放大问题,但是引入了读逻辑放大问题,并需要引入存储过程解决。
方案2:产品规范解决,最彻底的解决方法,但需要和PM沟通确认,业务很难妥协。
方案3:引入cache解决写入性能,但是需要代码进行修改,并存在数据不一致的风险。
方案4:解决写逻辑放大问题,也没有引入读逻辑放大问题,仅仅只是在更改目录的时候稍微麻烦一些,但是引入了初始存储容量暴增的问题。
目前看来,并没有什么特别优秀的方案,都需要付出一定的代价。
ps:本文的思路参考了《SQL反模式》,如果有兴趣的读者可以去研读一下。

 修复:Sysprep 无法验证 Windows 11 安装May 19, 2023 am 10:15 AM
修复:Sysprep 无法验证 Windows 11 安装May 19, 2023 am 10:15 AMSysprep问题可能出现在Windows11、10和8平台上。出现该问题时,Sysprep命令不会按预期运行和验证安装。如果您需要修复Sysprep问题,请查看下面的Windows11/10解决方案。Sysprep错误是如何在Windows中出现的?Sysprep无法验证您的Windows安装错误自Windows8以来一直存在。该问题通常是由于用户安装的UWP应用程序而出现的。许多用户已确认他们通过卸载从MSStore安装的某些UWP应用程序解决了此问题。如果缺少应该与Windows一起预安装
 重置管理员权限: 如何重新获得管理员权限?Apr 23, 2023 pm 10:10 PM
重置管理员权限: 如何重新获得管理员权限?Apr 23, 2023 pm 10:10 PM您将找到多个用户报告,确认NETHELPMSG2221错误代码。当您的帐户不再是管理员时,就会显示此信息。根据用户的说法,他们的帐户自动被撤销了管理员权限。如果您也遇到此问题,我们建议您应用指南中的解决方案并修复NETHELPMSG2221错误。您可以通过多种方式将管理员权限恢复到您的帐户。让我们直接进入它们。什么是NETHELPMSG2221错误?当您不是PC的管理员时,无法使用提升的程序。因此,例如,你将无法在电脑上运行命令提示符、WindowsPowerShell或任
 如何解决Windows更新错误代码0x8024800c?Apr 21, 2023 am 09:55 AM
如何解决Windows更新错误代码0x8024800c?Apr 21, 2023 am 09:55 AM什么原因导致WindowsUpdate错误0x8024800c?导致WindowsUpdate错误的原因0x8024800c尚不完全清楚。但是,此问题可能与其他更新错误具有类似的原因。以下是一些潜在的0x8024800c错误原因:损坏的系统文件–某些系统文件需要修复。不同步的软件分发缓存–软件分发数据存储不同步,这意味着此错误是超时问题(它有一个WU_E_DS_LOCKTIMEOUTEXPIRED结果字符串)。损坏的WindowsUpdate组件-错误0x8024800c是由错误的Win
 如何解决您的 Office 许可证有问题May 20, 2023 pm 02:08 PM
如何解决您的 Office 许可证有问题May 20, 2023 pm 02:08 PMMSOffice产品是任何Windows系统上用于创建Word、Excel表格等文档的应用程序的绝佳选择。但是您需要从Microsoft购买Office产品的有效许可证,并且必须激活它才能使其有效工作.最近,许多Windows用户报告说,每当他们启动任何Office产品(如Word、Excel等)时,他们都会收到一条警告消息,上面写着“您的Office许可证存在问题,并要求用户获取正版Office许可证”。一些用户不假思索,就去微软购买了Office产品的许可证
