Lightning Attention-2 是一种新型的线性注意力机制,让长序列的训练和推理成本与 1K 序列长度的一致。
大语言模型序列长度的限制,极大地制约了其在人工智能领域的应用,比如多轮对话、长文本理解、多模态数据的处理与生成等。造成这一限制的根本原因在于当前大语言模型均采用的 Transformer 架构有着相对于序列长度的二次计算复杂度。这意味着随着序列长度的增加,需要的计算资源成几何倍数提升。如何高效地处理长序列一直是大语言模型的挑战之一。之前的方法往往集中在如何让大语言模型在推理阶段适应更长的序列。比如采用 Alibi 或者类似的相对位置编码的方式来让模型自适应不同的输入序列长度,亦或采用对 RoPE 等类似的相对位置编码进行差值的方式,在已经完成训练的模型上再进行进一步的短暂精调来达到扩增序列长度的目的。这些方法只是让大模型具有了一定的长序列建模能力,但实际训练和推理的开销并没有减少。 OpenNLPLab 团队尝试一劳永逸地解决大语言模型长序列问题。他们提出并开源了 Lightning Attention-2—— 一种新型的线性注意力机制,让长序列的训练和推理成本与 1K 序列长度的一致。在遇到显存瓶颈之前,无限地增大序列长度并不会对于模型训练速度产生负面影响。这让无限长度预训练成为了可能。同时,超长文本的推理成本也与 1K Tokens 的成本一致甚至更少,这将极大地减少当前大语言模型的推理成本。如下图所示,在 400M、1B、3B 的模型大小下,随着序列长度的增加,FlashAttention2 加持的 LLaMA 的训练速度开始快速下降,然而 Lightning Attention-2 加持的 TansNormerLLM 的速度几无变化。 图 1
图 1
- 论文:Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
- 论文地址:https://arxiv.org/pdf/2401.04658.pdf
- 开源地址:https://github.com/OpenNLPLab/lightning-attention
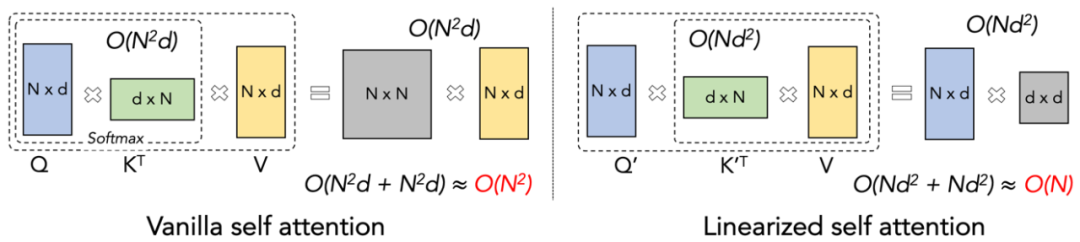
