
RoSA: 一种高效微调大模型参数的新方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-01-18 17:27:17717浏览
随着语言模型扩展到前所未有的规模,对下游任务进行全面微调变得十分昂贵。为了解决这个问题,研究人员开始关注并采用PEFT方法。PEFT方法的主要思想是将微调的范围限制在一小部分参数上,以降低计算成本,同时仍能实现自然语言理解任务的最先进性能。通过这种方式,研究人员能够在保持高性能的同时,节省计算资源,为自然语言处理领域带来新的研究热点。
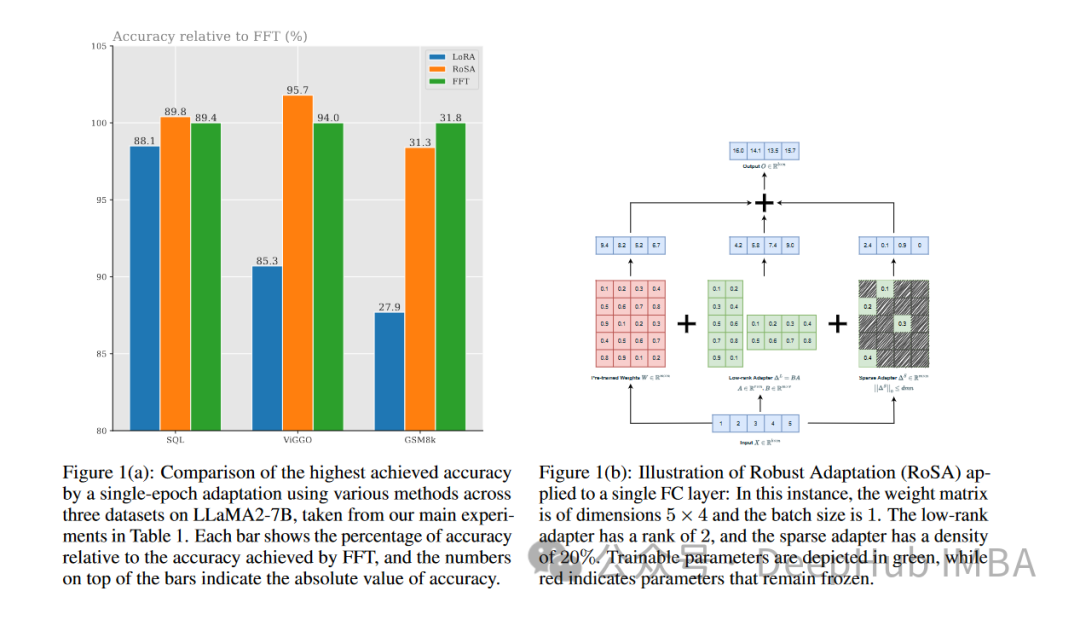
RoSA是一种新的PEFT技术,通过在一组基准测试的实验中,发现在使用相同参数预算的情况下,RoSA表现出优于先前的低秩自适应(LoRA)和纯稀疏微调方法。
本文将深入探讨RoSA原理、方法和结果,解释其性能如何标志着有意义的进步。对于希望有效微调大型语言模型的人,RoSA提供了一种新的优于以往方案的解决方案。
对参数高效微调的需求
NLP已经被基于transformer的语言模型如GPT-4彻底改变。这些模型通过对大量文本语料库进行预训练,学习到强大的语言表征。接着,它们通过一个简单的过程将这些表征转移到下游的语言任务中。
随着模型规模从数十亿个参数增长到万亿个参数,微调带来了巨大的计算负担。例如,对于GPT-4这样一个拥有1.76万亿参数的模型,微调可能需要耗费数百万美元。这使得在实际应用中部署变得非常不切实际。
PEFT方法通过限制微调的参数范围来提高效率和准确性。最近有多种PEFT技术出现,权衡了效率和准确性的关系。
LoRA
一个突出的PEFT方法是低秩适应(LoRA)。LoRA是由Meta和麻省理工学院的研究人员于2021年推出的。该方法的动机是他们观察到transformer在其头部矩阵中表现出低秩结构。LoRA的提出旨在利用这种低秩结构,以降低计算复杂度并提高模型的效率和速度。
LoRA只对前k个奇异向量进行微调,其他参数保持不变。这样只需调优O(k)个额外参数,而不是O(n)个。
通过利用这种低秩结构,LoRA可以捕获下游任务泛化所需的有意义的信号,并将微调限制在这些顶级奇异向量上,使优化和推理更加有效。
实验表明,LoRA在GLUE基准测试中可以匹配完全微调的性能,同时使用的参数减少了100倍以上。但是随着模型规模的不断扩大,通过LoRA获得强大的性能需要增加rank k,与完全微调相比减少了计算节省。
在RoSA之前,LoRA代表了PEFT方法中最先进的技术,只是使用不同的矩阵分解或添加少量额外的微调参数等技术进行了适度的改进。
Robust Adaptation (RoSA)
Robust Adaptation(RoSA)引入了一种新的参数高效微调方法。RoSA的灵感来自于稳健的主成分分析(robust PCA),而不是仅仅依赖于低秩结构。
在传统的主成分分析中,数据矩阵X被分解为X≈L + S,其中L是一个近似主成分的低秩矩阵,S是一个捕获残差的稀疏矩阵。robust PCA更进一步,将X分解为干净的低秩L和“污染/损坏”的稀疏S。
RoSA从中汲取灵感,将语言模型的微调分解为:
一个类似于LoRA的低秩自适应(L)矩阵,经过微调以近似于主导任务相关信号
