


人工智能的反馈(AIF)要代替 RLHF 了?



论文标题:Self-Rewarding Language Models
论文链接:https://arxiv.org/abs/2401.10020


 研究者在 AlpacaEval 2 排行榜上评估了自奖励模型,结果如表 1 所示。他们观察到了与 head-to-head 评估相同的结论,即训练迭代的胜率比 GPT4-Turbo 高,从迭代 1 的 9.94%,到迭代 2 的 15.38%,再到迭代 3 的 20.44%。同时,迭代 3 模型优于许多现有模型,包括 Claude 2、Gemini Pro 和 GPT4 0613。
研究者在 AlpacaEval 2 排行榜上评估了自奖励模型,结果如表 1 所示。他们观察到了与 head-to-head 评估相同的结论,即训练迭代的胜率比 GPT4-Turbo 高,从迭代 1 的 9.94%,到迭代 2 的 15.38%,再到迭代 3 的 20.44%。同时,迭代 3 模型优于许多现有模型,包括 Claude 2、Gemini Pro 和 GPT4 0613。

EFT在SFT基线上有所改进,使用IFT+EFT与单独使用IFT相比,五个测量指标都有所提高。例如,与人类的成对准确率一致性从65.1%上升到78.7%。
通过自我训练提高奖励建模能力。进行一轮自我奖励训练后,模型为下一次迭代提供自我奖励的能力得到了提高,此外它的指令跟随能力也得到了提高。
LLMas-a-Judge 提示的重要性。研究者使用了各种提示格式发现,LLMas-a-Judge 提示在使用 SFT 基线时成对准确率更高。
以上是自我奖励下的大型模型:Llama2通过Meta学习自行优化,超越GPT-4的性能的详细内容。更多信息请关注PHP中文网其他相关文章!