 WWAHost.exe 进程高磁盘、CPU 或内存使用修复Apr 14, 2023 pm 04:43 PM
WWAHost.exe 进程高磁盘、CPU 或内存使用修复Apr 14, 2023 pm 04:43 PM许多用户在系统变慢时报告任务管理器中存在WWAHost.exe进程。WWAHost.exe进程会占用大量系统资源,例如内存、CPU或磁盘,进而降低PC的速度。因此,每当您发现您的系统与以前相比变得缓慢时,请打开任务管理器,您会在那里找到这个WWAHost.exe进程。通常,已观察到启动任何应用程序(如Mail应用程序)会启动WWAHost.exe进程,或者它可能会自行开始执行,而无需在您的WindowsPC上进行任何外部输入。此进程是安全有效的Microsoft程序,是Wi
![如何修复iPhone上的闹钟不响[已解决]](https://img.php.cn/upload/article/000/465/014/168385668827544.png) 如何修复iPhone上的闹钟不响[已解决]May 12, 2023 am 09:58 AM
如何修复iPhone上的闹钟不响[已解决]May 12, 2023 am 09:58 AM闹钟是当今大多数智能手机附带的良好功能之一。它不仅有助于让用户从睡眠中醒来,还可以用作在设定时间响铃的提醒。如今,许多iPhone用户抱怨iPhone上的闹钟无法正常响起,这给他们带来了问题。闹钟不响的潜在原因有很多,可能是因为iPhone处于静音模式,对闹钟设置进行了更改,选择低音调作为闹钟铃声,蓝牙设备已连接到iPhone等。在研究了此问题的各种原因后,我们在下面的帖子中编制了一组解决方案。初步解决方案确保iPhone未处于静音模式–当iPhone处于静音模式时,它只会使来自应用程序,通话和
 如何在iPhone上修复iTunes错误1667Apr 17, 2023 pm 09:58 PM
如何在iPhone上修复iTunes错误1667Apr 17, 2023 pm 09:58 PM大多数人作为备份实践将他们的文件从iPhone传输到PC/Mac,以防由于某些明显的原因而丢失。为此,他们必须通过避雷线将iPhone连接到PC/Mac。许多iPhone用户在尝试将iPhone连接到计算机以在它们之间同步文件时遇到错误1667。此错误背后有相当潜在的原因,可能是计算机或iPhone中的内部故障,闪电电缆损坏或损坏,用于同步文件的过时的iTunes应用程序,防病毒软件产生问题,不更新计算机的操作系统等。在这篇文章中,我们将向您解释如何使用以下给定的解决方案轻松有效地解决此错误。初
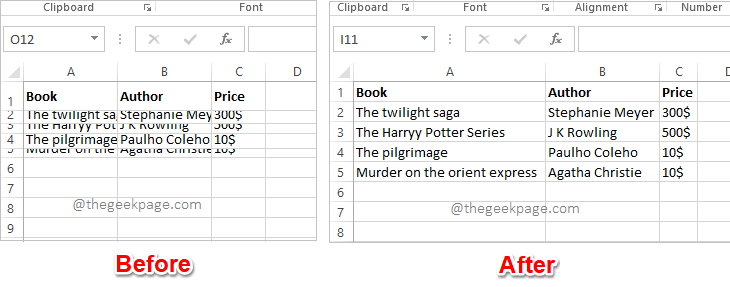 Excel中如何根据数据大小自动调整行和列May 20, 2023 pm 07:56 PM
Excel中如何根据数据大小自动调整行和列May 20, 2023 pm 07:56 PM你有一个紧迫的截止日期,你即将提交你的工作,那时你注意到你的Excel工作表不整洁。行和列的高度和宽度不同,大部分数据是重叠的,无法完美查看数据。根据内容手动调整行和列的高度和宽度确实会花费大量时间,当然不建议这样做。顺便说一句,当你可以通过一些简单的点击或按键来自动化整个事情时,你为什么还要考虑手动做呢?在本文中,我们详细解释了如何通过以下3种不同的解决方案轻松地在Excel工作表中自动调整行高或列宽。从现在开始,您可以选择自己喜欢的解决方案并成为Excel任务的高手!解决方案1:通过


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver CS6
视觉化网页开发工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

