
自动驾驶领域的端到端技术是否会替代Apollo、autoware等框架?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2024-01-16 08:36:11925浏览
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
- 作者单位:百度
- 作者:共一 Jiang-Tian Zhai, Ze Feng,百度王井东组
- 发表:arXiv
- 论文链接:https://arxiv.org/abs/2305.10430
- 代码链接:https://github.com/E2E-AD/AD-MLP
关键词:端到端自动驾驶,nuScenes 开环评估
1. 摘要
现有的自动驾驶系统通常被分为三个主任务:感知、预测和规划;规划任务涉及到基于内部意图和外部环境来预测自车的运动轨迹,并操纵车辆。大部分现有方案在 nuScenes 数据集上评估他们的方法,评价指标为 L2 error 和碰撞率(collision rate)
本文重新对现有的评价指标做了评估,探索他们是否能够准确地度量不同方法的优越性。本文还设计了一个 MLP-based 方法,将原始 sensor 数据(历史轨迹、速度等)作为输入,直接输出自车的未来轨迹,不使用任何感知和预测信息,例如 camera 图像或者 LiDAR。令人惊讶的是:这样一个简单的方法在 nuScenes 数据集上达到了 SOTA 的 planning 性能,减少了 30% 的 L2 error。我们进一步深入分析,对于 nuScenes 数据集上的规划任务很重要的因子提供了一些新的见解。我们的观察还表明,我们需要重新思考 nuScenes 中端到端自动驾驶的开环评测方案。
2. 论文的目的、贡献及结论
本文希望对 nuScenes 上端到端自动驾驶的开环评测方案做评估;不使用视觉和 Lidar 的情况下,只使用自车状态和高级命令(一共 21 维的向量)作为输入就可以在 nuScenes 上达到 Planning 的 SOTA。作者由此指出了 nuScenes 上开环评测的不可靠性,给出了两个分析:nuScenes 数据集上自车轨迹倾向于直行或者曲率非常小的曲线;碰撞率的检测和网格密度相关,并且数据集的碰撞标注也有噪声,当前评估碰撞率的方法不够鲁棒和准确;
3. 论文的方法
3.1 简介及相关工作简述
现存的自动驾驶模型涉及到多个独立任务,例如感知、预测和规划。这种设计简化了跨团队写作的难度,但也会由于各个任务的优化和训练的独立性,导致整个系统的信息丢失和误差累积。端到端的方法被提出,这类方法从自车和周围环境的时空特征学习中受益。
相关工作:ST-P3[1] 提出一种可解释的基于视觉的端到端系统,将感知、预测和规划的特征学习进行统一。UniAD[2] 对 Planning 任务进行系统化设计,采用基于 query 的设计连接中间多个任务,可以对多个任务的关系进行建模和编码;VAD[3] 以完全向量化的方式对场景进行建模,不需要稠密的特征表示,在计算上更为高效。
本文希望探索现有的评估指标是否能准确地度量不同方法的优劣。本文仅使用了自车在行驶中的的物理状态(现有方法所使用信息的子集)来开展实验,而不是使用相机和激光雷达提供的感知和预测信息。总之,本文的模型没有用视觉或者点云特征的编码器,直接将自车的物理信息编码为一维向量,在 concat 之后送到 MLP 中。训练使用 GT 轨迹进行监督,模型直接预测自车未来一定时间内的轨迹点。follow 之前的工作,在 nuScenes 数据集上使用 L2 Error 和碰撞率(collision rate.)进行评估