一个高度稀疏的微调(S)矩阵,包含非常少量的大的、选择性微调的参数,这些参数编码L错过的残差信号。
显式地建模残差稀疏分量可以使RoSA比单独的LoRA达到更高的精度。
RoSA通过对模型的头部矩阵进行低秩分解来构建L。这将编码对下游任务有用的底层语义表示。然后RoSA选择性地将每层最重要的前m个参数微调为S,而所有其他参数保持不变。这个步骤会捕获不适合低秩拟合的残差信号。
微调参数的数量m比LoRA单独所需的rank k要小一个数量级。因此结合L中的低秩头矩阵,RoSA保持了极高的参数效率。
RoSA还采用了一些其他简单但有效果的优化:
残差稀疏连接:在每个transformer块的输出经过层归一化和前馈子层之前,直接向其添加S个残差。这可以模拟L错过的信号。
独立稀疏掩码:S中选择的用于微调的指标是为每个transformer层独立生成的。
共享低秩结构:在L的所有层之间共享相同的低秩基U,V矩阵,就像在LoRA中一样。这将捕获一致子空间中的语义概念。
这些架构选择为RoSA建模提供了类似于完全微调的灵活性,同时保持了优化和推理的参数效率。利用这种结合鲁棒低秩自适应和高度稀疏残差的PEFT方法,RoSA实现了精度效率折衷的新技术。
实验与结果
研究人员在12个NLU数据集的综合基准上对RoSA进行了评估,这些数据集涵盖了文本检测、情感分析、自然语言推理和鲁棒性测试等任务。他们使用基于人工智能助理LLM的RoSA进行了实验,使用了120亿个参数模型。
在每个任务上,在使用相同的参数时,RoSA的性能都明显优于LoRA。两种方法的总参数都差不多为整个模型的0.3%左右。这意味着LoRA的k = 16, RoSA的m =5120这两种情况下都有大约450万个微调参数。
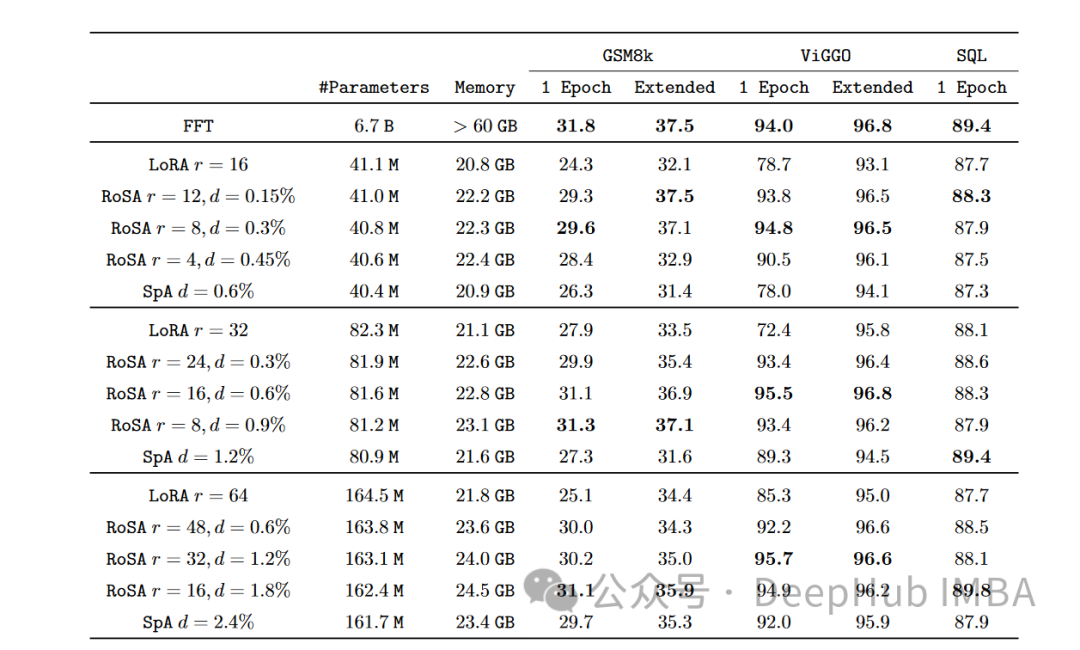
RoSA还匹配或超过了纯稀疏微调基线的性能。
在评估对对抗示例的鲁棒性的ANLI基准上,RoSA的得分为55.6,而LoRA的得分为52.7。这表明了泛化和校准的改进。
对于情感分析任务SST-2和IMDB, RoSA的准确率达到91.2%和96.9%,而LoRA的准确率为90.1%和95.3%。
在WIC(一项具有挑战性的词义消歧测试)上,RoSA的F1得分为93.5,而LoRA的F1得分为91.7。
在所有12个数据集中,RoSA在匹配的参数预算下普遍表现出比LoRA更好的性能。
值得注意的是,RoSA能够在不需要任何特定于任务的调优或专门化的情况下实现这些增益。这使得RoSA适合作为通用的PEFT解决方案使用。
总结
随着语言模型规模的持续快速增长,减少对其微调的计算需求是一个迫切需要解决的问题。像LoRA这样的参数高效自适应训练技术已经显示出初步的成功,但面临低秩近似的内在局限性。
RoSA将鲁棒低秩分解和残差高度稀疏微调有机地结合在一起,提供了一个令人信服的新解决方案。通过考虑通过选择性稀疏残差逃避低秩拟合的信号,它大大提高了PEFT的性能。经验评估表明,在不同的NLU任务集上,LoRA和不受控制的稀疏性基线有了明显的改进。
RoSA在概念上简单但高性能,能进一步推进参数效率、适应性表征和持续学习的交叉研究,以扩大语言智能。
以上是RoSA: 一种高效微调大模型参数的新方法的详细内容。更多信息请关注PHP中文网其他相关文章!