
智能语音合成的核心原理

- 王林转载
- 2024-01-23 09:54:14733浏览
统计参数语音合成方法因其灵活性而在语音合成领域引起广泛关注。近年来,深度神经网络模型在机器学习研究领域的应用取得显着优势,与传统方法相比。基于神经网络的建模方法在统计参数语音合成中的应用逐渐深入,已成为语音合成的主流方法之一。
统计参数语音合成的后端声学建模是本文的主题。
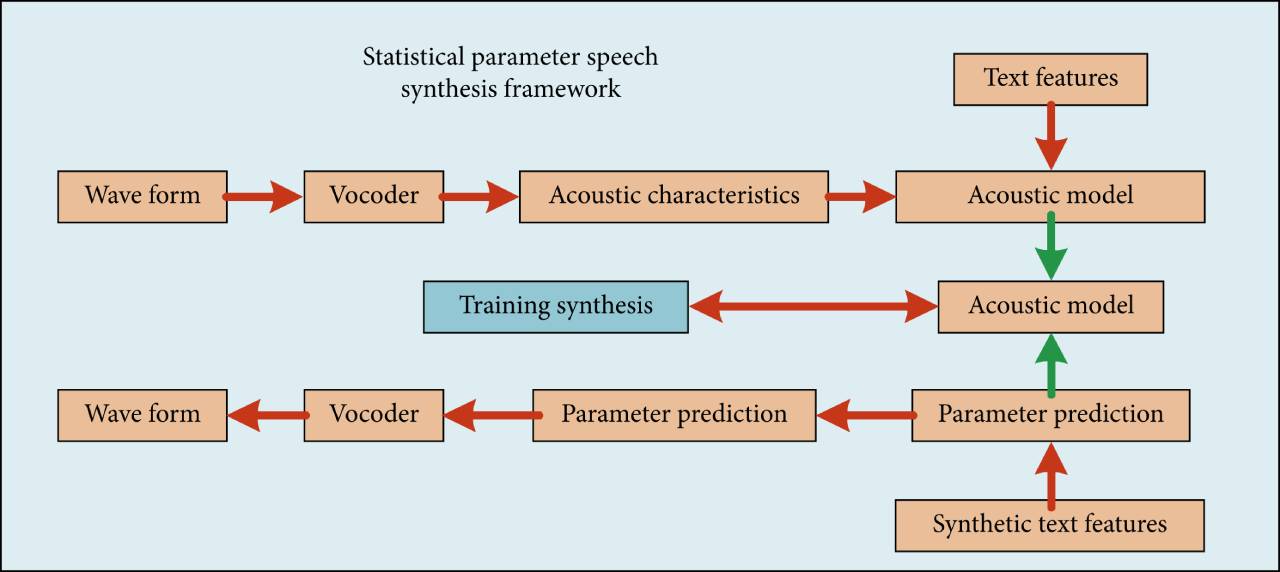
参数化语音合成的后端框架
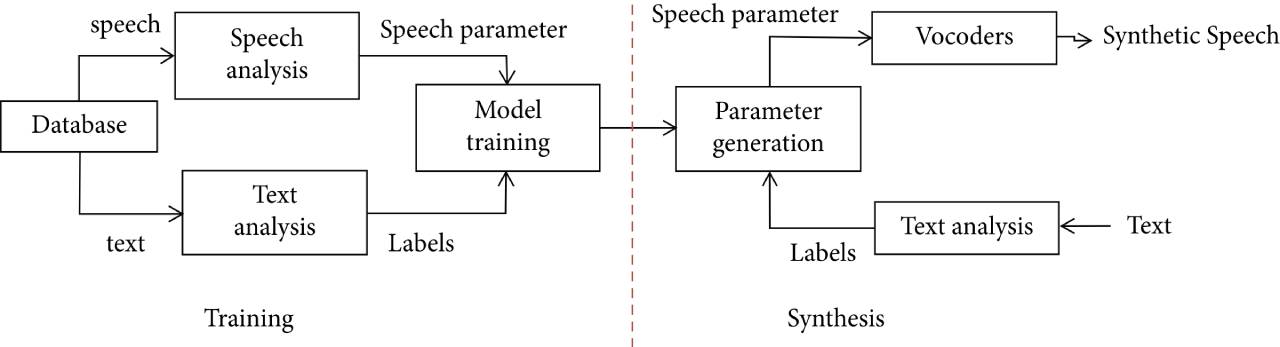
如图,描述了统计参数语音合成的后端框架,主要包括训练和合成两个阶段。
在训练阶段,使用声音库中的语音波形和相应的文本特征作为输入。通过声码器提取语音波形,并结合文本特征进行声学建模。
在合成阶段,根据已训练好的声学模型,输入待合成的文本特征,预测相应的声学特征。然后,利用声码器将预测得到的声学特征转换为语音波形。声码器和声学模型是统计参数语音合成系统中的关键组成部分。
语音产生的源滤波器模型在语音波形参数化过程中被用来将语音的短时频谱分离为基频和频谱包络。通常,我们通过分析时域波形或频域谐波来获得语音的激励特性,然后从语音波形的短时傅里叶变换得到的幅度谱中去除时间和频率的周期性,从而得到语音的频谱包络。这种方法可以帮助我们更好地理解和处理语音信号。
由于频谱包络的维数较高,建模变得困难,因此通常需要降低频谱包络的维数。重建语音波形是从语音声学参数恢复原始语音的相反过程。通过给定语音的基频、谱包络和激励特性,结合适当的相位约束,可以重构STFT幅度谱。
时长建模是统计参数语音合成中的另一个模块。时间长度建模不需要声码器。其基本框架类似于声学建模。统计模型用于在给定文本特征的条件下,对相应时间长度的概率分布进行建模。
经过20多年的发展,基于HMM的统计参数语音合成方法已经成为一种成熟的语音合成方法。