 微软深化与 Meta 的 AI 及 PyTorch 合作Apr 09, 2023 pm 05:21 PM
微软深化与 Meta 的 AI 及 PyTorch 合作Apr 09, 2023 pm 05:21 PM微软宣布进一步扩展和 Meta 的 AI 合作伙伴关系,Meta 已选择 Azure 作为战略性云供应商,以帮助加速 AI 研发。在 2017 年,微软和 Meta(彼时还被称为 Facebook)共同发起了 ONNX(即 Open Neural Network Exchange),一个开放的深度学习开发工具生态系统,旨在让开发者能够在不同的 AI 框架之间移动深度学习模型。2018 年,微软宣布开源了 ONNX Runtime —— ONNX 格式模型的推理引擎。作为此次深化合作的一部分,Me
 Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型Apr 14, 2023 pm 06:58 PM
Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型Apr 14, 2023 pm 06:58 PM2月25日消息,Meta在当地时间周五宣布,它将推出一种针对研究社区的基于人工智能(AI)的新型大型语言模型,与微软、谷歌等一众受到ChatGPT刺激的公司一同加入人工智能竞赛。Meta的LLaMA是“大型语言模型MetaAI”(LargeLanguageModelMetaAI)的缩写,它可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者。该公司将提供底层代码供用户使用,因此用户可以自行调整模型,并将其用于与研究相关的用例。Meta表示,该模型对算力的要
 Meta这篇语言互译大模型研究,结果对比都是「套路」Apr 11, 2023 pm 11:46 PM
Meta这篇语言互译大模型研究,结果对比都是「套路」Apr 11, 2023 pm 11:46 PM今年 7 月初,Meta AI 发布了一个新的翻译模型,名为 No Language Left behind (NLLB),我们可以将其直译为「一个语言都不能少」。顾名思义,NLLB 可以支持 200 + 语言之间任意互译,Meta AI 还把它开源了。平时你都没见到的语言如卢干达语、乌尔都语等它都能翻译。论文地址:https://research.facebook.com/publications/no-language-left-behind/开源地址:https://github.com/
 曝光Meta Quest 3头显固件:揭示室内物体自动识别功能Sep 07, 2023 pm 01:17 PM
曝光Meta Quest 3头显固件:揭示室内物体自动识别功能Sep 07, 2023 pm 01:17 PM8月31日消息,近日有关虚拟现实领域的令人振奋消息传出,据可靠渠道透露,meta公司即将在9月27日正式发布其全新虚拟现实头显——metaQuest3。这款头显据称拥有颠覆性的深度测绘技术,将为用户带来更加逼真的混合现实体验。这项名为深度测绘的技术被认为是metaQuest3的一项重大创新。该技术使得虚拟数字物体与真实物体能够在同一空间内进行互动,大大提升了混合现实的沉浸感和真实感。一段在Reddit上流传的视频展示了深度测绘功能的惊人表现,不禁让人惊叹不已。从视频中可以看出,metaQuest
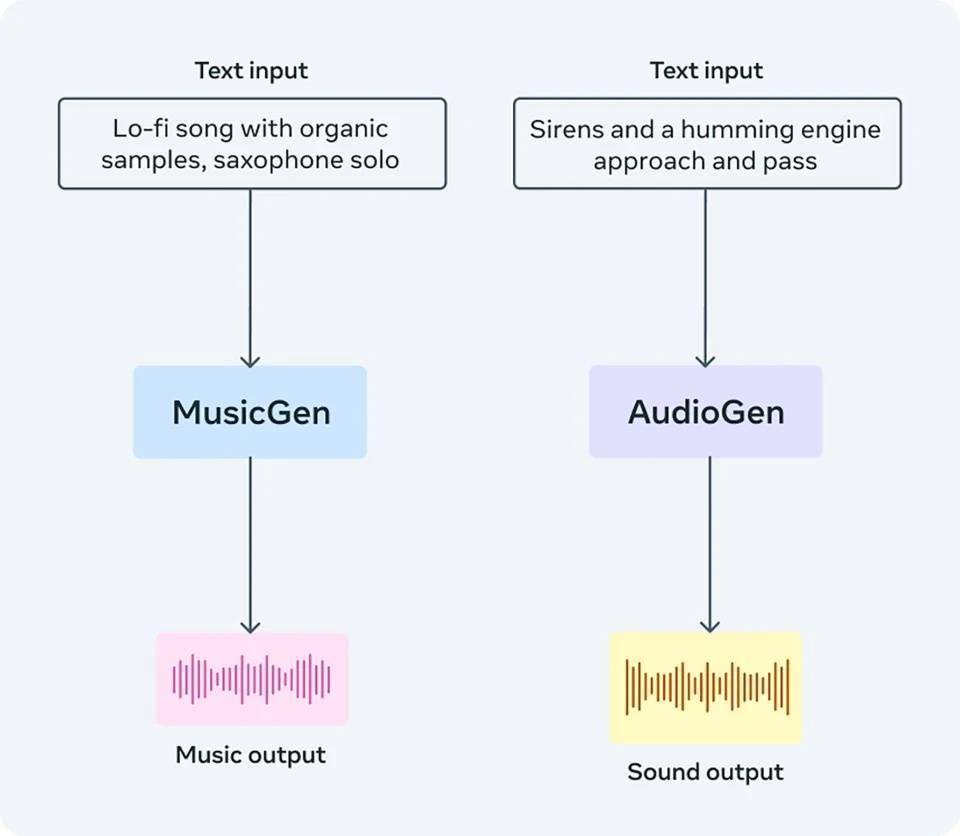 音乐制作元工具AudioCraft发布开源AI工具Aug 04, 2023 am 11:45 AM
音乐制作元工具AudioCraft发布开源AI工具Aug 04, 2023 am 11:45 AM美国东部时间8月2日,Meta发布了一款名为AudioCraft的生成式AI工具,用户可以利用文本提示来创作音乐和音频AudioCraft由三个主要组件构成:MusicGen:使用Meta拥有/特别授权的音乐进行训练,根据文本提示生成音乐。AudioGen:使用公共音效进行训练生成音频或扩展现有音频,后续还可生成环境音效(如狗叫、汽车鸣笛、木地板上的脚步声)。EnCodec(改进版):基于神经网络的音频压缩解码器,可生成更高质量的音乐并减少人工痕迹,或对音频文件进行无损压缩。官方声称,Audio
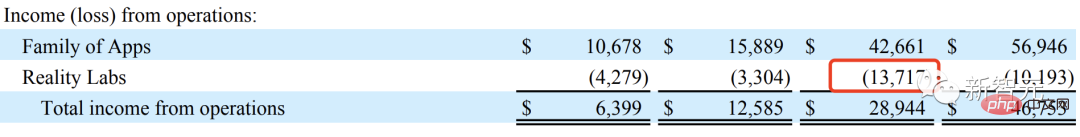 Meta推出4年硬件路线图,致力于打造「圣杯」AR眼镜,烧了137亿美元Apr 24, 2023 pm 11:04 PM
Meta推出4年硬件路线图,致力于打造「圣杯」AR眼镜,烧了137亿美元Apr 24, 2023 pm 11:04 PM现在,谁还提元宇宙?2022年,Meta实验室RealityLabs在AR/VR的研发投入已经亏损了137亿美元。比去年(近102亿美元)还要多,简直让人瞠目结舌。也看,生成式AI大爆发,一波ChatGPT狂热潮,让Meta内部重心也有所倾斜。就在前段时间,在公司的季度财报电话会议上,提及「元宇宙」的次数只有7次,而「AI」有23次。做着几乎赔本的买卖,元宇宙就这样凉凉了吗?NoNoNo!Meta近日公布了未来四年VR/AR硬件技术路线图。2025年,发布首款带有显示屏的智能眼镜,以及控制眼镜的
 抢先发布新一代VR头显,Meta想给苹果一个“下马威”?Jun 03, 2023 am 09:01 AM
抢先发布新一代VR头显,Meta想给苹果一个“下马威”?Jun 03, 2023 am 09:01 AM在游戏、元宇宙等领域的推动下,XR(扩展现实,VR/AR/MR统称)赛道的热度明显获得提升,头显设备也成了“香饽饽”,获得了许多企业的青睐,其中就有Meta(META.US)和苹果(AAPL.US)、字节跳动、索尼等巨头。而这些巨头之间的“故事”还引来了大批“吃瓜群众”。打压竞争对手?Meta赶在苹果之前发布最新版头显众所周知,在全球的大型科技企业中,Meta对元宇宙是最上心的,不惜投入巨资早早进行了布局,而VR头显被视为是元宇宙的入口之一,因此该公司在这一领域也下了大功夫,是VR头显领域的龙头
 AI 领域再添一员"猛将",Meta 发布全新大型语言模型LLaMAApr 25, 2023 pm 12:52 PM
AI 领域再添一员"猛将",Meta 发布全新大型语言模型LLaMAApr 25, 2023 pm 12:52 PMChatGTP走红以来,围绕ChatGTP开发出来的AI应用层出不穷;让人们感受到了人工智能的强大!近日,Facebook母公司Meta发布了人工智能大型语言模型(LargeLanguageModelMetaAI)简称LLaMA。扎克伯格在社交媒体上称:”由FAIR团队研发的LLaMA模型是目前世界上水平最高的大型语言模型,目标是帮助研究人员推进他们在人工智能领域的工作!“。与其他大型模型一样,MetaLLaMA的工作原理是将一系列单词作为“输入”并预测下一个单词以递归生成文本。据介


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SublimeText3 Linux新版
SublimeText3 Linux最新版