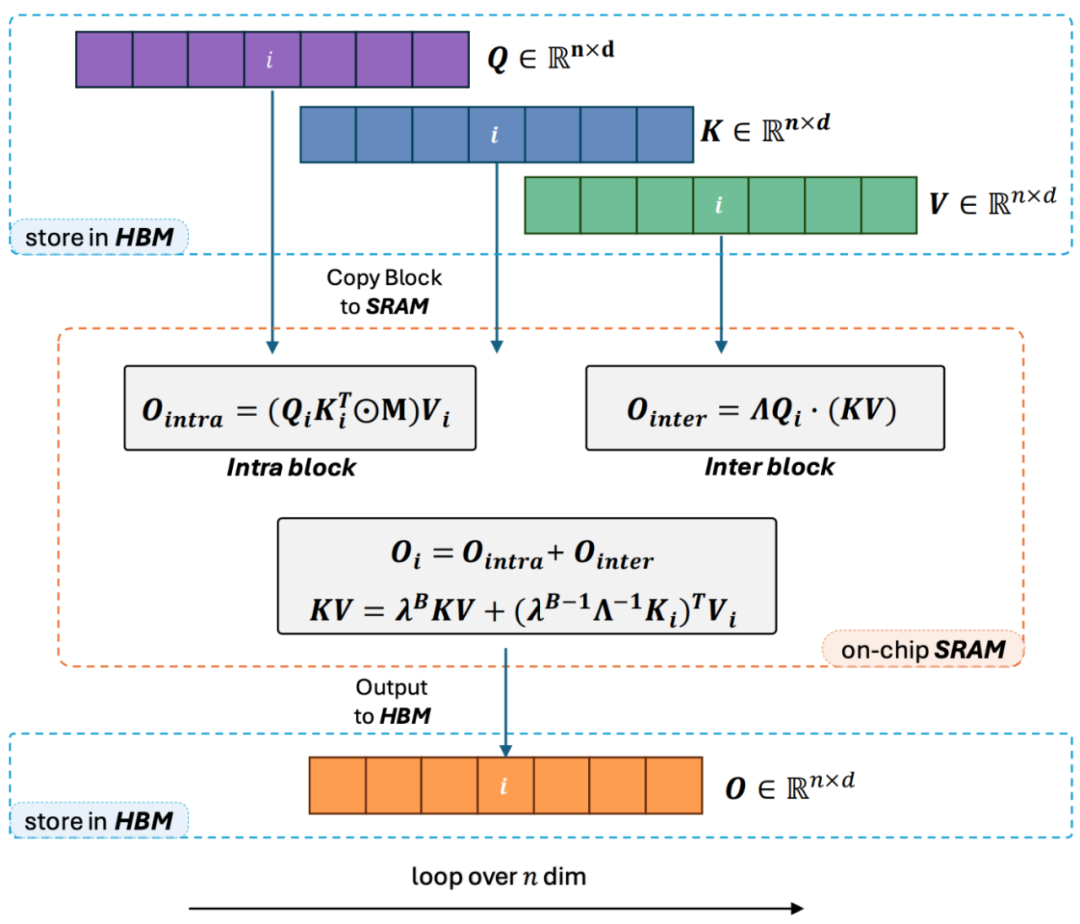
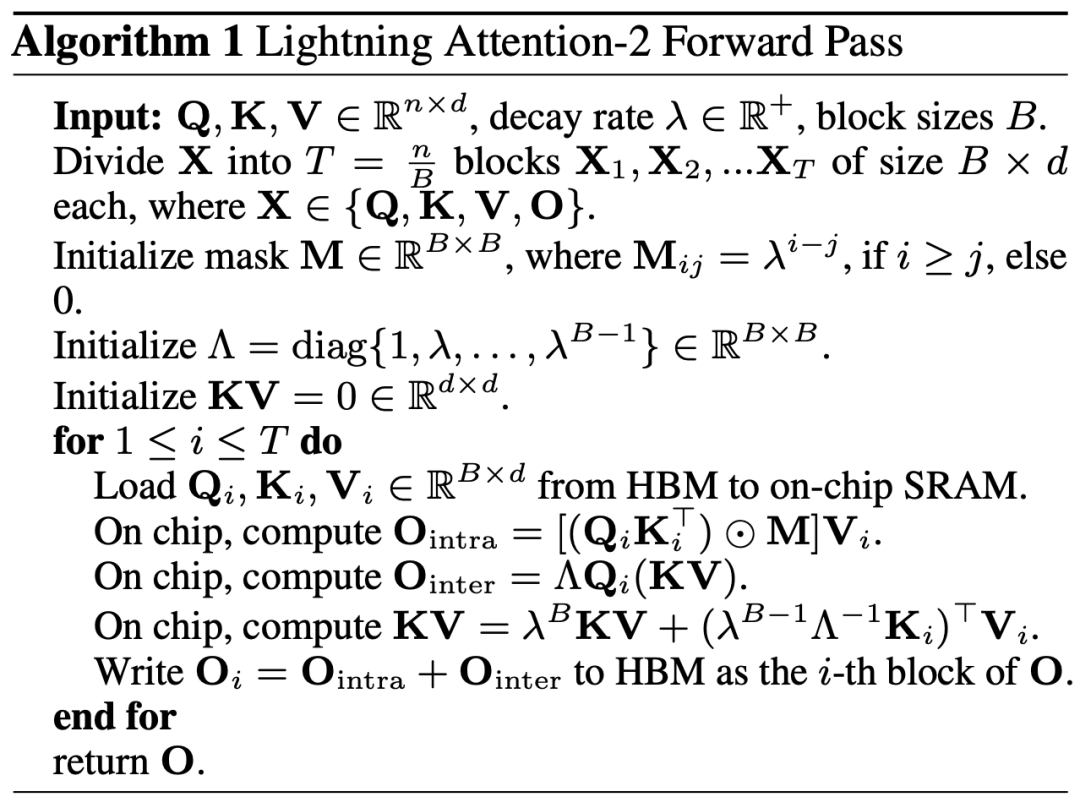
让大模型的预训练速度在不同序列长度下保持一致,这听起来是一个不可能的任务。事实上,如果一个注意力机制的计算复杂度相对于序列长度保持线性关系的话,就可以实现这一点。自 2020 年线性注意力【https://arxiv.org/abs/2006.16236】横空出世以来,研究人员一直在为了线性注意力的实际效率符合它的理论线性计算复杂度而努力。在 2023 年之前,大多数的关于线性注意力的工作均集中在对齐它们与 Transformer 的精度上。终于在 2023 年中期,改进的线性注意力机制【https://arxiv.org/abs/2307.14995】在精度上可以与最先进的 Transformer 架构对齐。然而,线性注意力中将计算复杂度变成线性的最关键的 “左乘变右乘” 的计算 Trick (如下图所示),在实际实现中远慢于直接左乘的算法。其原因在于右乘的实现需要用到包含大量循环操作的累积求和(cumsum),大量的 IO 操作使得右乘的效率远低于左乘。为了更好的理解 Lightning Attention-2 的思路,让我们先回顾下传统 softmax attention 的计算公式:O=softmax ((QK^T)⊙M_) V,其中 Q, K, V, M, O 分别为 query, key, value, mask 和输出矩阵,这里的 M 在单向任务(如 GPT)中是一个下三角的全 1 矩阵,在双向任务(如 Bert)中则可以忽略,即双向任务没有 mask 矩阵。作者将 Lightning Attention-2 的整体思路总结为以下三点进行解释:1. Linear Attention 的核心思想之一就是去除了计算成本高昂的 softmax 算子,使 Attention 的计算公式可以写为 O=((QK^T)⊙M_) V。但由于单向任务中 mask 矩阵 M 的存在,使得该形式依然只能进行左乘计算,从而不能获得 O (N) 的复杂度。