虽然模型设计简单,但获得了最好的 Planning 结果,本文将此归因于当前评估指标的不足。事实上,通过使用过去的自车轨迹、速度、加速度和时间连续性,就可以在一定程度上反映出自车在未来的运动
3.2 模型结构
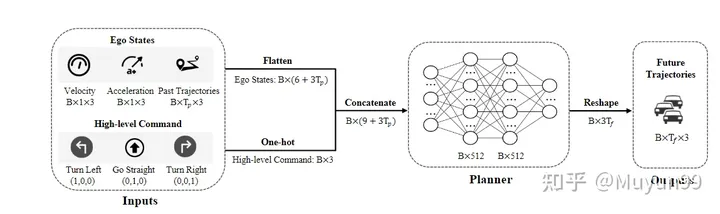
模型结构总览
模型输入包括两部分:自车状态以及代表未来短期运动趋势的高级命令。
自车状态:搜集了自车过去 =4帧的运动轨迹、瞬时速度和加速度

高级命令:由于我们的模型不使用高精地图,所以需要高级命令进行导航。按照常见的作法,定义了三种类型的命令:左转、直行和右转。具体来讲,当自车在未来 3s 中将向左或向右位移大于 2m 时,将相应的命令设置为左转或者右转,否则则是直行。使用维度为 1x3 的 one-hot 编码来表示高级命令
网络结构:网络就是简单的三层 MLP(输入到输出的维度分别为 21-512-512-18),最终输出的帧数=6,每一帧输出自车的轨迹位置(x,y 坐标)以及航向角(heading 角)
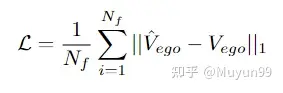
损失函数
损失函数:使用 L1 损失函数进行惩罚
4. 论文的实验
4.1 实验设置
数据集:在 nuScenes 数据集上做实验,nuScenes 数据集包括 1K 场景和大约 40K 关键帧,主要收集在波士顿和新加坡,使用配备 LiDAR 和周视摄像头的车辆。为每一帧收集的数据包括多视角 Camear 图像、LiDAR、速度、加速度等。
评测指标:使用 ST-P3 论文的评测代码(https://github.com/OpenPerceptionX/ST-P3/blob/main/stp3/metrics.py)。评估1s、2s和3s时间范围的输出轨迹。为了评估预测的自车轨迹的质量,计算了两个常用的指标:
L2 Error :以米为单位,分别在下一个 1s、2s 和 3s 时间范围内自车的预测轨迹和真实轨迹之间计算平均 L2 误差;
碰撞率(collision rate):以百分比为单位。为了确定自车与其他物体碰撞的频率,通过在预测轨迹上的每个航路点放置一个表示自车的 box ,然后检测与当前场景中车辆和行人的边界框的是否发生了碰撞,以计算碰撞率。
超参数设置及硬件:PaddlePaddle 和 PyTorch 框架,AdamW 优化器(4e-6 lr 及 1e-2 weight decay),cosine scheduler,训了 6 个 epoch,batch size 为 4,用了一张 V100
4.2 实验结果
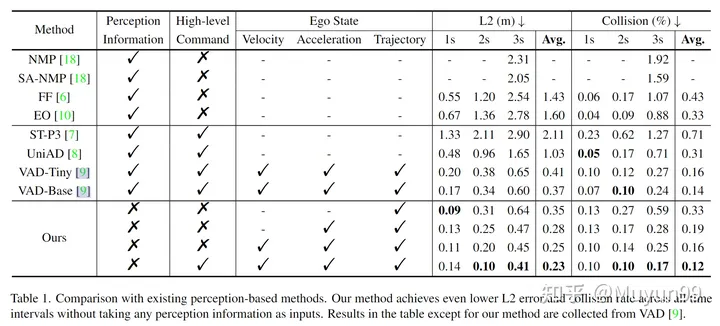
表1 和现有的基于感知的方法进行比较
在表 1 中进行了一些消融实验。以分析速度、加速度、轨迹和 High-level Command 对本文模型性能的影响。令人惊讶的是,仅使用轨迹作为输入,没有感知信息,本文的 Baseline 模型已经实现了比所有现有方法更低的平均 L2 误差。
当我们逐渐向输入添加加速度、速度和 High-level Command 时,平均 L2 误差和碰撞率从 0.35m 降低到 0.23m,将 0.33% 降低到 0.12%。同时将 Ego State 和 High-level Command 作为输入的模型实现了最低的 L2 误差和碰撞率,超过了所有先前最先进的基于感知的方法,如最后一行所示。
4.3 实验分析
文章从两个角度分析了自我车辆状态在nuScenes训练集上的分布:未来3s的轨迹点;航向角(heading / yaw角)和曲率角(curvature angles)
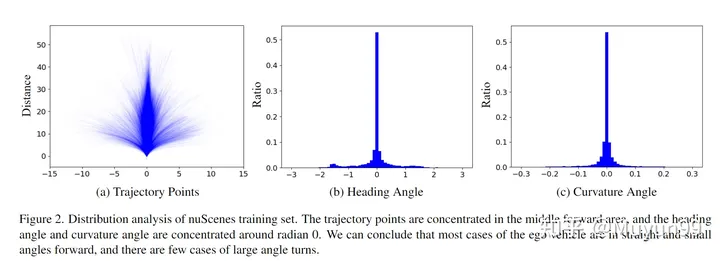
