



Transformer在大模型领域的地位无可撼动。然而,随着模型规模的扩展和序列长度的增加,传统的Transformer架构的局限性开始凸显。幸运的是,Mamba的问世正在迅速改变这一现状。它出色的性能立即引起了AI界的轰动。Mamba的出现为大规模模型的训练和序列处理带来了巨大的突破。它的优势在AI界迅速蔓延,为未来的研究和应用带来了巨大的希望。
上周四, Vision Mamba(Vim)的提出已经展现了它成为视觉基础模型的下一代骨干的巨大潜力。仅隔一天,中国科学院、华为、鹏城实验室的研究人员提出了 VMamba:一种具有全局感受野、线性复杂度的视觉 Mamba 模型。这项工作标志着视觉 Mamba 模型 Swin 时刻的来临。

- 论文标题:VMamba: Visual State Space Model
- 论文地址: https://arxiv.org/abs/2401.10166
- 代码地址: https://github.com/MzeroMiko/VMamba
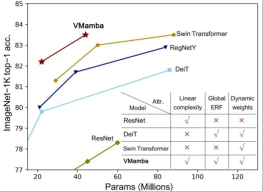
CNN 和视觉 Transformer(ViT)是当前最主流的两类基础视觉模型。尽管 CNN 具有线性复杂度,ViT 具有更为强大的数据拟合能力,然而代价是计算复杂较高。研究者认为 ViT 之所以拟合能力强,是因为其具有全局感受野和动态权重。受 Mamba 模型的启发,研究者设计出一种在线性复杂度下同时具有这两种优秀性质的模型,即 Visual State Space Model(VMamba)。大量的实验证明,VMamba 在各种视觉任务中表现卓越。如下图所示,VMamba-S 在 ImageNet-1K 上达到 83.5% 的正确率,比 Vim-S 高 3.2%,比 Swin-S 高 0.5%。
方法介绍

VMamba 的成功关键在于采用了 S6 模型,这个模型最初是为了解决自然语言处理(NLP)任务而设计的。与 ViT 的注意力机制不同,S6 模型通过将 1D 向量中的每个元素与之前的扫描信息进行交互,有效地将二次复杂度降低为线性。这种交互方式使得 VMamba 在处理大规模数据时更加高效。因此,S6 模型的引入为 VMamba 的成功打下了坚实的基础。
然而,由于视觉信号(如图像)不像文本序列那样具有天然的有序性,因此无法在视觉信号上简单地对 S6 中的数据扫描方法进行直接应用。为此研究者设计了 Cross-Scan 扫描机制。Cross-Scan 模块(CSM)采用四向扫描策略,即从特征图的四个角同时扫描(见上图)。该策略确保特征中的每个元素都以不同方向从所有其他位置整合信息,从而形成全局感受野,又不增加线性计算复杂度。

在 CSM 的基础上,作者设计了 2D-selective-scan(SS2D)模块。如上图所示,SS2D 包含了三个步骤:
- scan expand 将一个 2D 特征沿 4 个不同方向(左上、右下、左下、右上)展平为 1D 向量。
- S6 block 独立地将上步得到的 4 个 1D 向量送入 S6 操作。
- scan merge 将得到的 4 个 1D 向量融合为一个 2D 特征输出。

上图为本文提出的 VMamba 结构图。VMamba 的整体框架与主流的视觉模型类似,其主要区别在于基本模块(VSS block)中采用的算子不同。VSS block 采用了上述介绍的 2D-selective-scan 操作,即 SS2D。SS2D 保证了 VMamba 在线性复杂度的代价下实现全局感受野。
实验结果
ImageNet 分类

通过对比实验结果不难看出,在相似的参数量和 FLOPs 下:
- VMamba-T 取得了 82.2% 的性能,超过 RegNetY-4G 达 2.2%、DeiT-S 达 2.4%、Swin-T 达 0.9%。
- VMamba-S 取得了 83.5% 的性能,超过 RegNetY-8G 达 1.8%,Swin-S 达 0.5%。
- VMamba-B 取得了 83.2% 的性能(有 bug,正确结果将尽快在 Github 页面更新),比 RegNetY 高 0.3%。
这些结果远高于 Vision Mamba (Vim) 模型,充分验证了 VMamba 的潜力。
COCO 目标检测
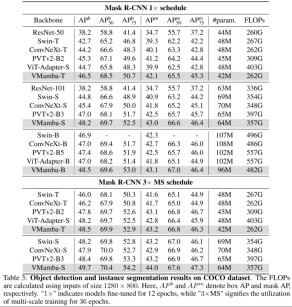
在 COOCO 数据集上,VMamba 也保持卓越性能:在 fine-tune 12 epochs 的情况下,VMamba-T/S/B 分别达到 46.5%/48.2%/48.5% mAP,超过了 Swin-T/S/B 达 3.8%/3.6%/1.6% mAP,超过 ConvNeXt-T/S/B 达 2.3%/2.8%/1.5% mAP。这些结果验证了 VMamba 在视觉下游实验中完全 work,展示出了能平替主流基础视觉模型的潜力。
ADE20K 语义分割