本节将介绍隐马尔可夫模型及其理论基础。结合一定的相位约束,重构 STFT 幅度谱。时长建模是统计参数语音合成中的另一个模块。时间长度建模不需要声码器。其基本框架类似于声学建模。统计模型用于在给定文本特征的条件下,对相应时间长度的概率分布进行建模。经过20多年的发展,基于HMM的统计参数语音合成方法已经成为一种成熟的语音合成方法。
隐马尔可夫模型是一种对序列建模的概率模型,它由一组隐含的状态变量组成和一组观察变量。HMM 模型有两个假设。
状态变量服从一阶马尔可夫链;即当前状态只与前一次的状态有关,如公式(1)所示。
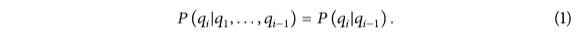
观察变量在某一时刻的概率分布只与当前时刻的状态有关,与其他时刻的状态或观察变量无关,如式(2)所示。
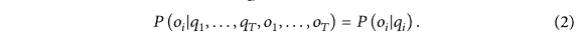
通常,在HMM模型中
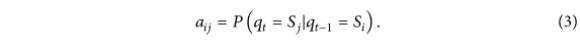
巧妙形成HMM的状态转移矩阵A,观测变量的概率密度为:
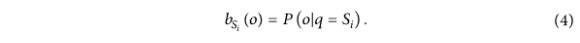
值得注意的是,HMM 的输出概率:
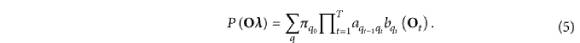
基于HMM的统计参数语音合成方法中声学建模的核心原理是利用HMM模型对给定情况下语音的声学特征序列进行概率建模。
整个系统的配置包括语音声学特征的选择、建模单元的选择以及HMM模型的配置。语音合成系统中的声学特征包括激励特征和频谱特征。
在谱特征的选择上,为了降低HMM建模的难度,一般采用去除维度间相关性的低维谱表示,如梅尔倒谱和线谱对特征。考虑到语音信号的短时平稳特性和HM的建模能力,语音合成系统中的HMM通常对音素级别的单元进行建模,例如中文中的元音单元。由于语音的时序特性,音频建模中HMM的拓扑结构往往是从左到右的单向遍历状态。