nuScenes 训练集的分布分析。
在图 2 (a) 中绘制了训练集中的所有未来 3s 轨迹点。从图中可以看出,轨迹主要集中在中间部分(直),轨迹主要是直线,或曲率非常小的曲线。
航向角表示相对于当前时间的未来行驶方向,而曲率角反映了车辆的转弯速度。如图 2 (b) 和 (c) 所示,近 70% 的航向角和曲率角分别位于 -0.2 到 0.2 和 -0.02 到 0.02 弧度的范围内。这一发现与从轨迹点分布中得出的结论是一致的。
基于上述对轨迹点、航向角和曲率角分布的分析,本文认为在 nuScenes 训练集中,自车倾向于沿直线前进,在短时间范围内行驶时以小角度前进。
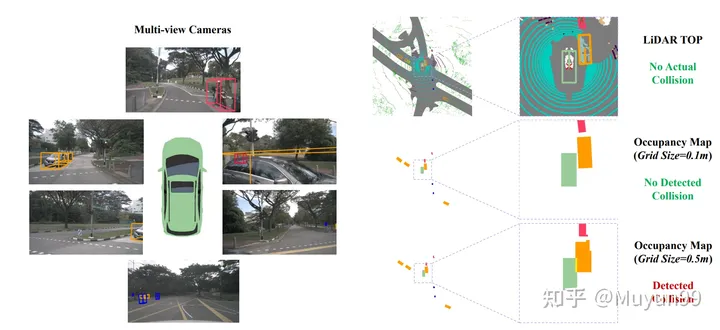
Occupancy map 的不同网格大小引起 GT 轨迹会发生碰撞
在计算碰撞率时,现有方法的常见做法是将车辆和行人等对象投影到鸟瞰图 (BEV) 空间中,然后将它们转换为图中的占用区域。而这就是精度损失之处,我们发现一小部分 GT 轨迹样本(约2%)也与占用网格中的障碍物重叠,但自车在收集数据时实际上不会与其他任何对象发生碰撞,这导致碰撞被错误检测。当 ego 车辆接近某些对象时会导致错误的碰撞,例如小于单个 Occupancy map 像素的尺寸。
图三展示了这种现象的示例,以及两种不同网格大小的地面实况轨迹的碰撞检测结果。橙色是可能被误检为碰撞的车辆,在右下角所示的较小网格尺寸(0.1m)下,评估系统正确地将 GT 轨迹识别为不碰撞,但在右下角较大的网格尺寸(0.5m)下,会出现错误的碰撞检测。
在观察占用网格大小对轨迹碰撞检测的影响后,我们测试了网格大小为0.6m。nuScenes 训练集有 4.8% 的碰撞样本,而验证集有 3.0%。值得一提的是,当我们之前使用 0.5m 的网格大小时,验证集中只有 2.0% 的样本被错误分类为碰撞。这再次证明了当前评估碰撞率的方法不够鲁棒和准确的。
作者总结:本文的主要目的是提出我们的观察结果,而不是提出一个新的模型。尽管我们的模型在 nuScenes 数据集上表现良好,但我们承认它只是一个不切实际的玩具,无法在现实世界中发挥作用。在没有自车状态的情况下驾驶是一项难以克服的挑战。尽管如此,我们希望我们的见解将促进该领域的进一步研究,对端到端自动驾驶的进步能够重新评估。
5. 文章评价
这篇文章是对近期端到端自动驾驶在 nuScenes 数据集上评测的一次正本清源。不论是隐式端到端直接出 Planning 信号,还是显式端到端有中间环节的输出,很多都是在 nuScenes 数据集上评测的 Planning 指标,而 Baidu 这篇文章指出这种评测并不靠谱。这种文章其实还蛮有意思,发出来其实是打了很多同行的脸,但是也是在积极地推动行业往前走,或许端到端不用做到 Planning(感知预测端到端即可),或许大家在评估性能的时候多做一些闭环测试(CARLA 模拟器等),能够更好地推动自动驾驶社区的进步,能够把论文落到实车上。自动驾驶这条路,还是任重而道远~
参考
- ^ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning
- ^Planning-oriented Autonomous Driving
- ^VAD: Vectorized Scene Representation for Efficient Autonomous Driving

原文链接:https://mp.weixin.qq.com/s/skNDMk4B1rtvJ_o2CM9f8w
以上是自动驾驶领域的端到端技术是否会替代Apollo、autoware等框架?的详细内容。更多信息请关注PHP中文网其他相关文章!