在 ADE20K 上,VMamba 也表现出卓越性能。VMamba-T 模型在 512 × 512 分辨率下实现 47.3% 的 mIoU,这个分数超越了所有竞争对手,包括 ResNet,DeiT,Swin 和 ConvNeXt。这种优势在 VMamba-S/B 模型下依然能够保持。
分析实验
有效感受野

VMamba 具有全局的有效感受野,其他模型中只有 DeiT 具有这个特性。但是值得注意的是,DeiT 的代价是平方级的复杂度,而 VMamaba 是线性复杂度。
输入尺度缩放
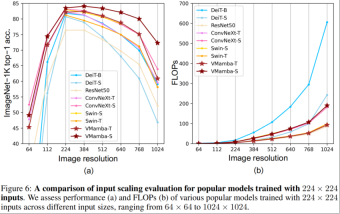
- 上图(a)显示,VMamba 在不同输入图像尺寸下展现出最稳定的性能(不微调)。有意思的是,随着输入尺寸从 224 × 224 增加到 384 × 384,只有 VMamba 表现出性能明显上升的趋势(VMamba-S 从 83.5% 上升到 84.0%),突显了其对输入图像大小变化的稳健性。
- 上图(b)显示,VMamba 系列模型随着输入变大,复杂性呈线性增长,这与 CNN 模型是一致的。
最后,让我们期待更多基于 Mamba 的视觉模型被提出,并列于 CNNs 和 ViTs,为基础视觉模型提供第三种选择。
以上是视觉Mamba模型的Swin时刻,中国科学院、华为等推出VMamba的详细内容。更多信息请关注PHP中文网其他相关文章!

 阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM
阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM斯坦福大学以人为本人工智能研究所发布的《2025年人工智能指数报告》对正在进行的人工智能革命进行了很好的概述。让我们用四个简单的概念来解读它:认知(了解正在发生的事情)、欣赏(看到好处)、接纳(面对挑战)和责任(弄清我们的责任)。 认知:人工智能无处不在,并且发展迅速 我们需要敏锐地意识到人工智能发展和传播的速度有多快。人工智能系统正在不断改进,在数学和复杂思维测试中取得了优异的成绩,而就在一年前,它们还在这些测试中惨败。想象一下,人工智能解决复杂的编码问题或研究生水平的科学问题——自2023年
 开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PMMeta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础
 AV字节:Meta' llama 3.2,Google的双子座1.5等Apr 11, 2025 pm 12:01 PM
AV字节:Meta' llama 3.2,Google的双子座1.5等Apr 11, 2025 pm 12:01 PM本周的AI景观:进步,道德考虑和监管辩论的旋风。 OpenAI,Google,Meta和Microsoft等主要参与者已经释放了一系列更新,从开创性的新车型到LE的关键转变
 与机器交谈的人类成本:聊天机器人真的可以在乎吗?Apr 11, 2025 pm 12:00 PM
与机器交谈的人类成本:聊天机器人真的可以在乎吗?Apr 11, 2025 pm 12:00 PM连接的舒适幻想:我们在与AI的关系中真的在蓬勃发展吗? 这个问题挑战了麻省理工学院媒体实验室“用AI(AHA)”研讨会的乐观语气。事件展示了加油
 了解Python的Scipy图书馆Apr 11, 2025 am 11:57 AM
了解Python的Scipy图书馆Apr 11, 2025 am 11:57 AM介绍 想象一下,您是科学家或工程师解决复杂问题 - 微分方程,优化挑战或傅立叶分析。 Python的易用性和图形功能很有吸引力,但是这些任务需要强大的工具
 3种运行Llama 3.2的方法-Analytics VidhyaApr 11, 2025 am 11:56 AM
3种运行Llama 3.2的方法-Analytics VidhyaApr 11, 2025 am 11:56 AMMeta's Llama 3.2:多式联运AI强力 Meta的最新多模式模型Llama 3.2代表了AI的重大进步,具有增强的语言理解力,提高的准确性和出色的文本生成能力。 它的能力t
 使用dagster自动化数据质量检查Apr 11, 2025 am 11:44 AM
使用dagster自动化数据质量检查Apr 11, 2025 am 11:44 AM数据质量保证:与Dagster自动检查和良好期望 保持高数据质量对于数据驱动的业务至关重要。 随着数据量和源的增加,手动质量控制变得效率低下,容易出现错误。
 大型机在人工智能时代有角色吗?Apr 11, 2025 am 11:42 AM
大型机在人工智能时代有角色吗?Apr 11, 2025 am 11:42 AM大型机:AI革命的无名英雄 虽然服务器在通用应用程序上表现出色并处理多个客户端,但大型机是专为关键任务任务而建立的。 这些功能强大的系统经常在Heavil中找到


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

Atom编辑器mac版下载
最流行的的开源编辑器