但对于双向任务,由于没有没有 mask 矩阵,Linear Attention 的计算公式可以进一步简化为 O=(QK^T) V。Linear Attention 的精妙之处在于,仅仅利用简单的矩阵乘法结合律,其计算公式就可以进一步转化为:O=Q (K^T V),这种计算形式被称为右乘,相对应的前者为左乘。通过图 2 可以直观地理解到 Linear Attention 在双向任务中可以达到诱人的 O (N) 复杂度!2. 但是随着 decoder-only 的 GPT 形式的模型逐渐成为 LLM 的事实标准,如何利用 Linear Attention 的右乘特性加速单向任务成为了亟待解决的难题。为了解决这个问题,本文作者提出了利用 “分而治之” 的思想,将注意力矩阵的计算分为对角阵和非对角阵两种形式,并采用不同的方式对他们进行计算。如图 3 所示,Linear Attention-2 利用计算机领域常用的 Tiling 思想,将 Q, K, V 矩阵分别切分为了相同数量的块 (blocks)。其中 block 自身(intra-block)的计算由于 mask 矩阵的存在,依然保留左乘计算的方式,具有 O (N^2) 的复杂度;而 block 之间(inter-block)的计算由于没有 mask 矩阵的存在,可以采用右乘计算方式,从而享受到 O (N) 的复杂度。两者分别计算完成后,可以直接相加得到对应第 i 块的 Linear Attention 输出 Oi。同时,通过 cumsum 对 KV 的状态进行累积以在下一个 block 的计算中使用。这样就得到了整个 Lightning Attention-2 的算法复杂度为 intra-block 的 O (N^2) 和 inter-block 的 O (N) 的 Trade-off。怎么取得更好的 Trade-off 则是由 Tiling 的 block size 决定的。3. 细心的读者会发现,以上的过程只是 Lightning Attention-2 的算法部分,之所以取名 Lightning 是因为作者充分考虑了该算法过程在 GPU 硬件执行过程中的效率问题。