基于HMM的统计参数语音合成系统框架
如图描述了基于HMM的统计参数语音合成系统的框架。分为训练阶段和综合阶段。训练阶段包括语音声学特征提取和HMM模型训练。由于HMM模型使用音素作为建模单元,因此通常对三个上下文相关的音素进行建模以提高建模精度。
在第一个系统训练过程中,估HMM模型的方差下限,然后训练单音HMM模型作为模型初始化参数,然后训练上下文相关的三音素HMM模型,最后进行Mn压力聚类基于决策树进行。
在合成阶段,首先对文本进行分析,结合预测的时间长度,根据决策树确定上下文相关的HMM模型序列,然后通过最大似然参数生成算法得到连续的声学特征序列,语音波形由合成器合成。基于HMM的统计参数语音合成系统过于流畅;一个原因是HMM的建模能力有限。
最近几年,作为机器学习的一个分支,深度学习发展迅速。深度学习是指使用由多个非线性变换和多个处理层组成的网络模型,即神经网络。由于DNN和inch的出色建模能力n , 将基于DNN和RNN的声学建模方法应用于统计参数语音合成,其效果优于基于HMM的声学建模方法。
目前已成为统计参数语音合成声学建模的主流方法。基于DNN和RNN的语音合成系统在系统框架上类似。
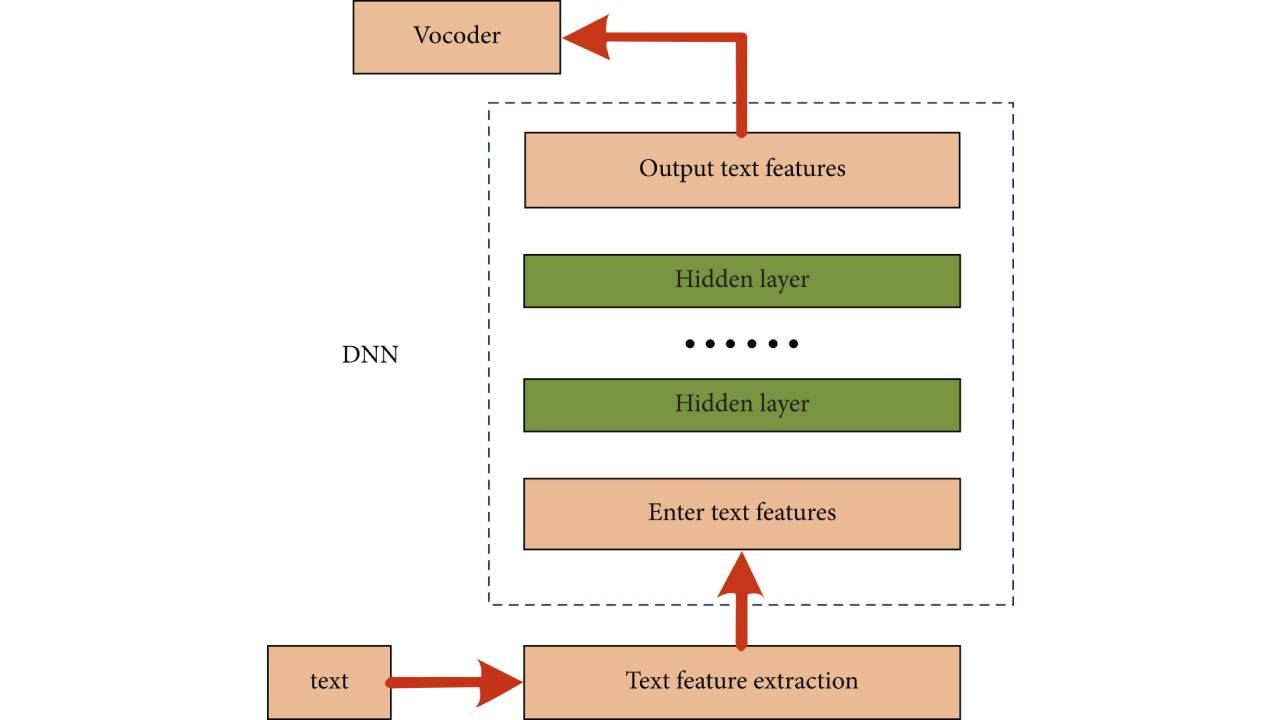
基于神经网络的语音合成方法框架图
如图,图中的输入特征是从文本中提取的特征;即用离散或连续的数值特征来描述文本。
基于DNN和RNN的统计参数语音合成系统的训练通常采用训练准则,利用BP算法和SGD算法更新模型参数,使预测的声学参数尽可能接近自然声学参数。在合成阶段,从合成文本中提取文本特征,然后通过DNN或RNN预测相应的声学参数,最后通过声码器合成语音波形。
目前,基于DNN和RNN的建模方法主要应用于语音声学参数,包括基频和频谱参数。时长信息仍需通过其他系统获取。此外,DNN和RNN模型的输入输出特征需要及时对齐。
以上是智能语音合成的核心原理的详细内容。更多信息请关注PHP中文网其他相关文章!