



近年来,大模型的研究正在加速推进,它逐渐在各类任务上展现出多模态的理解和时间空间上的推理能力。机器人的各类具身操作任务天然就对语言指令理解、场景感知和时空规划等能力有着很高的要求,这自然引申出一个问题:能不能充分利用大模型能力,将其迁移到机器人领域,直接规划底层动作序列呢?
ByteDance Research利用开源的多模态语言视觉大模型OpenFlamingo开发了易用的RoboFlamingo机器人操作模型,只需单机训练。VLM可通过简单微调变成Robotics VLM,适用于语言交互的机器人操作任务。
在机器人操作数据集CALVIN上,OpenFlamingo进行了验证。实验结果表明,RoboFlamingo仅使用了1%带有语言标注的数据,就在一系列机器人操作任务中取得了SOTA的性能。随着RT-X数据集的开放,采用开源数据预训练的RoboFlamingo,并进行不同机器人平台的微调,有望成为一个简单有效的机器人大模型流程。论文还测试了不同策略头、不同训练范式和不同Flamingo结构的VLM在机器人任务上的微调表现,并得出了一些有趣的结论。

- 项目主页:https://roboflamingo.github.io
- 代码地址:https://github.com/RoboFlamingo/RoboFlamingo
- 论文地址:https://arxiv.org/abs/2311.01378
研究背景
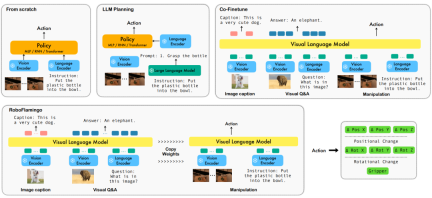
基于语言的机器人操作是具身智能领域的一个重要应用,涉及到多模态数据的理解和处理,包括视觉、语言和控制等。近年来,视觉语言基础模型(VLMs)在图像描述、视觉问答和图像生成等领域取得了显著进展。然而,将这些模型应用于机器人操作仍面临挑战,如如何整合视觉和语言信息,以及如何处理机器人操作的时序性。解决这些挑战需要在多个方面进行改进,例如改进模型的多模态表示能力,设计更有效的模型融合机制,以及引入适应机器人操作时序性的模型结构和算法。此外,还需要发展更丰富的机器人数据集,以训练和评估这些模型。通过持续的研究和创新,基于语言的机器人操作有望在实际应用中发挥更大的作用,为人类提供更智能、便捷的服务。
为了解决这些问题,ByteDance Research的机器人研究团队对现有的开源VLM(Visual Language Model)——OpenFlamingo进行了微调,并设计了一套新的视觉语言操作框架,称为RoboFlamingo。这个框架的特点是利用VLM实现了单步视觉语言理解,并通过额外的policy head模组处理历史信息。通过简单的微调方法,RoboFlamingo能够适应基于语言的机器人操作任务。这一框架的引入有望解决当前机器人操作中存在的一系列问题。
RoboFlamingo 在基于语言的机器人操作数据集 CALVIN 上进行了验证,实验结果表明,RoboFlamingo 只利用了 1% 的带语言标注的数据即在一系列机器人操作任务上取得了 SOTA 的性能(多任务学习的 task sequence 成功率为 66%,平均任务完成数量为 4.09,基线方法为 38%,平均任务完成数量为 3.06;zero-shot 任务的成功率为 24%,平均任务完成数量为 2.48,基线方法为 1%,平均任务完成数量是 0.67),并且能够通过开环控制实现实时响应,可以灵活部署在较低性能的平台上。这些结果表明,RoboFlamingo 是一种有效的机器人操作方法,可以为未来的机器人应用提供有用的参考。
方法
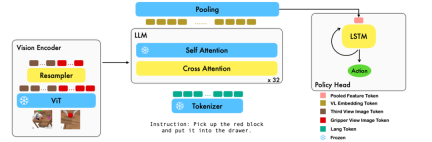
本工作利用已有的基于图像 - 文本对的视觉语言基础模型,通过训练端到端的方式生成机器人每一步的相对动作。该模型由三个主要模块组成:Vision encoder,Feature fusion decoder 和 Policy head。 在 Vision encoder 模块中,当前视觉观测首先被输入到 ViT 中,然后通过 resampler 对 ViT 输出的 token 进行 down sample。这一步骤有助于减小模型的输入维度,从而提高了训练效率。 Feature fusion decoder 模块将 text token 作为输入,并通过交叉注意力机制将视觉编码器的输出作为查询,实现了视觉与语言特征的融合。在每个 layer 中,feature fusion decoder 首先执行交叉注意力操作,然后执行自注意力操作。这些操作有助于提取出语言和视觉特征之间的相关性,从而更好地生成机器人的动作。 在 Feature fusion decoder 输出的当前和历史 token 序列的基础上,Policy head 直接输出当前的 7 DoF 相对动作,包括了 6-dim 的机械臂末端位姿和 1-dim 的 gripper open/close。最后,对 feature fusion decoder 进行 max pooling 后将其送入 Policy head 中,从而生成相对动作。 通过这种方式,我们的模型能够有效地将视觉和语言信息融合在一起,生成出准确的机器人动作。这对于机器人控制和自主导航等领域有着广泛的应用前景。
在训练过程中,RoboFlamingo 利用预训练的 ViT、LLM 和 Cross Attention 参数,并只微调 resampler、cross attention 和 policy head 的参数。
实验结果
数据集:

CALVIN(Composing Actions from Language and Vision)是一个开源的模拟基准测试,用于学习基于语言的 long-horizon 操作任务。与现有的视觉 - 语言任务数据集相比,CALVIN 的任务在序列长度、动作空间和语言上都更为复杂,并支持灵活地指定传感器输入。CALVIN 分为 ABCD 四个 split,每个 split 对应了不同的 context 和 layout。
定量分析:
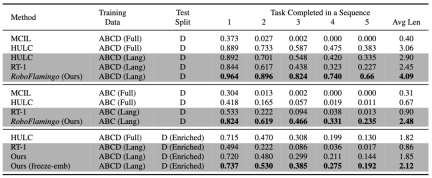
RoboFlamingo 在各设置和指标上的性能均为最佳,说明了其具有很强的模仿能力、视觉泛化能力以及语言泛化能力。Full 和 Lang 表示模型是否使用未配对的视觉数据进行训练(即没有语言配对的视觉数据);Freeze-emb 指的是冻结融合解码器的嵌入层;Enriched 表示使用 GPT-4 增强的指令。
消融实验:
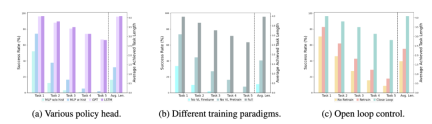
不同的 policy head:
实验考察了四种不同的策略头部:MLP w/o hist、MLP w hist、GPT 和 LSTM。其中,MLP w/o hist 直接根据当前观测预测历史,其性能最差,MLP w hist 将历史观测在 vision encoder 端进行融合后预测 action,性能有所提升;GPT 和 LSTM 在 policy head 处分别显式、隐式地维护历史信息,其表现最好,说明了通过 policy head 进行历史信息融合的有效性。
视觉-语言预训练的影响:
预训练对于 RoboFlamingo 的性能提升起到了关键作用。实验显示,通过预先在大型视觉-语言数据集上进行训练,RoboFlamingo 在机器人任务中表现得更好。
模型大小与性能:
虽然通常更大的模型会带来更好的性能,但实验结果表明,即使是较小的模型,也能在某些任务上与大型模型媲美。
指令微调的影响:
指令微调是一个强大的技巧,实验结果表明,它可以进一步提高模型的性能。
定性结果
相较于基线方法,RoboFlamingo 不但完整执行了 5 个连续的子任务,且对于基线页执行成功的前两个子任务,RoboFlamingo 所用的步数也明显更少。

总结
本工作为语言交互的机器人操作策略提供了一个新颖的基于现有开源 VLMs 的框架,使用简单微调就能实现出色的效果。RoboFlamingo 为机器人技术研究者提供了一个强大的开源框架,能够更容易地发挥开源 VLMs 的潜能。工作中丰富的实验结果或许可以为机器人技术的实际应用提供宝贵的经验和数据,有助于未来的研究和技术发展。
以上是开源VLMs的潜力被RoboFlamingo框架释放的详细内容。更多信息请关注PHP中文网其他相关文章!

 ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AM
ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AMai合并图层的快捷键是“Ctrl+Shift+E”,它的作用是把目前所有处在显示状态的图层合并,在隐藏状态的图层则不作变动。也可以选中要合并的图层,在菜单栏中依次点击“窗口”-“路径查找器”,点击“合并”按钮。
 ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AM
ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AMai橡皮擦擦不掉东西是因为AI是矢量图软件,用橡皮擦不能擦位图的,其解决办法就是用蒙板工具以及钢笔勾好路径再建立蒙板即可实现擦掉东西。
 谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM
谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM虽然谷歌早在2020年,就在自家的数据中心上部署了当时最强的AI芯片——TPU v4。但直到今年的4月4日,谷歌才首次公布了这台AI超算的技术细节。论文地址:https://arxiv.org/abs/2304.01433相比于TPU v3,TPU v4的性能要高出2.1倍,而在整合4096个芯片之后,超算的性能更是提升了10倍。另外,谷歌还声称,自家芯片要比英伟达A100更快、更节能。与A100对打,速度快1.7倍论文中,谷歌表示,对于规模相当的系统,TPU v4可以提供比英伟达A100强1.
 ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PM
ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PMai可以转成psd格式。转换方法:1、打开Adobe Illustrator软件,依次点击顶部菜单栏的“文件”-“打开”,选择所需的ai文件;2、点击右侧功能面板中的“图层”,点击三杠图标,在弹出的选项中选择“释放到图层(顺序)”;3、依次点击顶部菜单栏的“文件”-“导出”-“导出为”;4、在弹出的“导出”对话框中,将“保存类型”设置为“PSD格式”,点击“导出”即可;
 ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PM
ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PMai顶部属性栏不见了的解决办法:1、开启Ai新建画布,进入绘图页面;2、在Ai顶部菜单栏中点击“窗口”;3、在系统弹出的窗口菜单页面中点击“控制”,然后开启“控制”窗口即可显示出属性栏。
 GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AM
GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AMYann LeCun 这个观点的确有些大胆。 「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」最近,图灵奖得主 Yann LeCun 给一场辩论做了个特别的开场。而他口中的自回归,正是当前爆红的 GPT 家族模型所依赖的学习范式。当然,被 Yann LeCun 指出问题的不只是自回归模型。在他看来,当前整个的机器学习领域都面临巨大挑战。这场辩论的主题为「Do large language models need sensory grounding for meaning and u
 AI抢饭碗成真!近500家美国企业用ChatGPT取代员工,有公司省下超10万美元Apr 07, 2023 pm 02:57 PM
AI抢饭碗成真!近500家美国企业用ChatGPT取代员工,有公司省下超10万美元Apr 07, 2023 pm 02:57 PM自从ChatGPT掀起浪潮,不少人都在担心AI快要抢人类饭碗了。然鹅,现实可能更残酷QAQ......据就业服务平台Resume Builder调查统计,在1000多家受访美国企业中,用ChatGPT取代部分员工的,比例已达到惊人的48%。在这些企业中,有49%已经启用ChatGPT,还有30%正在赶来的路上。就连央视财经也为此专门发过一个报道:相关话题还曾一度冲上了知乎热榜,众网友表示,不得不承认,现在ChatGPT等AIGC工具已势不可挡——浪潮既来,不进则退。有程序员还指出:用过Copil
 ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AM
ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AMai移动不了东西的解决办法:1、打开ai软件,打开空白文档;2、选择矩形工具,在文档中绘制矩形;3、点击选择工具,移动文档中的矩形;4、点击图层按钮,弹出图层面板对话框,解锁图层;5、点击选择工具,移动矩形即可。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

Atom编辑器mac版下载
最流行的的开源编辑器

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

Dreamweaver Mac版
视觉化网页开发工具