受到 FlashAttention 系列工作的启发,实际在 GPU 上进行计算的时候,作者将切分后的 Q_i, K_i, V_i 张量从 GPU 内部速度更慢容量更大的 HBM 搬运到速度更快容量更小的 SRAM 上进行计算,从而减少大量的 memory IO 开销。当该 block 完成 Linear Attention 的计算之后,其输出结果 O_i 又会被搬回至 HBM。重复这个过程直到所有 block 被处理完毕即可。想要了解更多细节的读者可以仔细阅读本文中的 Algorithm 1 和 Algorithm 2,以及论文中的详细推导过程。Algorithm 以及推导过程都对 Lightning Attention-2 的前向和反向过程进行了区分,可以帮助读者有更深入的理解。
图 3
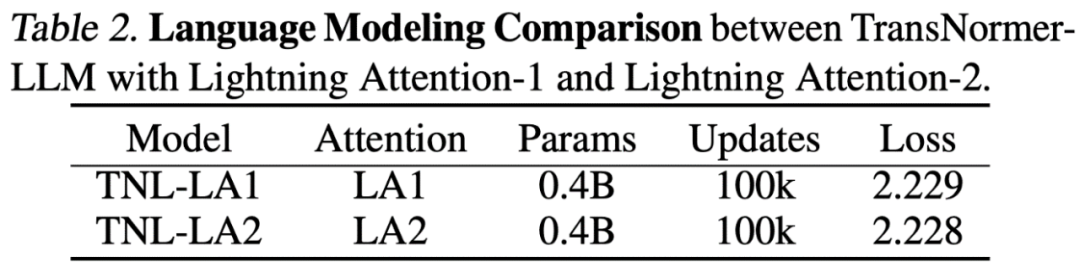
Lightning Attention-2 精度对比研究人员首先在小规模(400M)参数模型上对比了 Lightning Attention-2 与 Lightning Attention-1 的精度区别,如下图所示,二者几无差别。
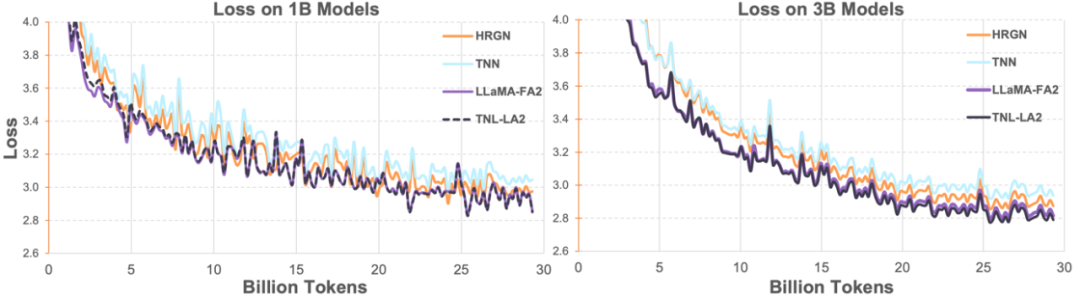
随后研究人员在 1B、3B 上将 Lightning Attention-2 加持的 TransNormerLLM(TNL-LA2)与其它先进的非 Transformer 架构的网络以及 FlashAttention2 加持的 LLaMA 在相同的语料下做了对比。如下图所示,TNL-LA2 与 LLaMA 保持了相似的趋势,并且 loss 的表现更优。这个实验表明,Lightning Attention-2 在语言建模方面有着不逊于最先进的 Transformer 架构的精度表现。
在大语言模型任务中,研究人员对比了 TNL-LA2 15B 与 Pythia 在类似大小下的大模型常见 Benchmark 的结果。如下表所示,在吃掉了相同 tokens 的条件下,TNL-LA2 在常识推理和多项选择综合能力上均略高于基于 Softmax 的注意力的 Pythia 模型。
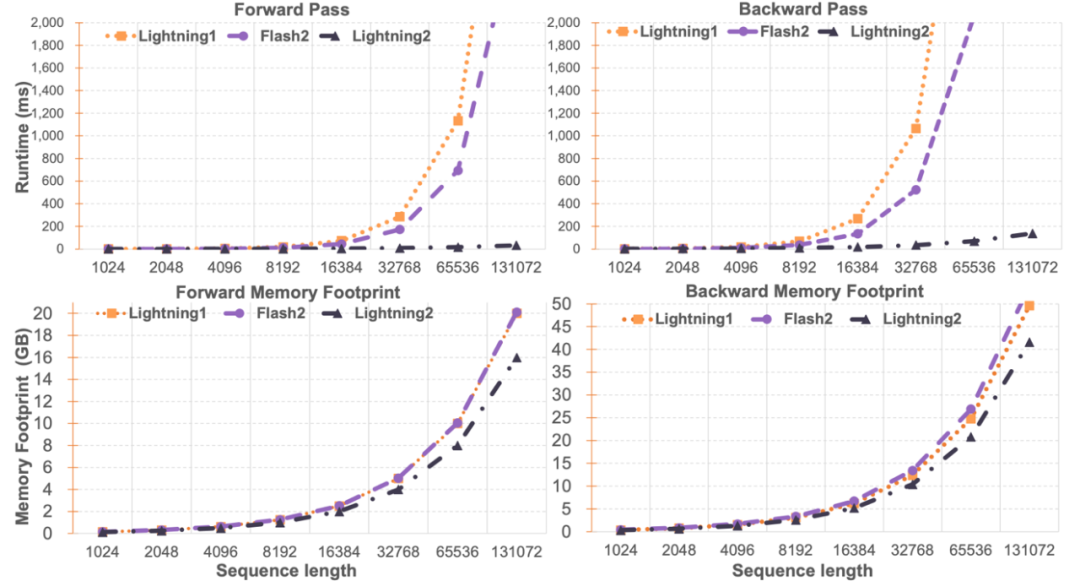
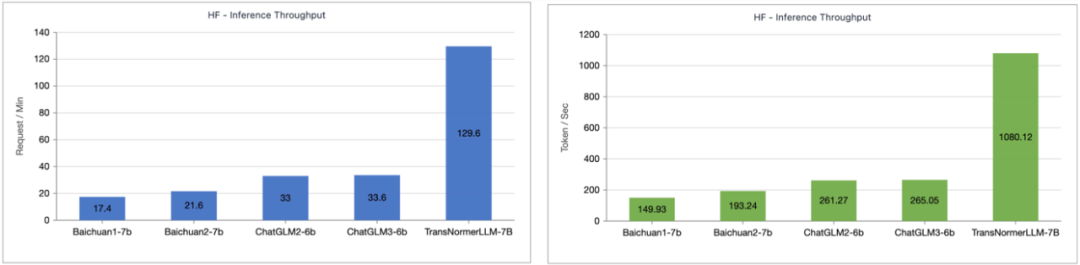
Lightning Attention-2 速度对比研究人员对 Lightning Attention-2 与 FlashAttention2 进行了单模块速度与显存占用对比。如下图所示,相比于 Lightning Attention-1 和 FlashAttention2,在速度上,Lightning Attention-2 表现出了相比于序列长度的严格线性增长。在显存占用上,三者均显示出了类似的趋势,但 Lightning Attention-2 的显存占用更小。这个的原因是 FlashAttention2 和 Lightning Attention-1 的显存占用也是近似线性的。笔者注意到,这篇文章主要关注点在解决线性注意力网络的训练速度上,并实现了任意长度的长序列与 1K 序列相似的训练速度。在推理速度上,并没有过多的介绍。这是因为线性注意力在推理的时候可以无损地转化为 RNN 模式,从而达到类似的效果,即推理单 token 的速度恒定。对于 Transformer 来说,当前 token 的推理速度与它之前的 token 数量相关。笔者测试了 Lightning Attention-1 加持的 TransNormerLLM-7B 与常见的 7B 模型在推理速度上的对比。如下图所示,在近似参数大小下,Lightning Attention-1 的吞吐速度是百川的 4 倍,ChatGLM 的 3.5 倍以上,显示出了优异的推理速度优势。
Lightning Attention-2 代表了线性注意力机制的重大进步,使其无论在精度还是速度上均可以完美的替换传统的 Softmax 注意力,为今后越来越大的模型提供了可持续扩展的能力,并提供了一条以更高效率处理无限长序列的途径。OpenNLPLab 团队在未来将研究基于线性注意力机制的序列并行算法,以解决当前遇到的显存屏障问题。以上是Lightning Attention-2:实现无限序列长度、恒定算力成本和更高建模精度的新一代注意力机制的详细内容。更多信息请关注PHP中文网其他相关文章!


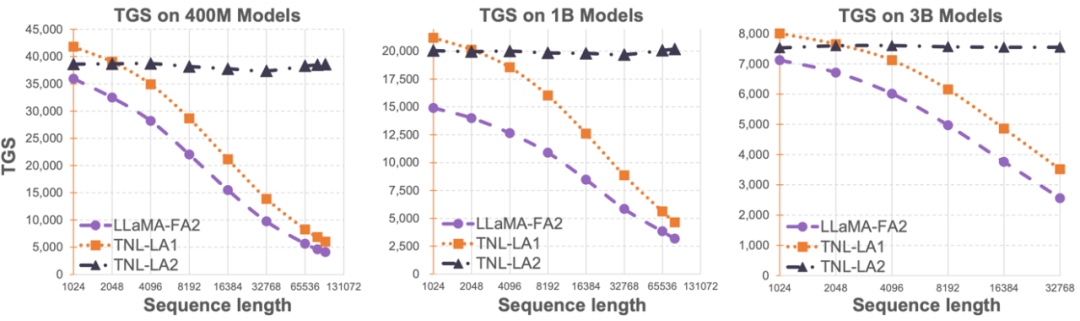 图 1
图 1